スピーチ音声から話し手のジェスチャーを予測することが可能に
論文:Learning Individual Styles of Conversational Gesture
人間のコミュニケーションは、視覚と音声の両方から成り立っています。しかし、これらの感覚の関係や、何からどのような情報を受け取っているのかは、いまだに不明瞭な部分が多く存在します。この研究では、この関係性を解明するために、生の音声データから話し手の特定のジェスチャーを予測するモデルを提案しています。
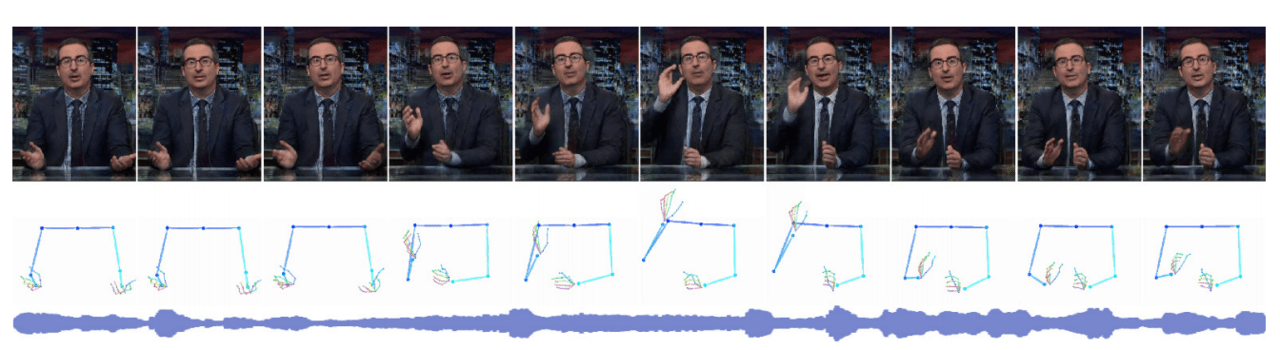
音声からジェスチャを予測するモデルの結果
音声から動きを生成するためには、音声からポーズへのマッピングを学習する必要があります。これは変換として定式化することができますが、実際には、オーディオデータとビジュアルデータを自然に対応させるには、2つの課題があります。
1.ジェスチャとスピーチそれぞれ時間差があり、ジェスチャーを行うのはそれに対応する話の前後、最中のいずれもあり得ること
2. 話し手は、同じ内容を話していても、ジェスチャーが異なる場合があること
また、必要な大量のビデオに対して人間がラベル付けを行っていくのは非常に大変(不可能)です。さらに、話すときの各人の身振りも非常に特殊であり、話し手が異なればジェスチャーも異なります。
これらの問題を解決するために、大量のデータを使用し、ラベル付けは行わずGANのメカニズムを用いて、最適なジャスチャーを”生成”することを目標とします。
データセット
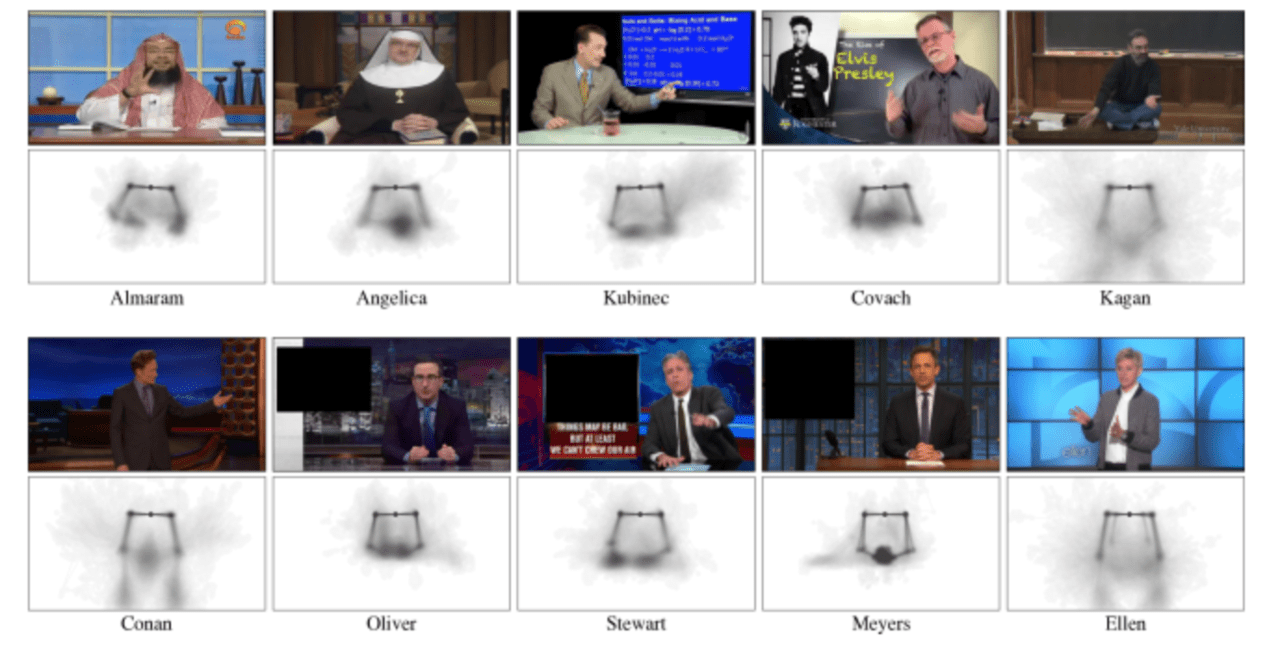
10人の話者からなる144時間の個人ビデオデータを作成しました。テレビの司会者、大学の教師、伝道者などが含まれます。議論に含まれているトピックは、死の哲学、化学からロック音楽の歴史、ニュース解説、聖書を読むことなど、多くのトピックにまたがっています。
それぞれの下にはヒートマップがあり(上画像)、これらは、既存モデルのOpenPose を使って得られる骨格のキーポイントを表現しています。OpenPoseによって検出された全てのキーポイントのセットから、首、肩、肘、手首、手に対応する49個のポイントを使います。
