
「PEGASUS」文章要約に特化した自然言語処理モデル登場!
3つの要点
✔️ 文章要約タスクに特化した事前学習モデルであるPEGASUSが登場
✔️Gap Sentence Generation(GSG)を導入
✔️12の文章要約タスクで高性能、少ない学習データで既存モデルを超える
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
written by Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu
(Submitted on 18 Dec 2019)
subjects : Computation and Language (cs.CL)
はじめに
Transformerを用いた事前学習モデルには、BERT、XLNet、RoBERTa、ALBERTなどがあります。これらのモデルは、転移学習により様々なタスクで高い性能を発揮でき、その汎用性から研究が進んでいます。しかし文章要約は、こういった事前学習モデルの評価に用いられるタスクと比べて、難しいタスクとなります。
自然言語処理モデルの評価に多く用いられるベンチマークとして、「GLUE」「SQuAD」「SWAG」「RACE」などが挙げられます。これら主要なベンチマークは、文章要約タスクを含んでいません。そのため、はじめに挙げたような主な事前学習モデルをそのまま文章要約タスクに適用しても、高い性能が得られる保証はありません。
文章要約タスクに用いることのできる事前学習モデルとして、T5やBARTなどが存在します。これらのモデルは、文章要約に限らず多くのベンチマークにおいて高い性能を発揮しています。
本論文で提案されたPEGASUSは、文章要約に特化した事前学習モデルとなります。PEGASUSは文章要約における12のベンチマークで最高性能を発揮し、そのうち6のベンチマークでは、1000程度のデータを学習させた時点で、既存の最高性能を誇るモデルを超えた性能を発揮しました。
PEGASUSとは
本論文で提案されたPEGASUSは、Pretraining with Extracted Gap-sentences for Abstractive SUmmarization Sequence-to-sequence modelsの略称となります。名称にも含まれていますが、このモデルにおける最大の特徴はGap Sentences Generation(GSG)という新たな学習タスクです。それ以外の部分はBERTと同様で、モデルの構造自体に特殊な点は含まれていません。
Gap Sentences Generation(GSG)
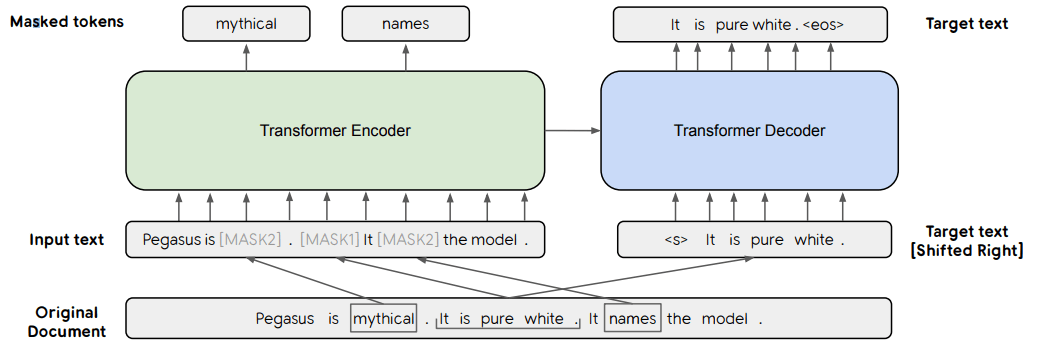
図1.PEGASUS概要。MASK1はGSGにより置き換えられた部分、MASK2はMLMにより置き換えられた部分を指す。
PEGASUSにおいてGSGが用いられているのは、ある一つの仮定に基づいています。即ち、事前学習に用いる学習方式が転移学習により適用するタスクと似ていればいるほど、より高速かつ高い性能を発揮できる、というものです。この仮説に基づけば、文章要約に適用する事前学習モデルは、文章要約とよく似た学習方式を用いるべき、という結論が得られます。
