さらに出た!また(M)DETR!マルチモーダル推論モデルの革新的なパラダイム
3つの要点
✔️ End-to-Endのテキスト制御物体検出モデルの提案
✔️ マルチモーダルタスクにおいてEnd-to-Endでの検出達成
✔️ ダウンストリームタスクでも性能発揮
MDETR -- Modulated Detection for End-to-End Multi-Modal Understanding
written by Aishwarya Kamath, Mannat Singh, Yann LeCun, Ishan Misra, Gabriel Synnaeve, Nicolas Carion
(Submitted on 26 Apr 2021)
Comments: Accepted by ICCV2021 oral
Subjects: Computer Vision and Pattern Recognition (cs.CV); Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、またはそれを参考に作成したものを使用しております。
はじめに
現在多くの画像とテキストを融合したマルチモーダル推論モデルでは、事前に学習した物体検出器を用いて、画像から関心領域を抽出する工程が存在します。当たり前のように感じるかもしれませんが、これって考えてみると「モデルモーダル推論は事前学習された物体検出器に依存している」ことになります。例えば、”犬”というクエリを入力すると画像から犬のみを検出して欲しいにも関わらず、事前学習された物体検出器が車を事前学習しているとすると、いくらテキストのクエリで犬に関する情報を入れても検出できないということです。これが現在マルチモーダル推論モデルの性能を阻害している大きな要因です。
そこで今回ご紹介する論文はキャプションや質問のようなテキストクエリを条件として、画像内の物体を検出するend-to-endの変調検出器MDETRになります。(この論文はヤン・ルカン先生も共著で書かれています。)
transformer構造に基づき、モデルの初期段階で両モーダルの情報を融合し、テキストと画像の共同推論を行うことで、画像内の物体を検出します。 ここからさらに凄く、最終的には検出タスクと複数のダウンストリームタスクの両方でSOTA性能を達成しています。説明に移る前にこのMDETRのすごい性能を見てみましょう!MDETRは自由形式のテキストから物体を検出し、未知のカテゴリーと属性の組み合わせに一般化することができます!そのため、"A pink elephant(ピンク色の象)"では、学習時にピンクやブルーの象を見ていないにもかかわらず、MDETRはピンク色の象を正しく検出できています!

DETR