このビジュアライゼーションは、話者の休憩時の姿勢と、そこからどのように動く傾向があるかを明らかにしています。たとえば、アンジェリカは両手を折ったままにする傾向がありますが、キュービネックは頻繁に左手で画面を指す傾向があることがわかります。
モデル概要
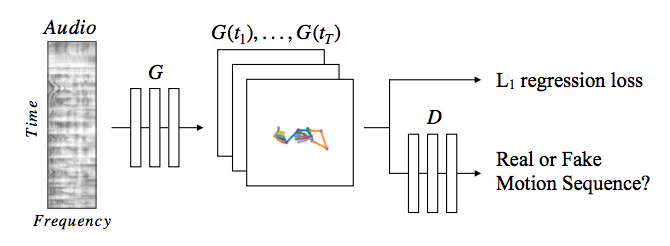
上の画像がモデルの概要図になります。
目的としては、「生のスピーチ音声から、話し手の腕と手のジャスチャーを予測する」ことです。
スピーチ音声を骨格画像に変換し、L1正則化とGANの識別器を組み合わせて用いるという2段階のアプローチによって従来モデルよりナチュラルなジェスチャーを音声のみから再現しています。
はじめに音声信号から、生成器を通じて低解像処理を行い骨格(ジェスチャー)の動きを生成し、L1正則化を行うことで尤もらしい動きに近づけていきます。
さらに、生成されたジャスチャーモデルの過学習を防ぐために、本来のジェスチャーのデータセットを学習させたGANの識別器を用意し、自然なジャスチャーの動きを生成できるように生成器を訓練します。
結果
下のGIFは左から順に、入力となる音声、入力から推定した骨格、それを基に合成したものです。

以下の画像はスピーチからジェスチャーへの変更結果を視覚的に比較したものです。正解のジェスチャーシーケンスに予測された骨格シーケンスが重ねられて表示されています。ベースラインの方法と比較しても一番正確に予測されており、ほとんどズレがないことが分かります。


しかしモデルには未だに多くの制限があるとも述べられています。その例として、音声はエンコーダーを通した際に特徴量を抽出すると情報を失ってしまい、現状では決まったパターンのジェスチャーしか予測できません。しかしながら、他モデルとの組み合わせによりこれらの欠点を解消できる可能性は大いにありそうです。
例えば、自然言語処理を用いることで、”文字情報”からであれば失う情報量は音声より少ないため、多様なジャスチャーを表現できるかもしれません。
今後は、より観衆に影響を与えるスピーチやニュースキャスティングの身振り手振りを計算するなど、”コミュニケーション”における重要な役割を担う研究が期待されます。
詳細な結果はこちらの動画から確認できます。



この記事に関するカテゴリー