BERTを始めとする事前学習モデルでは、MLM(Masked Language Model)という学習方式を用いる場合がほとんどです。例えばBERTの場合、入力文章のうち15%のトークンをランダムに選択します。選ばれたうちの80%はMASKトークンに、10%はランダムなトークンに、残り10%は変化させず、こうして置き換えられた入力文章をもとに、本来の入力文章を予測するように学習を行います。
しかし前述の仮説に基づけば、このMLMを文章要約タスクに用いるのは適切とは言えません。MLMは入力文章からランダムに選ばれたトークンを予測する学習方式です。それに対し文章要約は、入力文章の中で重要な部分を選択し、かつ一貫性のある文章を生成する必要があるタスクです。
PEGASUSにおいては、MLMを検証段階では導入していましたが、検証ののちにMLMは性能向上に寄与しないと結論づけられ、最終的にMLMは利用されていません。
GSGはMLMと同様、変化させた入力文章をもとに、本来の文章を予測するように学習を行います。特に大きな差異は、以下の二つとなります。
- 置き換えをトークン単位でなく文単位で行う
- 置き換える位置をランダム以外の方法によって決定する
まず一つ目について、GSGにおいては、文をまるごと一つのMASKに置き換え、本来の文を予測する形で行います。そのため、一貫性のある文章を生成する必要のある文章要約タスクにおいて、事前学習方式として用いるに適切なものと言えます。
次に、置き換える文をどのように決定するのか、という問題があります。これについては複数の方式が本論文で提唱されています。本論文ではその全ての方式を検証した後、そのうちの一つを選択しています。
MASK位置決定方式
MASK位置を決定する方式は、本論文で大きく3方式・6種類提案され、それぞれ検証しています。それぞれ見ていきましょう。

図2.GSGで置き換える文選択方式。赤色はLead、青色はRandom、緑色はPrincipal(Ind-Orig)により選ばれた文。
- Random:ランダムに文を選択する
- Lead:文章の最初から順に文を選択する
- Principal:文章のうち、重要な文を選択する
はじめの二つは説明通りですが、Principalについては個別に説明が必要でしょう。
第三の方式においては、ROUGE1-F1という指標を用いて文の重要性を評価し、そうして得られた重要度に応じて文を選択します。ROUGEの詳細については省略しますが、簡潔に説明するなら、文章要約において文章を適切に要約できているかを評価するための指標です。
このROUGEを用いる方式では、2✕2のオプションが存在しています。はじめの2つのオプションについて見ていきましょう。
- Ind:入力文章のうち、一つの文とそれ以外全ての間でROUGEスコアを求め、スコアが大きいものから順に文を選択する
- Seq:入力文章のうち、これまでに選択された文+一つの文とそれら以外の全ての間でROUGEスコアを求め、スコアが大きいものから順に文を選択する
残りの2つのオプションは、ROUGEスコアを求める際において重複する部分があった時、それらを一つとしてみなす(Uniq)か、本来の状態に従い複数とみなすか(Orig)、となります。
これら2✕2のオプションをそれぞれ一つずつ選び、本論文では4つの方式(Ind/Uniq、Ind/Orig、Seq/Uniq、Seq/Orig)それぞれについて検証を行っています。