MDETRは、BackboneとTransformer Encoder-Decoderで構成されるend-to-endの物体検出モデルであるDETRモデルに基づいています(DETRの構造を下図に示す)。DETRについてはAI-SCHOLARにかなりの詳細記事が存在しますので気になる方はそちらをご確認ください!→"ついに出た!本当にDETR! 物体検出の革新的なパラダイム"
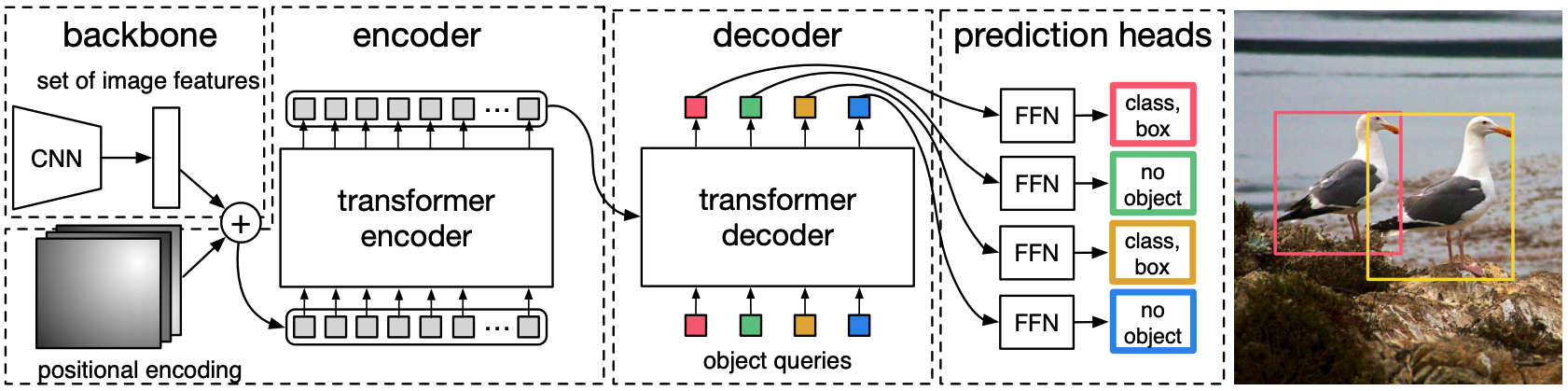
DETRはまず、画像をCNN backboneに通して視覚的特徴を抽出します。その視覚的特徴をフラット化して位置エンコードを加え、Transformer Encoderに入力します。 object queriesは、モデルが物体を検出するために必要なスロットと考えることができます。
これらのobject queriesがデコーダに与えられた後、クロスアテンション層がエンコードされた画像特徴と非公式に相互作用し、各クエリに対する出力埋め込みを予測するために使用されます。最後に、各クエリの出力エンベッディングは、共有パラメータを持つFFNを介して、box座標とカテゴリラベルの予測に使用されます。
ただ各クエリは1つのboxの予測を使用しているため、あらかじめ設定されたクエリの数は、画像内のオブジェクトの数の上限となります。 画像内の物体数は、クエリ数よりも少ない可能性が大きいため、著者らは"no object"に対応する追加のクラスラベルを使用しています。
MDETR
MDETRの構造を下図に示します。
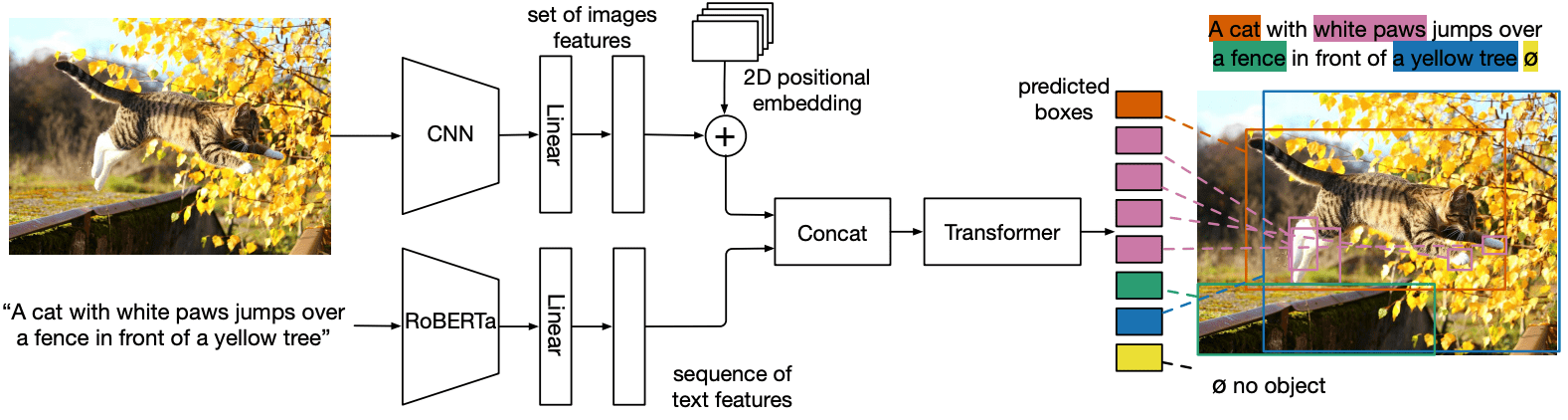
MDETRはCNN backboneに通して視覚的特徴を抽出した後、特徴をフラット化します。そのフラット化されたベクトルに2次元位置エンベッディングを加えることで、空間情報を追加しています。ここまではほぼDETRと一緒で、差異はここからです。次に言語モーダルについては、事前に学習された変換言語モデル(RoBERTa)を用いて、入力と同じサイズの隠れベクトルのシーケンスを生成します。その後画像とテキストの両方の特徴に、モダリティ依存の線形射影を適用して、共通の埋め込み空間に射影します。そして、これらの特徴ベクトルをシーケンス次元で連結し、画像とテキストの特徴の単一のシーケンスを生成しています。
この一連の特徴は、まずクロス・エンコーダーに入力されて処理されます。その後DETRと同様に、ターゲット・フレームを予測するためのオブジェクト・クエリが設定されます。
なので、上図のテキストモーダルのところをDETRに融合したと言った感じになります。
学習
学習に関しては、DETRの損失関数に加えて、著者らは画像とテキストのアライメントのための2つの追加損失を提案しています。
- 1パラメータ不要のアライメント損失であるソフトトークン予測損失
- アライメントされたクエリとトークンの類似性を近似するために使用されるパラメータ化された損失関数であるテキスト-クエリ対比アライメント損失
