GANのコピペ貼り付け機能の学習を利用した物体検出
論文:Object Discovery with a Copy-Pasting GAN
この論文では、画像内の教師なし物体検出という課題について取り組んでいます 。
新しいアイデアとしては、敵対的生成ネットワーク(GAN)からインスピレーションを得た、物体検出のためのトレーニング手順を設計しているところです。
GANは、コピー・ペーストにも使用されていますが、よくある用途としては、何をコピーすべきかを学ぶことではなく、リアルに見える視覚データを作成することです。本研究では、GANのコピーペースト機能を利用した教師なし物体検出とセグメンテーションに焦点を当ています。
CP-GANの合成手法

図1CP-GAN
コピーペーストGAN(CP-GAN)の中核的な考え方を図に表したものです。標準のGANと同様に、生成器の目的は識別器にとって本物に見える偽画像を生成することで、識別器の目的は、与えられた画像が本物か偽物かを正しく分類することです。標準のGANとの主な違いは、生成器が偽の画像を生成する方法です。ピクセルを直接出力するのではなく、「ソース」と「デスティネーション(目的画像)」の2つのイメージを組み合わせます。
つまり、生成器はソース画像から物体領域マスクし、マスクした領域を目的画像に貼り付けなければなりません。生成器がオブジェクトを不適切にセグメント化した場合、識別器は結果として得られた画像を偽造であると簡単に見なすことができます(図 1(b))。一方、生成器がオブジェクトを正しくセグメントした場合、識別器のタスクは難しくなります(図 1(c))。このように画像中の物体を別の画像へコピペする学習を利用した教師なし物体検出を提案しています。
“copy all”と”copy nothing”問題
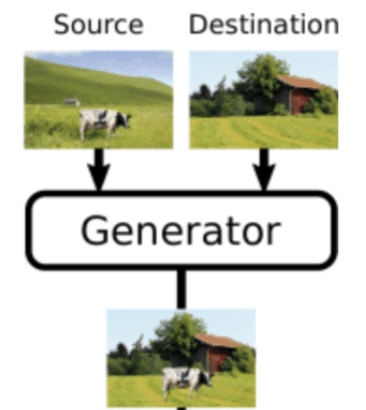
目的物を含む画像をソース、合成される画像をディステネーションとした場合、適切な割合で、2つの画像を合成する必要があります。
しかし、学習段階において、2つの極端な例として、ソース画像を完コピしてしまう”copy all”と、ディステネーション(目的画像)を完コピしてしまう”copy nothing”が存在します。
