ターゲットをbounding boxではなくポイントとして扱う新手法CenterNet
3つの要点
✔️ bounding boxの中心点として物体を検出
✔️ タスクに合わせてbounding boxの大きさや3D location, orientation, ポーズなども推定可能
✔️ 精度と速度の両方でSOTAを獲得
Objects as Points
written by Xingyi Zhou, Dequan Wang, Philipp Krähenbühl
(Submitted on 16 Apr 2019 (v1), last revised 25 Apr 2019 (this version, v2)])
Comments: Published by arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
はじめに
現在の物体検出は、対象物を囲むbounding boxと呼ばれる対象物を囲む四角い枠を通して各対象物を表し、各bounding boxから、分類器が、画像内容が特定のオブジェクトまたは背景であるかどうかを決定します。

現在最も成功していると言われるこの方法ですが、検出器は、潜在的な物体位置の網羅的なリストを列挙してから、それぞれを分類する必要があり、無駄が多く非効率的といえます。また追加の後処理タスクも必要になってきます。
この論文では、はるかに単純で効率的な方法として、オブジェクトをbounding boxの中心の1点で表すCenterNetと呼ばれるモデルを提案しています。つまり、CenterNetは、グループ化や後処理を必要とせずに、オブジェクトごとに単一の中心点を抽出するだけです。
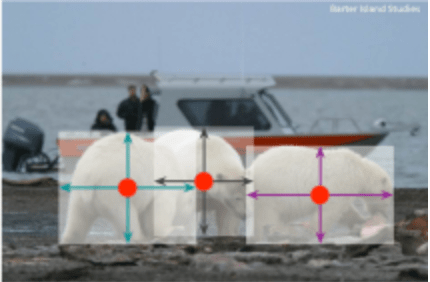
お気付きの方もいると思いますが、この論文のハイライトは、その精度がどれほど高いか(もちろん、精度はかなり良い)ではなく、「ターゲットをポイントとして見る」という考えを提唱していることです。このアイデアを適用したモデルは、3Dターゲット検出、ヒューマンポーズ推定などの多くのタスクにも使用できます。
CenterNet

バウンディングボックスの中心点をキーポイント推定で求め、中心点の特徴から、サイズ、3D座標、向き、ポーズなどを回帰します。
具体的には、入力画像を、ヒートマップを生成する畳込みネットワークに供給し、このヒートマップの各ピーク(確率の最大点)から、オブジェクトの中心点を求めます(周辺8個の値より大きいとなる場所を物体の中心点とする)。他のターゲット検出方法で必要とされる後処理操作やグループ化プロセスいらずでシンプルな構造になっています。
このような中心点ベースのアプローチは、対応するbounding boxベースの検出器と比べ、エンドツーエンドでシンプルな構造になっているので高速です。
さらに、CenterNetはターゲット検出におけるスピードと精度の間で最良のトレードオフを達成しています(最大142 FPS、最大45.1%AP)。また、3Dターゲット検出、ヒューマンポーズ推定タスクにも使用でき、良い結果を得ています。
 AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
そう言った人材がいることもAI開発のある意味1つの実績になります。
AI-SCHOLARを読んでいる読者は、今こそE資格を取得し、早めに自分のスキルアップを狙っていきましょう!
企業においてはある調査で、AI開発に成功している企業は社員全体のAIに対する知識レベルが高いそうです。
AI開発やAIを用いる社会になる今こそ企業は社員のAIレベルをあげましょう!



この記事に関するカテゴリー