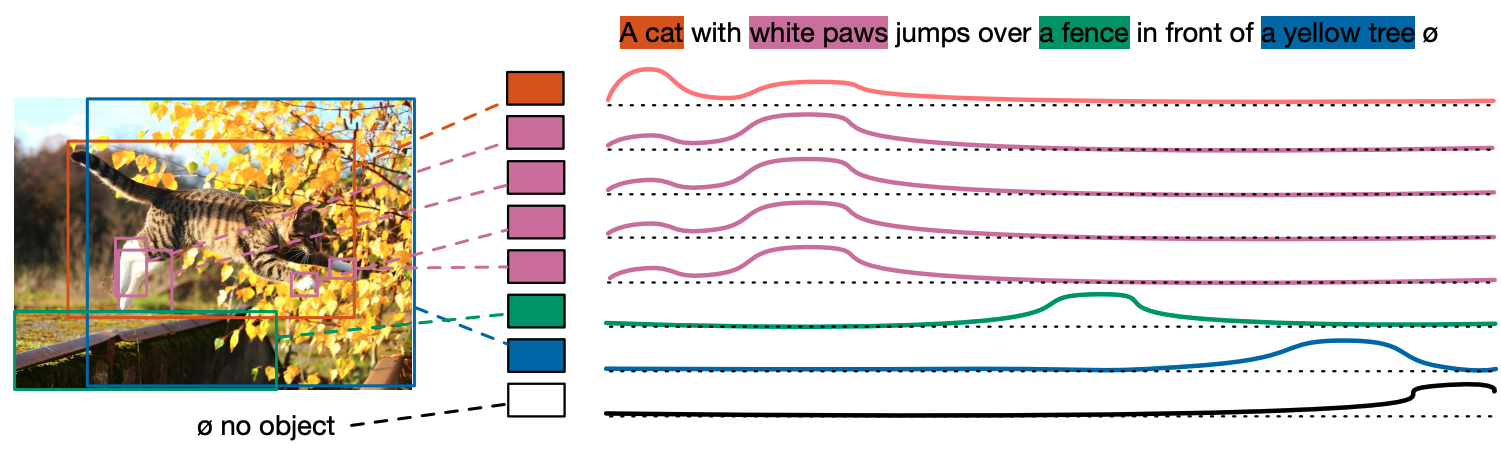
ソフトトークン予測
従来の物体検出とは異なり、入力文に登場する物体にのみ反応する必要があり、まず、トークンの最大数を256に設定し、各予測ボックスのマッチングGTについて、すべてのトークンの位置にあたる分布を予測するようにモデルを学習します。 下図は、猫の予測ボックスが最初の2つの単語の分布を予測するように学習された例です。ソフトトークンという名前からもわかるように、今回のトークンの関係性はテキストと画像が多数対多数の関係であったり、テキスト中の複数の単語が画像中の同じ物体に対応したり、逆に複数の物体が同じテキストに対応したりすることがあるため、ハードなトークン予測が合わないだろうという考えから考案されているのだと思います。
対比アライメント
ソフトトークン予測損失は物体とテキストの位置を合わせるために使用され、対比アライメント損失は視覚とテキストの埋め込み特徴表現のアライメントを強化するために使用され、アライメントされた視覚と言語の特徴表現が特徴空間において相対的に近くなるようにしています。この損失関数は、位置に作用するのではなく、特徴レベルに直接作用し、対応するサンプル間の類似性を向上させています。この損失関数は、InfoNCEを参考にしており、以下の式で表されています。
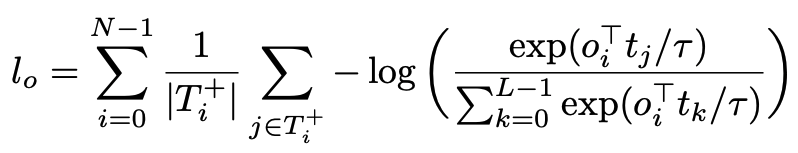
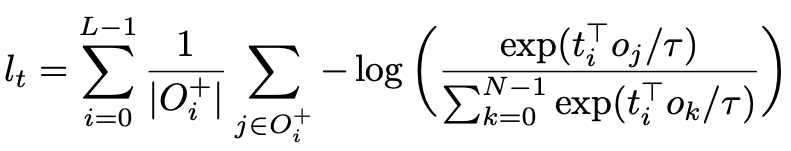
ここまでの説明でわかるように基本的にはDETRのend-to-end物体検出能力が、マルチモーダルの制限を突破できるため、いかにして、DETRをマルチモーダルに拡張するかについて考えられた手法です。そのためのアーキテクチャとマルチモーダル特有の関係性ように追加の損失関数を用意するなど、かなりシンプルで直感的にできています。なので、DETRは確実におさえておいて下さい("ついに出た!本当にDETR! 物体検出の革新的なパラダイム")。原著でも実験まではかなりシンプルな論文でわかりやすいです。そして、実験の項目がかなり多く、ICCV2021 oralに採択されたのも納得です。
実験
CLEVRデータセットの合成データを用いた実験と実世界の画像を用いた実験を行っています。
CLEVR
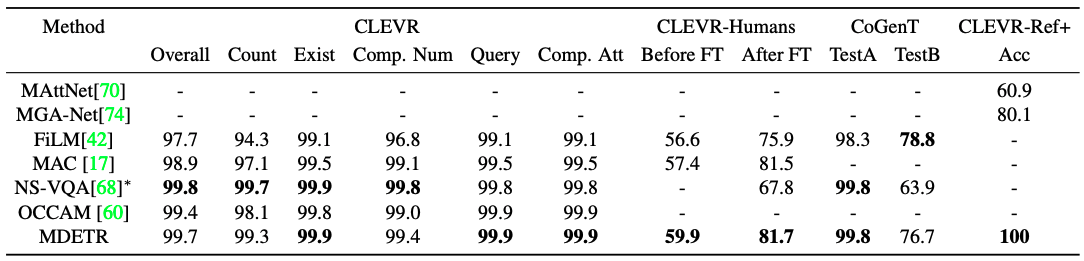
CLEVRは、制御された環境でマルチモーダルモデルを評価するために設計された合成データセットになります。主な課題は、最大20段階の推論を含む質問を理解し、その中のキーフレーズを画像内の正しい物体に合わせることです。CLEVRに対するいくつかの成功したアプローチとは異なり、MDETRはこのような複雑な推論タスクに対処するための特別な帰納的バイアスを組み込んでいないのが特徴的です。比較的簡単な定式化にもかかわらず、MDETRが質問応答タスクにおいて最先端のモデルと競合することを示しています。結果を表に示します。
