「ELECTRA」新たな自然言語処理モデルが示したMLMの問題点とは!?
3つの要点
✔️その1 高速・高精度な自然言語処理モデルELECTRAが登場
✔️その2 低精度なGeneratorにより入力を置換することで、文全体から効率的に学習を行う
✔️その3 RoBERTaの約1/4の学習量で同等の性能を発揮
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
written by Kevin Clark, Minh-Thang Luong, Quoc V. Le, Christopher D. Manning
(26 Sep 2019 (modified: 10 Mar 2020))
Comments: accepted by ICLR 2020
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
はじめに
現在の自然言語処理では、BERT、XLNet、RoBERTa、ALBERTなどの事前学習モデルが猛威を振るっています。この分野は成長が著しく、時々刻々と新たなモデルが登場しています。
これらの言語モデルに共通する点として、入力文の一部をMASKトークンに置き換え、その部分を予測するMLM(Masked Language Model)という事前学習を行っていることが挙げられます(MLMについての詳細はBERTの記事で詳しく説明されています)。
本論文では、このMLMの問題点について指摘し、その問題を解決する新たな言語モデルELECTRA(Efficiently Learning an Encoder that Classifies Token Replacements Accurately)を提案しています。
ELECTRAは既存のMLMと異なる事前学習方式を採用しており、結果として高い精度と高速な学習を実現しています。自然言語処理のタスクにおいても、RoBERTaと同等以上の性能を発揮しています。
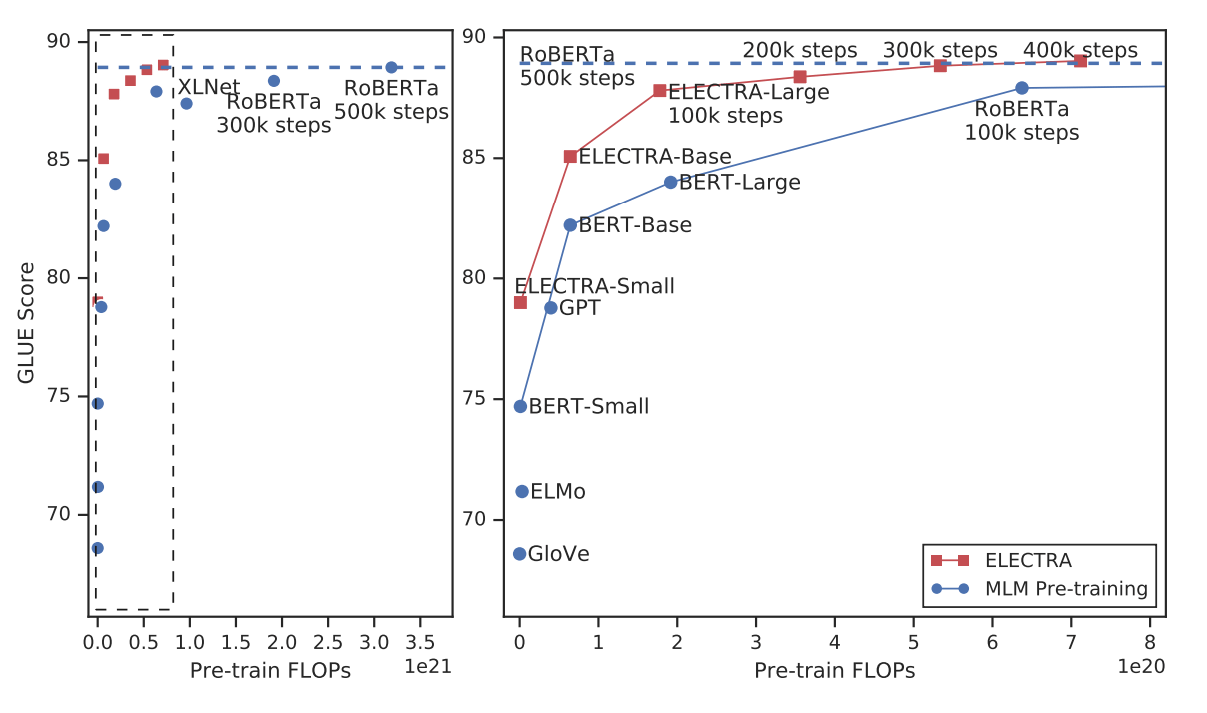
GLUEスコアの既存モデルとの比較。ELECTRAは少ない学習量で高い性能を発揮している。
続きを読むには
(3641文字画像9枚)AI-SCHOLARに
登録いただく必要があります。



この記事に関するカテゴリー






