深層学習×マルチモーダル。マルチモーダル学習で未来が広がる
はじめに
最近のディープラーニングの1つのトレンドは、画像認識の分野において、CNNの多層化です。これにより少ないパラメータで複雑な非線形性を持たせることができます。一般的な画像認識タスクはかなりいい成績を出してます。
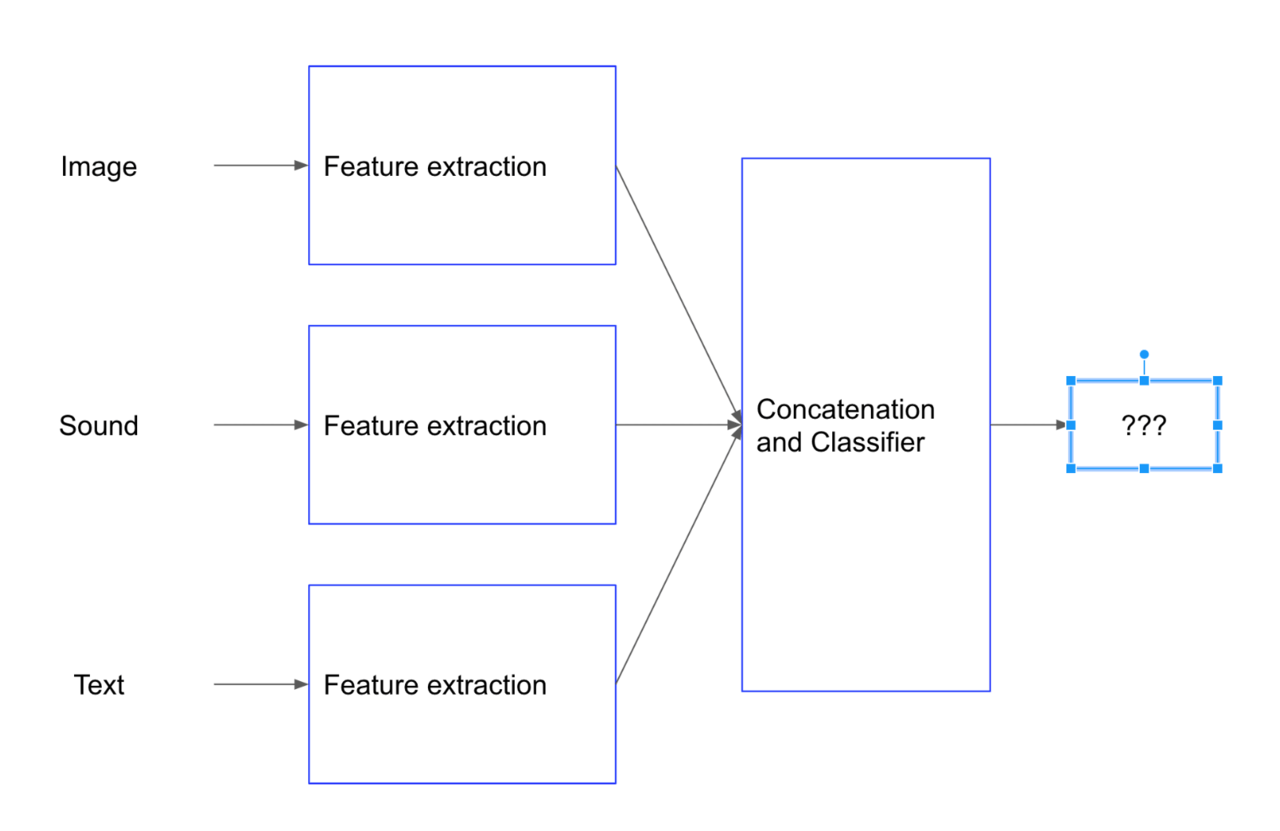
一方で、画像と他のデータを組み合わせた研究が近年盛んですが、こういった機械学習においていくつかの異なる情報を使うことをマルチモーダル学習と呼びます。
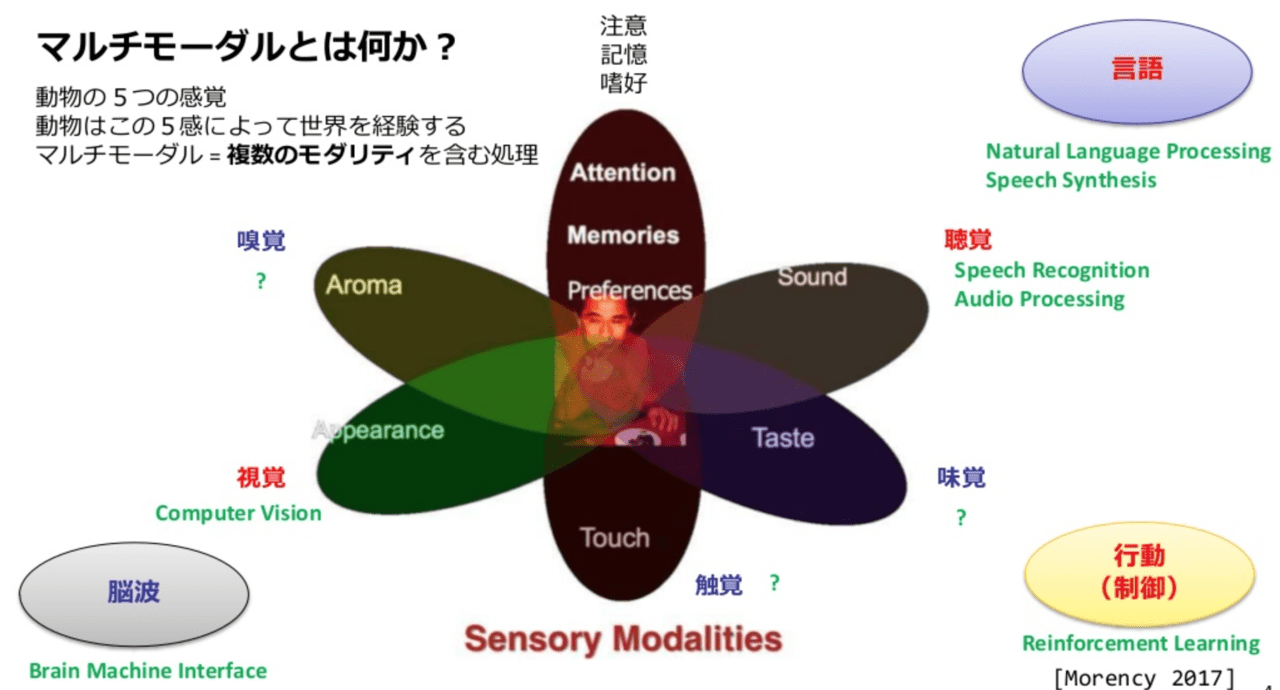
私たちの住む現実世界では、情報は様々なモーダル情報で表現されています。
例えばYoutubeのような動画の場合でも、動画、テキスト、音声、再生回数、投稿日…など様々なデータで構成されています。
人間はこれら複数のモーダル情報を 五感から取り入れることで、単一のモーダル情報よりも確実で抽象度の高い情報処理うことができます。これらを模倣して機械学習においても同様に複数種類のデータから学習して、統合的に処理をしようというのがマルチモーダル学習になります。
現在のAI技術は、人間に備わっている5つの感覚の中からどれか1つの感覚を対象にするものがほとんどですが、モーダルな情報を扱うこの研究は、人間の感覚の学習過程を模倣することにおいては正しい方向を示すものといえるでしょう。
深層学習が登場する以前はそれぞれのモダリティに関する研究分野が独自に進展してきましたが、ディープラーニングの発展により、近年、分野間の障壁が薄くなってきました。
続きを読むには
(3315文字画像10枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