NS-VQAと近い性能を示しています。外部からの信号を用いない手法の性能を明らかに上回っています。さらにCLEVR-Humansは、CLEVR画像に対して人間が作成した質問のデータセットです。このデータセットでは、新しい語彙などに対するモデルの堅牢性をテストしています。CoGenTは、構成的一般化のテストです。評価プロトコルは、球体はどの色でもよいが、立方体は灰色、青、茶、黄のいずれか、円筒は赤、緑、紫、シアンのいずれかである集合Aでの学習からなっています。次に、立方体と円柱の色と形の組み合わせが逆になっている分割Bに対して、ゼロショットで評価を行います。他のモデルと同様に、大きな一般化ギャップが見られます。これは、モデルが形状と色の間に強いスプリアスバイアスを学習していると考えられます。
最後に、CLEVR 画像を用いた参照表現理解データセットであるCLEVR-REF+で本モデルを評価した。各オブジェクトクエリに対して、クエリが参照されているオブジェクトに対応しているかどうかを予測するために、追加のバイナリヘッドを学習します。ユニークなオブジェクト表現のサブセットで精度を評価し、トップランクのボックスが少なくとも0.5のIoUを持っているかどうかで測定しています。MDETRは検証セットの各例で有効なボックスを正しく1位にランク付けし、精度は100%となり、先行研究を大きく上回る結果となっています。
実世界の画像

「The person in the grey shirt with a watch on the wrist. the other person wearing a blue sweater.the third person in a gray coat and scarf」という文章に対して、属性の異なる3人の人物を正確に検出することができています。かなり驚きの精度ですね。
ダウンストリーム・タスク
4つのダウンストリーム・タスク(フレーズ・グラウンディング・参照表現の理解・セグメンテーション・視覚的質問応答)についてもMDETRを評価しています。かなりの実験を行っているので、結果だけ列挙していきますので気になる人は必ず、原著をご確認ください。
フレーズ・グラウンディング
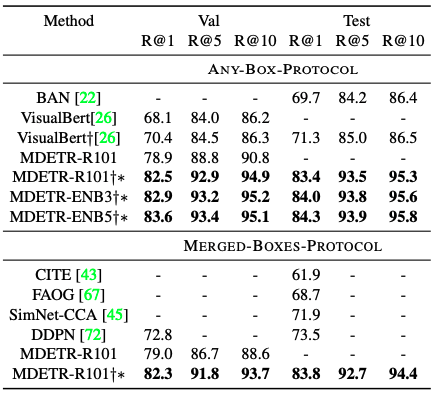
相互に関連する可能性のある1つまたは複数のフレーズが与えられた場合、各フレーズのバウンディングボックスのセットを提供することが課題となっています。このタスクには、Flickr30k entities datasetを使用し、train/val/testの分割を行い、Recall@kの観点から性能を評価されます。テストセットの各文に対して、100個のバウンディングボックスを予測し、ソフトトークンアライメント予測を用いて、フレーズに対応するトークンの位置に与えられたスコアに応じてボックスをランク付けしています。テキストを条件とした検出モデルと変換器を用いた視覚言語の事前学習モデル2種類のアプローチによる既存手法と比較しています。他の手法と比較しても圧倒的な精度を発揮していることがわかります。
