機械学習とBCIを用いて、声道の動きをシミュレートする仮想声道が開発される
英科学誌ネイチャーに、機械学習とBCIを用いて、声道の動きをシミュレートする仮想声道の論文が発表されました。声道の物理的運動をシミュレートすることよって合成音声を生成するという新しいBCIが提案されています。
【参照】Speech synthesis from neural decoding of spoken sentences
外傷や脳損傷などが原因で話せない人が、再び話せるようになる日が来るかもしれません。
UCサンフランシスコ校が、人の思考を直接解読し言葉にする革新的な脳内埋め込み型機器(インプラント)を開発したと25日に発表しています。
この研究は、人間の脳の言語中枢が唇、顎、舌、声道など構成要素の動きをどのようにコントロールし、音声を作り出すかを調査したという過去の研究に基づいたものだそう。 過去の調査により、脳は音声の音響特性を直接表すのではなく、むしろ、発話中の口と喉の動きを調整するのに必要な指示を表していることが分かっていました。
一方、音声を脳波の情報から再合成するという試みはこれまでにもいくつかありましたが、これらのアプローチは脳の活動から音響特性を直接解読しようとするものでした。
今回の論文では、脳の活動を使って声道の物理的運動(喉頭、咽頭、口腔、鼻腔など)の動きをシミュレートし制御することによって合成音声を生成するBCI(ブレインマシンインタフェース)を提案しています。
面白いのは、脳からの音響特性を直接解析するのではなく 脳が発する信号――声道のどの部分の筋肉をどのように動かすか(物理的な運動)――を詳細に測定し、これに基づいた仮想声道BCIを構築しているところです。
気になる仮想声道の中身とは?
実験は、他の治療のために既に脳に大きな電極が埋め込まれていた被験者に対して行われました。被験者たちに、数百の文を大声で読んでもらい、同時に電極が捉えた信号を詳細に記録します。

図1、脳に装着された電極
すると、言葉を考えて並べようとした瞬間から、最終的に信号が運動野から舌や口の筋肉に送られるまでの間に起きる脳のアクティビティ(大脳皮質領域で起きるもの)に、ある種のパターンがあることに気づいたそう。
この情報を基に、チームはどの筋肉と動きがいつ必要になるかを判断することができ、これを使ってリアルな仮想発声モデルを構築しました。この仮想モデルは二つのニューラルネットワークに基づく機械学習アルゴリズムから構成されています。一つは発声中に生成された連続的な神経活動のパターンを仮想声道の動きに変換するデコードであり(図1a-b参照)、もう一つはこれらの声道の動きを参加者の声に変換するシンセサイザーです(図1c− d)。
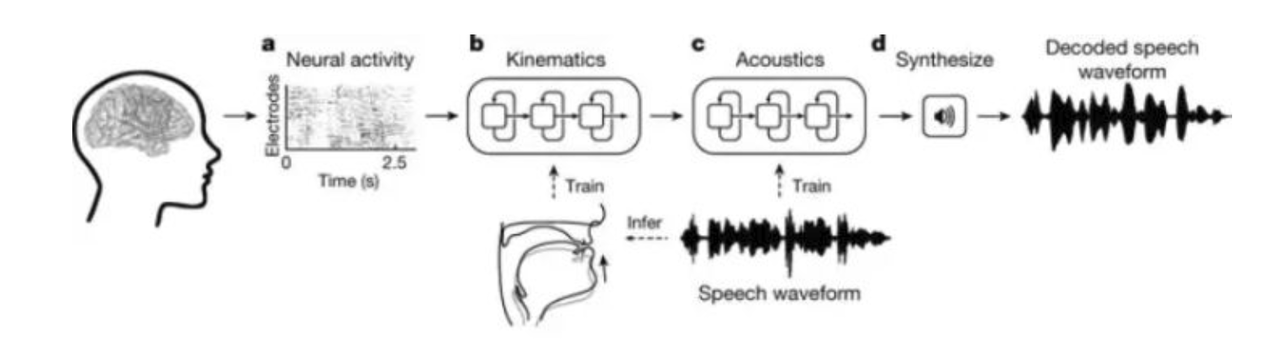
図1
この機械学習システムを利用して、セッション中に検出された脳のアクティビティをその仮想モデルに写像します。すなわち本質的には脳の記録を使って、口の動きの記録を制御することができたということです。このシステムが理解しているのは音ではなく、脳が顔の筋肉に対して送っている具体的な命令です。つまりその命令による動きが生み出すであろう言葉を予測してるともいえます。
合成発話された文章は、不明瞭な部分も少しは見られましたが、被験者が読み上げた文章に非常に近く、大半の単語は明確に理解できたと伝えられています。
今回の実験は発話が可能な人のみを対象として実施されましたが、被験者が声を出さずに口の動きだけで文章を読んでも、発話の合成は可能だということも分かりました。
以下はデモ動画になります



この記事に関するカテゴリー