画像ベースの深度マップを点群に変換し擬似LIDARとして表現する3D検出法
自動運転を実現するには、車両の周囲の物体を3次元で視覚化して検出することが不可欠です。
例えば、人は車を運転するとき、脳は即座に周囲を3Dで視覚化し、車の周りにあるものをスキャンし、潜在的な危険を評価しています。自動運転においても、何が起きているのかを視覚情報(カメラ)から把握し、危険を回避する必要があるため、高度なセンサーを使用して車の近くの物体を正確かつ高速に検出することが求められてきます。
現在、自動運転における環境認識センシング技術としてかかせないのは、LIDAR(Light Detection and Ranging)です。LIDARはレーザーを使用して周囲の3D点群マップを作成し、高速で物体の距離を測定します。しかし高価で、1台の車あたり10,000ドルのコストが必要だといわれているのです。さらに、これらのセンサーは自動車の屋根に固定されているため、風の抵抗が大きくなり、エネルギー効率も良くありません。
一方、より安価なステレオカメラは非常に手頃な価格(LIDARより数桁安い)で動作し高密度の深度マップを作成しますが、精度は低いと考えられています。
発表された論文では、ステレオベースとLIDARベースの精度のギャップの原因は、推定された深度の品質(データの品質)ではなく、その表現であると考え、ステレオカメラから画像ベースの深度マップを擬似LIDAR表現(LIDARセンサーから来る3D点群にある程度似ている表現)に変換するための方法を提案してます。
疑似LIDARとして表現する
ほとんどの自動運転車では、カメラやセンサーでキャプチャされたデータは、畳み込みニューラルネットワークを使用して分析されます。これらの畳み込みニューラルネットワークは、標準的なカラー写真でオブジェクトを識別するのに非常に優れていますが、正面から表現すると3D情報を歪める可能性があります。

代わりに、畳み込みニューラルネットワークの内部の働きを考慮して、画像ベースの深度マップを、点群に変換し、擬似LIDARとして表現することを提案しています。
ステレオからの画像が与えられると、最初に深度マップを予測し、次に各ピクセルをLIDAR座標に投影することによる深度マップ画像から点群へ逆投影するというアイデアです。この表現を疑似LIDARと呼び、この表現にLIDARベースの検出アルゴリズムを適用しLIDARとまったく同じように処理します。
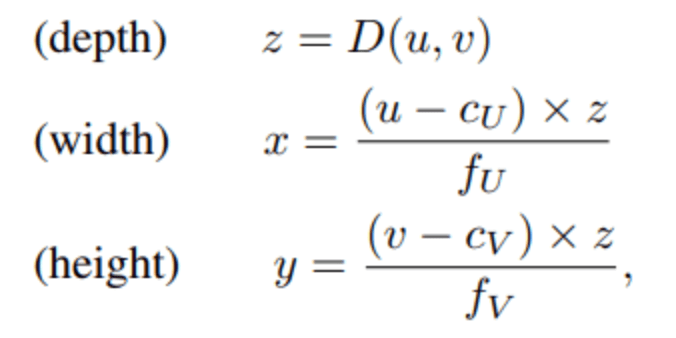
一般的に行われているように、RGB画像への複数の追加のチャンネルとして深さDを組み込む代わりに、各ピクセル(u、v)の3D位置(x、y、z)が、カメラの座標系において導出されます。
このアプローチを用いることで、精度が3倍以上になり、ステレオカメラがLIDARの低コストの代替手段になることを確認できました。以下の画像では、生成された疑似LIDARの点群が元のLIDAR信号と良く一致していることがわかります。
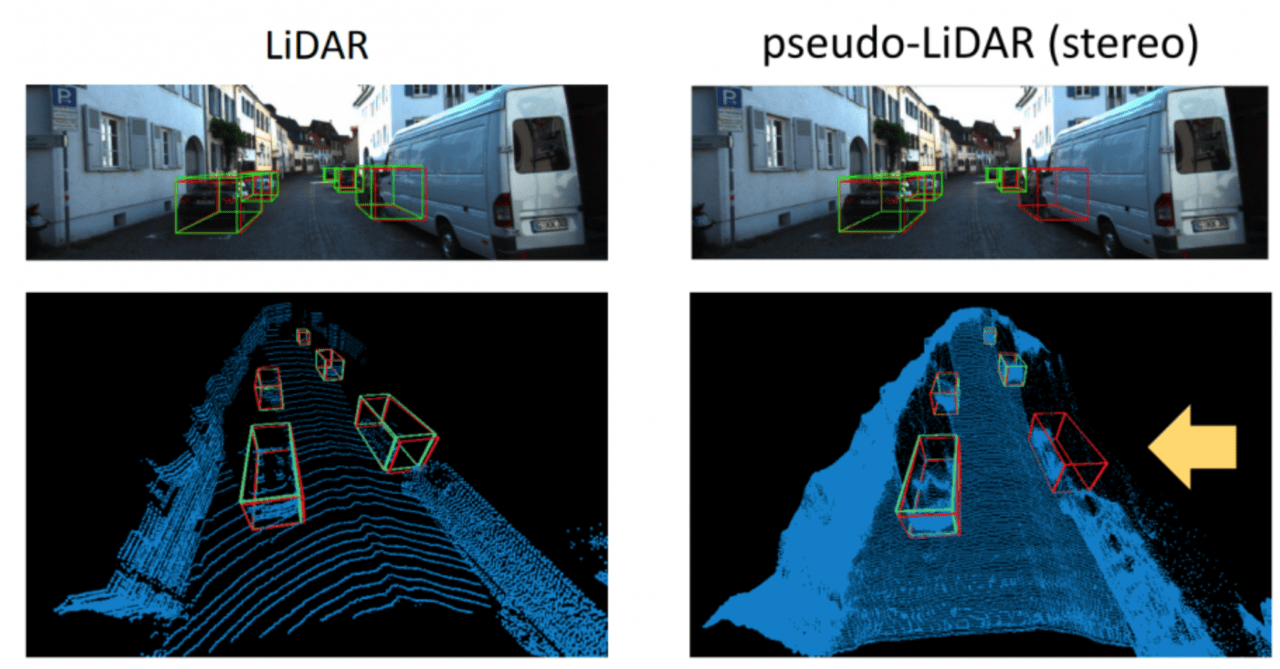
さらに、擬似LiDARはその信号がLiDARよりはるかに高密度なため、非常に信頼性の高いバックアップとして相補的な役割を果たせます。LiDARと擬似LiDARのセンサ融合により、3D物体検出における問題点を改善できるかもしれません。
自動運転の技術がハイテクに依存していることを考えれば、ステレオカメラを用いたこのアプローチは、 大幅なコスト削減や安全性の向上をもたらし、業界に革命を起こす可能性を秘めているのではないでしょうか。



この記事に関するカテゴリー