事前学習用データ
事前学習用のデータとして、C4とHugeNewsの二つをそれぞれ利用しています。C4は350Mのウェブページ(750GB)、HugeNewsは1.5Bの記事(3.5TB)からなるデータセットです。
データの大きさのみを見るとHugeNews一択と思われるかもしれませんが、実際にはそれぞれ、文章要約タスクによって向き不向きが異なります。
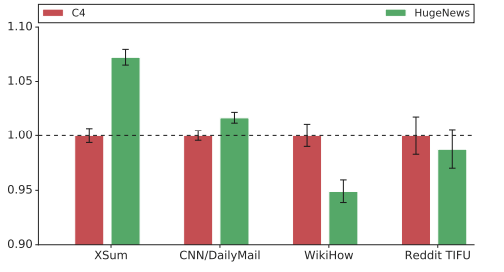
図3.C4、HugeNewsの比較。適用するタスクによって優劣が異なる。
結果
はじめに、GSGの方式決定のため、パラメータ数223MのPEGASUSBASEを用いて検証を行っています。この検証段階では、GSGに加えて通常のMLMを用いた場合も含んでいます。
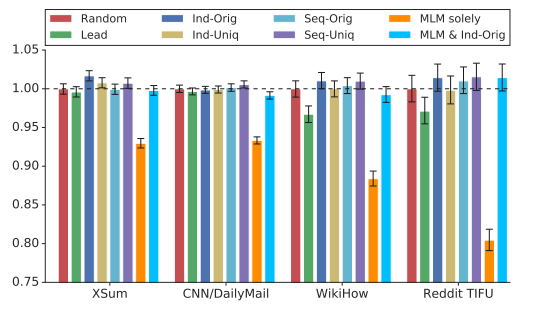
図4.各GSGオプションの比較
検証の結果として、MLMによる性能向上はほぼ見られないこと、前述したGSG方式のうち、Ind/Orig方式が高い性能を誇ることがわかりました。
次にパラメータ数568MのPEGASUSLARGEを事前学習させ、12の文章要約タスクに適用した場合が以下の通りとなります。
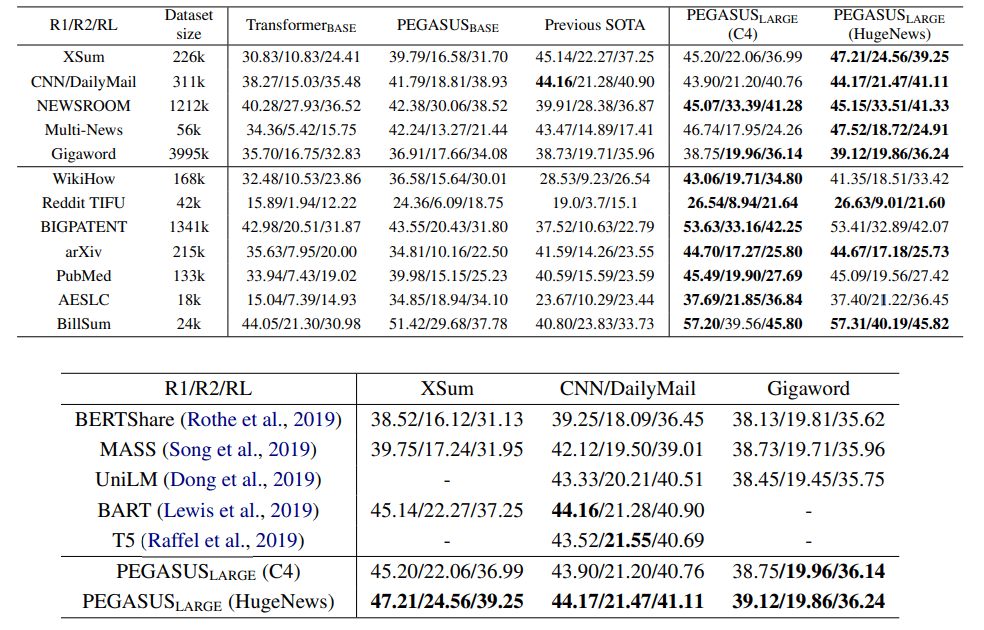
図5.12の文章要約タスクと既存モデルとの比較
この通り、12のベンチマーク全てにおいて、PEGASUSが最高性能を発揮しました。
学習データが少ない場合
PEGASUSの最大の特徴は、文章要約に似た事前学習方式であるGSGです。その結果として、学習データが少ない場合においても、非常に高い性能を発揮することができます。
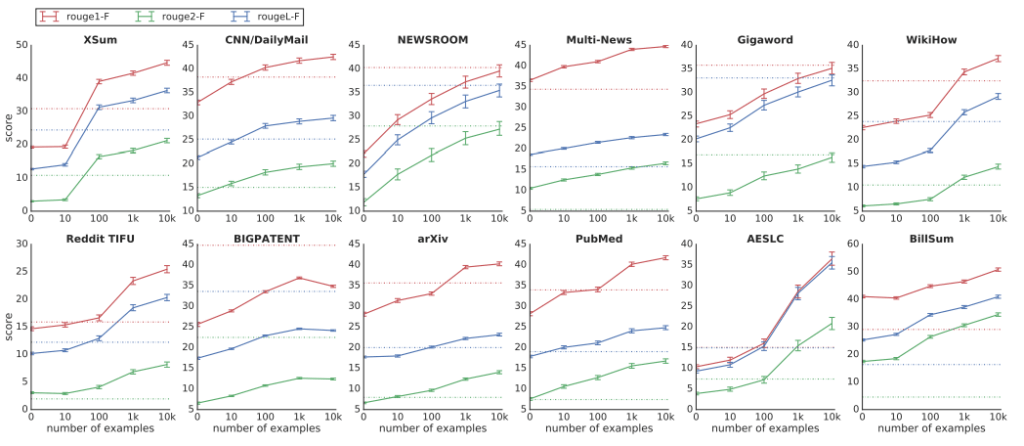
図6.学習データ量とスコア
12のベンチマークのうち実に6つのベンチマークにおいて、たった1000個のデータを学習させた段階で既存の最高性能を超えています。文章要約タスクは、他の自然言語処理タスクと比較しても特に学習用データを準備することが困難です。そのため、少ない学習データで高い性能を誇ることは、他のタスクと比較しても非常に大きなメリットとなります。
最後に
PEGASUSは文章要約に特化したモデルであり、学習データが少ない場合でも高い性能を誇る、非常なモデルです。しかしそれゆえに、他の事前学習モデルと比較すると、汎用性という観点からは劣ります。
本論文における最も重要な指摘は、PEGASUSそれ自体より、その前提となる仮説にあるとも考えられます。つまり、事前学習に用いる学習方式が転移学習により適用するタスクと似ていればいるほど、より高速かつ高い性能を発揮できる、という点です。
PEGASUSは文章要約によく似た事前学習方式であるGSGを用いて高い性能を発揮し、まさにこの仮説を支持する結果が得られました。もしこの仮説が正しければ、何らかの言語処理タスクにおいて高い性能を発揮するには、そのタスクに応じた事前学習方式を用いるべきである、といえます。
既存のMLMと異なる手法を用いて高い性能を発揮したこと、事前学習モデルの性能を向上させる上で、今後の方針となりうる仮説を提唱したことは、PEGASUSというモデル以上の価値を持っているでしょう。





この記事に関するカテゴリー