これらのショートカット(生成器が対象物を認識することなく画像を生成してしまうこと)の主な共通点はどちらか一方のみの画像を適用してしまい、同じコピーマスクをやみくもに適用してしまう可能性があることです。
そこで、ショートカットのタイプやソース画像の依存率など、いかなる仮定もしていないコピーマスクを罰する制約を考案し、適用可能なコピーマスクだけを生成させるようにいくつかの制約を与えます(以下で説明)。
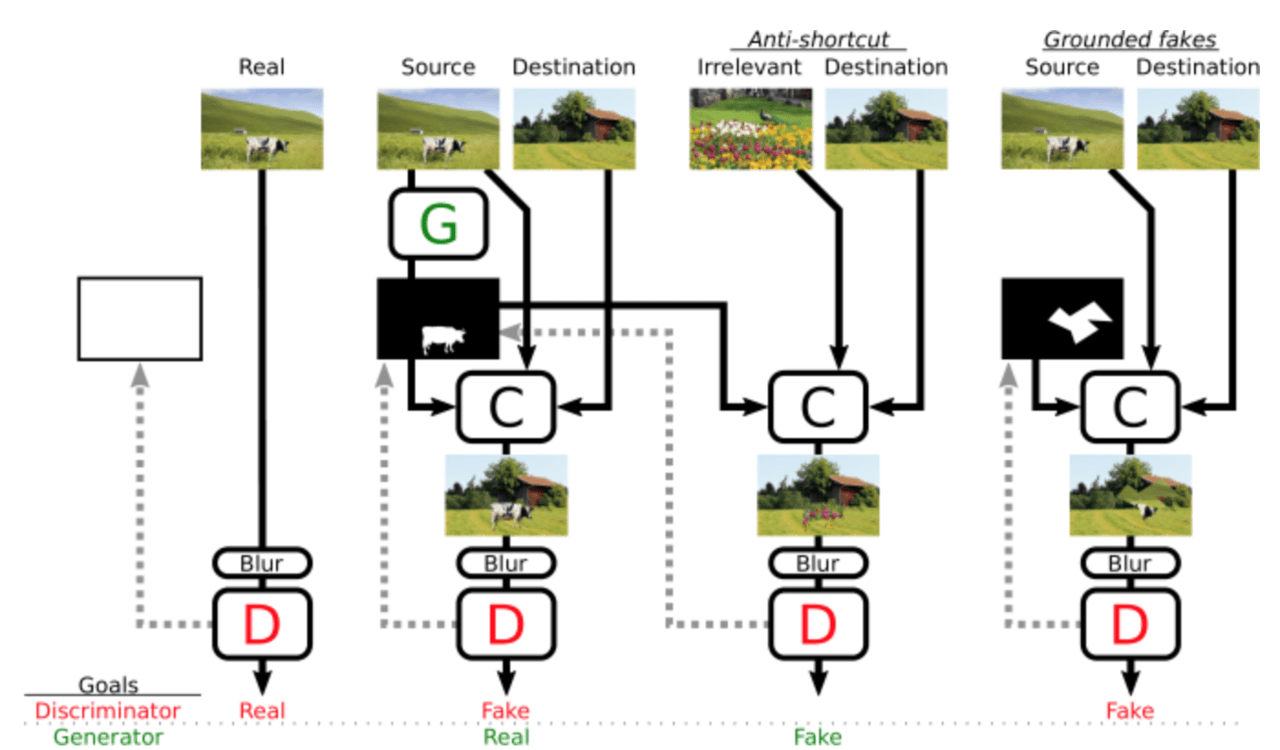
いくつかの制約条件と学習の安定化
1、生成器がマスクを普遍的に適用する(楽な解決策を見つける)のを防ぐため、アンチショートカットを追加し、関連性のない画像をブレンドしコピーマスクさせ、それを識別器に偽であると学習させます。
2、もし生成器が”copy-nothing shortcut”を採用した場合、識別器が偽画像の例を見ることは無くなります。これは、識別器が意味を持った学習をするのを妨げてしまい、学習の崩壊につながります。この問題を軽減するために、人工的に”grounded fakes”(偽の画像はランダムな2枚の画像から構成されたもの)を学習ループに挿入することで、識別器に本当の画像と偽の画像区別させる学習をさせます。
3、CP-GAN中の生成器がオブジェクトの切り取りと合成について学習するために、識別器は”適切な範囲で生成された画像”を元にした識別結果を生成器に提供しなければなりません。しかし識別器が、いくつかの局所的な手がかりのみを受け取った場合、GANは、小さな手がかりの発見とその修正に過度に焦点を合わせてしまいます。これを防ぐため、識別器への入力をぼかし簡単なショートカットを受け取らないようにします。
こんな感じで生成器と識別器の楽な抜け道を防ぐいくつかの制約を加えることで学習を安定化させます(詳しくは論文を参照ください)。これらいくつかの制約を加えた全体図が以下になります。
結果

CP-GANを用いた物体検出の例です。ほとんどのデータセットに対し、オブジェクトを正しく選択してセグメント化し、Squares、NoisySquares、CLEVR + bgに対してそれぞれ98.3%、100%、98.3%の精度を達成しています 。物体の見え方や背景の乱雑さが比較的大きく変化する画像(Flying Chairs)では、40.3%となっています。



この記事に関するカテゴリー