参照表現の理解
画像とテキストの表現が与えられたときに参照されている物体の周囲のバウンディングボックスを返すことによって、そのオブジェクトをローカライズするタスクです。基本的には従来は事前に学習された物体検出器を用いて得られた画像に関連する事前抽出されたバウンディングボックスのセットをランク付けするというアプローチをとっています。
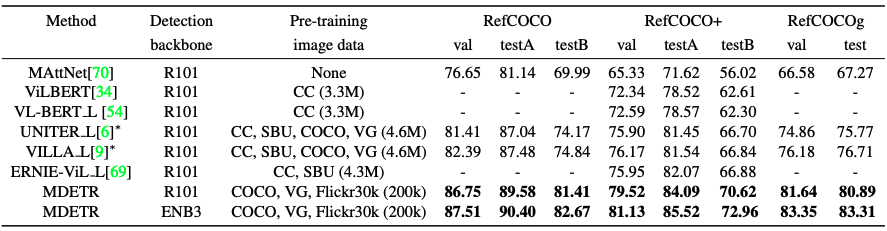
しかし、今回の論文では、さらに困難な課題を解決しています。どういうことかというと参照表現と関連画像が与えられたときに、バウンディングボックスを直接予測するようにモデルを学習しています。このタスクのために、RefCOCO, RefCOCO+, RefCOCOgと呼ばれる3つの確立されたデータセットを使用しています。
MDETRに若干の変更があります。例えば、「The woman wearing a blue dress standing next to the rose bush.」というキャプションが与えられた場合、MDETRはthe woman, the blue dress, the rose bushなど、参照されるすべてのオブジェクトに対してボックスを予測するように学習されています。しかし、参照表現の場合は、表現全体で参照されている女性を意味する1つのバウンディング・ボックスのみを返すように学習する必要があって、そのため、過剰なバウンディング・ボックスを返すことになってしまいます。そのため、タスクに特化したデータセットで5回の学習を行い、モデルのfine-tuningを行います。これもまた圧倒的な精度改善がされています。
セグメンテーション
DETRと同様に、PhraseCutデータセットのセグメンテーションタスクで学習することで、セグメンテーションを行うように拡張できることを示しています。ここでもかなりの精度改善ができています。
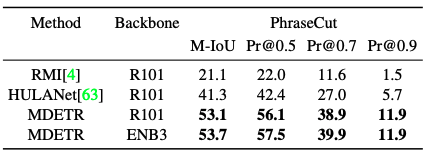
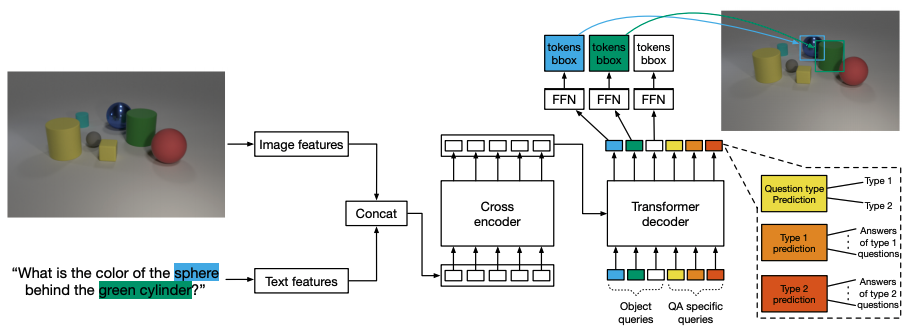
視覚的質問応答
GQAデータセットで事前に学習させたモデルをfine-tuningすることにより、変調検出がマルチモーダル推論に有用なコンポーネントであるという仮説を評価しています。モデルのアーキテクチャを下図に示します。検出に使用する100個のクエリとは別に、質問のタイプに特化した追加のオブジェクト・クエリと、質問のタイプを予測するために使用する1つのクエリを使用しています。
