写真に写っている人を3Dで出力!新しいフレームワークDenseBodyとは
今回紹介するのは、先月発表された3D Human Pose (3D人体再構成)の新しい論文です。単一RGB画像から、中間表現なしで姿勢と形状(メッシュまで)を推定しており、さらに3D人体再構成技術におけるスピードと精度の二重のブレークスルーを達成しています。
論文:DenseBody: Directly Regressing Dense 3D Human Pose and Shape From a
Single Color Image
必要なのは、たった一枚の1つの角度の写真だけ

跳ね上がった少女のワンシーンを切り取った平らな写真です。
さて、この写真を特定のプログラムに入力すると次のようになります。
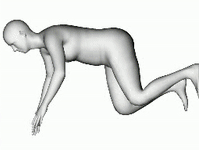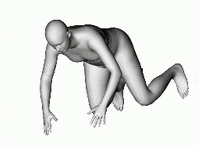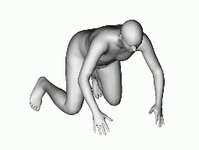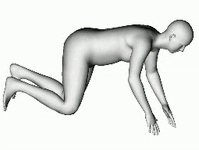
あらゆる角度から見える3D立体画像は、写真から飛び出でくるようなリアリティがあります。
過去においては、3D人体再構成は、人体の3Dモデルを再構成するために複数のカメラまたは連続的なマルチフレーム画像を必要としました。
しかし、今、D再構築においては、通常のカメラでとったたった一枚の画像だけが必要です。
さらに、動画を入力するとアニメーション化されたムービークリップを生成することもできます。



本稿では、人体の3D奥行き予測に基づく3D表現の新しいセットが提案されています。単一画像(RGB、奥行き情報なし)分析(入力)を通して、人体の3D形状と姿勢が予測(出力)されます。
人体は6万点以上で完全に描かれ、3D人体再構成におけるスピードと精度の二重のブレークスルーを達成しています。モデルはより精巧で、フレームレートは200fpsと非常に高く、リアルタイムの表示制限のために実現できなかったアプリケーションを一つずつ実装することができ、関連するイメージアプリケーションが大いに促進されるこでしょう。
従来の3D表現技術における課題
3D表現には複数の選択肢がありますが、最近のCNNを用いたアプローチでは、主に様々な中間2D表現に頼っていました。これらの方法では、プロセスは2段階に分解され、最初に2D人骨関節点検出、または2Dセグメンテーションのようなある種の中間表現に依存し、次にこれらの中間表現に基づいて3D表現を予測するというものでした。
中間表現での、人体のキーポイント検出技術は、2D関節点検出の形で現れることが多く、これらは、奥行き情報を復元できないため、奥行き感を反映しません。
さらに、ほとんどの従来の3D再構成技術は連続画像シーケンスや多視点画像を必要とし、一般的にハードウェア機器は双眼カメラまたは構造化光カメラを使用する必要があるため、携帯電話などの携帯機器に実装するのはあまり現実的なものではありませんでした。
本提案:DenseBody
本稿では、中間的な表現やタスクなし(エンドツーエンド)で、単一の画像から3Dの人体まで、直接画像を生成することができる効率的な3D人体ポーズ表現が設計されています。中間サブタスクを解決する必要がなくなり、3D推定の複雑さは、2段階から1段階に省略できました。
関節点情報を出力するだけでなく同時に人体の多数のキーとなる表面情報を予測することができ、異なる胴体の深さ情報を反映でき、密な3Dキーポイント検出ができるようになっています。
エンコーダ – デコーダ構造を通過することができる3D人間の形状および姿勢の効率的な表現のためUVマッピングと呼ばれる2D表現を利用しています。