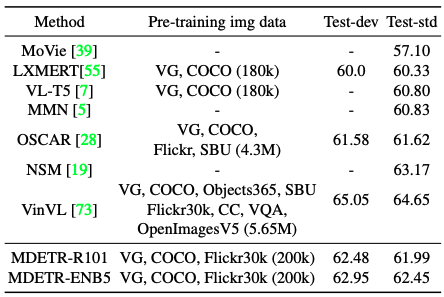
MDETRをResnet-101 backboneで使用したところ、同程度のデータ量を使用するLXMERTやVL-T5を上回っただけでなく、事前学習でより多くのデータを使用するOSCARも上回る結果となっています。
Few-shot transfer for long-tailed detection
画像分類のためのゼロショット転送に関するCLIPに触発されて、事前学習されたMDETRモデルから与えられたラベルセット上で有用な検出器構築を目標に実験を行っています。CLIPとは異なり、事前学習データセットが全てのターゲットクラスの表現を含んでいることを保証していません。これにより、モデルは与えられたテキストに対して常にボックスを予測するようになっています。そのため真のゼロショット転送設定での評価ができないため、代わりに利用可能なラベル付きデータの一部でモデルを学習する数ショット設定を行います。LVISデータセットを用いて実験を行います。LVISデータセットは、1.2kカテゴリの大規模な語彙を持つ検出データセットであり、ロングテールでトレーニングサンプルが非常に少ないため、挑戦的な課題です。
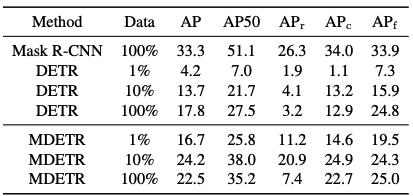
2つのベースラインと比較します。1つ目はLVISの全トレーニングセットでのみトレーニングされたMask-RCNです。もう一つは、DETRモデルをMSCOで事前学習した後、LVISトレーニングセットの様々なサブセットでfine-tuningしたものです。
その結果を表に示します。MDETRは1クラスあたり1サンプルという少ないサンプル数でも、テキストの事前学習を活用し、少数カテゴリーでもfine-tuningされたDETRを上回る結果となりました。しかし、トレーニングセット全体のfine-tuningを行った場合、スモールオブジェクトのパフォーマンスは、10%のデータでは20.9APだったのが、100%では7.5APと大幅に低下しているところが不思議です。
![]() まとめ
まとめ
マルチモーダル推論モデルのEnd-to-endされた検出器であるMDETRが提案されました。MDETRは、様々なデータセットを用いたマルチモーダル理解タスクにおいて高い性能を発揮し、数ショット検出や視覚的質問応答など、他のダウンストリームタスクにおいてもその性能を発揮しました。
ここ最近のAplhafold2もそうですが、この論文も見ているとDETRに関するリサーチし、マルチモーダル周辺リサーチ、さらにはself-supervised learningあたりの知見(ここは多分ヤン・ルカンさんの知見)も集まっていることからかなりのリサーチに裏付けられた論文だと感じました。





この記事に関するカテゴリー