UVマッピングとは
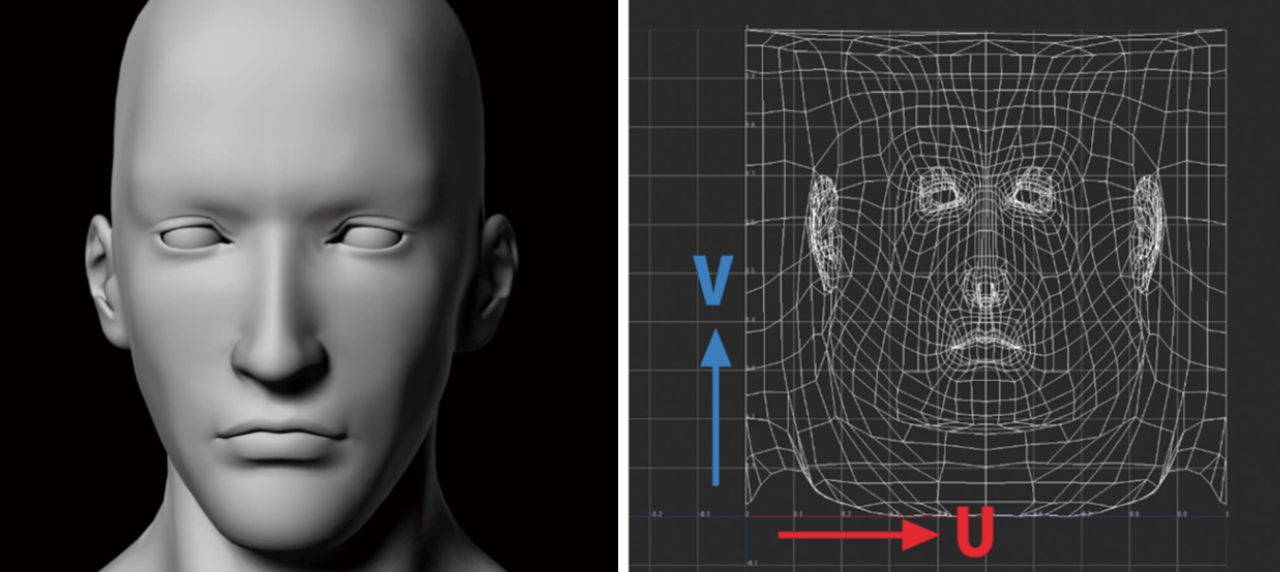
【左】人間の顔の3DCGモデル/【右】UV座標上に展開されたモデル。横方向の軸がU、縦方向の軸がVとなる
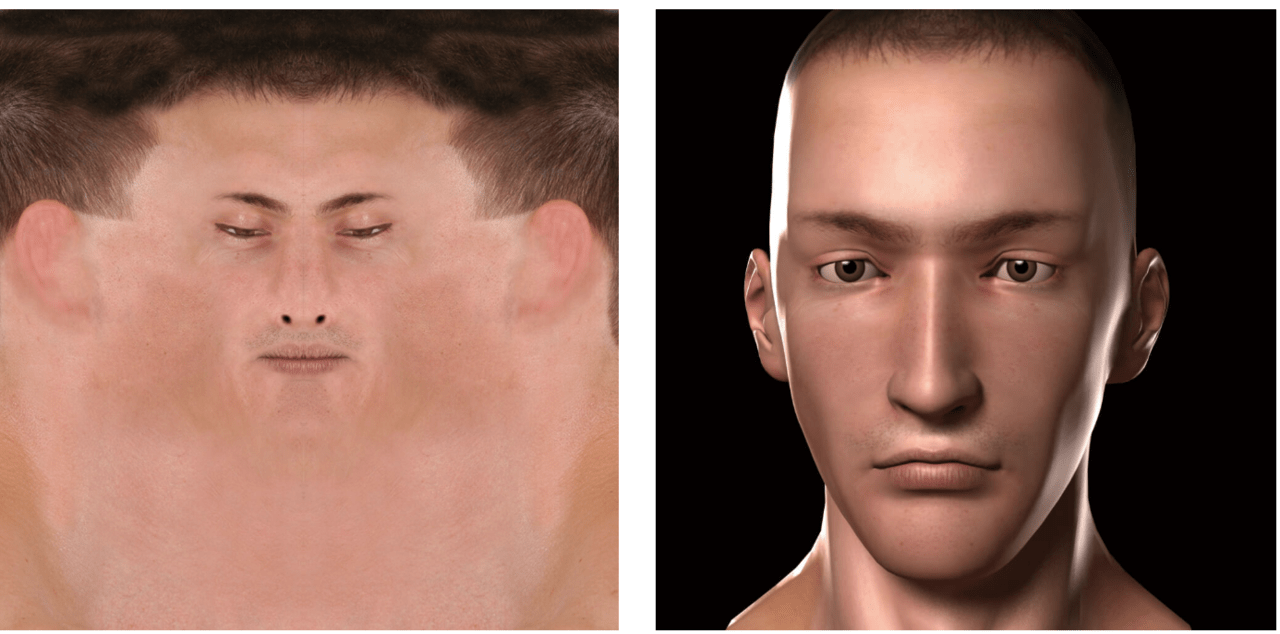
【左】UV座標を基に描かれたテクスチャ/【右】テクスチャをUVマッピングしたモデル
UVマッピングは、平面の画像を不規則な形状のモデルに貼り付けるための方法です。
オブジェクトに含まれるそれぞれの頂点は、X、Y、Zの空間座標を利用して決定されます。UVマップではさらに、マップ上のどこへポイントを配置するかを決定するための、UとVの2つの座標を追加します。これにより、あたかもポイントがそのテクスチャの位置に常に保持されているかのように、画像をオブジェクトに貼り付けることができます。
本論文ではこのUVマッピングを上手く利用し、単一画像(RGB)から身体形状へのUVマッピングを直接学習するフレームワーク(エンコーダ – デコーダアーキテクチャ)を提案しています。非常に速い実行速度(200fps)で、入力RGB画像を3D表現に直接マッピングします。
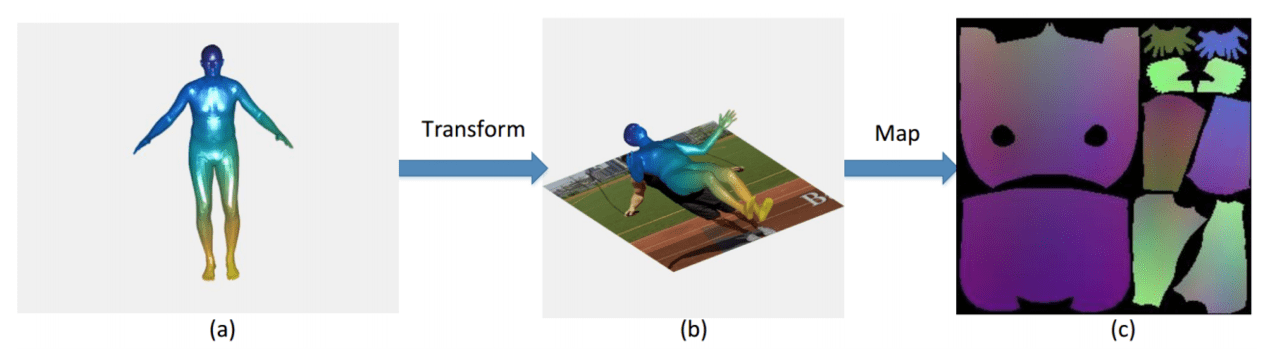
SMPL人体モデルを世界座標系からカメラ座標系に変換し、次に、投影法を使用して3Dモデルに対応するカラー画像と空間的に位置合わせすることで、3D人体モデルが画像平面に投影されたときに2D人体と一致するようにします。人体表面上の各3D頂点(x座標およびy座標)は画像内の点に対応し、z座標はルート点に対する相対深度です。 UVマップでは、頂点のx、y、z座標をr、g、bカラー値として格納します。
評価
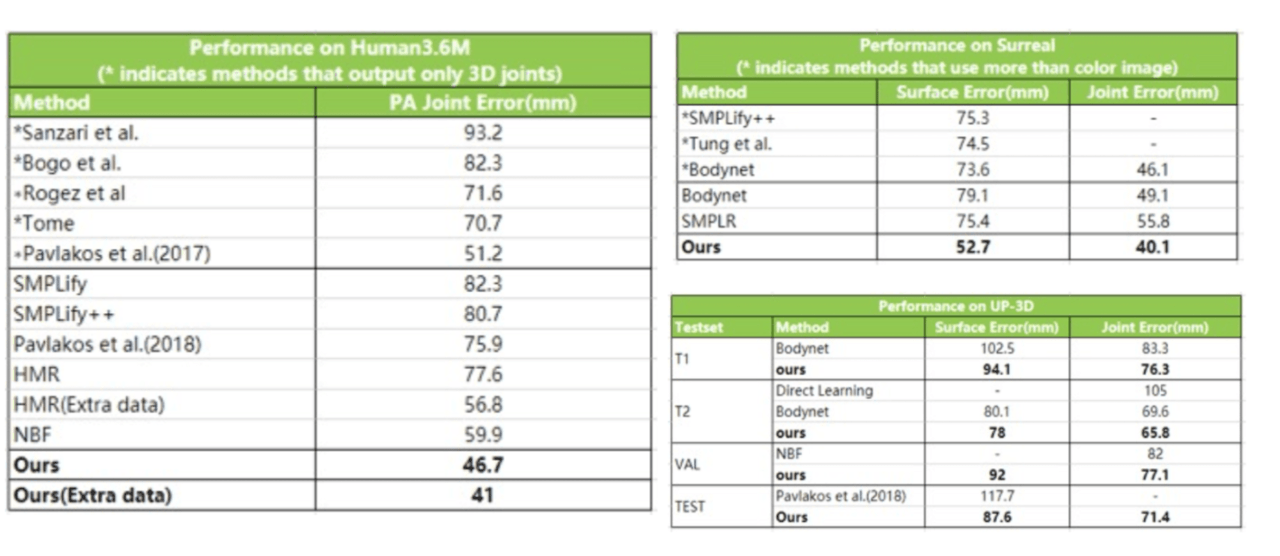
3D再構成の分野では、エラーは通常、アルゴリズムの能力を測定するための主要な指標として使用されます。一般に、誤差が小さいほど、精度は高くなります。Human 3.6M、Surreal、UP-3Dの各データセットでも1位にランクされ、以前の最小エラー記録を30%削減しました。
多様なアプリケーション

入力画像に対する要求が低く 1つの角度からの写真だけが必要なため、スマホでさまざまな3D漫画表現を実装することに加えて、3D人間の再構成技術もさまざまなシナリオで使用できます。
ショッピングモールでのアプリケーションシナリオを想像してみましょう。顧客の体の3Dモデルを再構築し、フィットミラーは体型に合わせて変更したい服装を自動的に生成し、服を着たことによる効果をシミュレートしてくれます。これを実現するために必要なのは、たった一枚の1つの角度からの写真だけです。モール内の化粧鏡が自動的に交換したい服を生成することが実現すれば、店舗のスペースが大幅に節約され、ユーザーエクスペリエンスが向上するでしょう。



この記事に関するカテゴリー






