楽譜を修復してインタラクティブな音楽生成を可能にする生成モデル
論文 LEARNING TO TRAVERSE LATENT SPACES FOR MUSICAL SCORE INPAINTING
ソースコード : InpaintNet (Supplementary Material)
最近、ディープラーニングを用いた音楽生成が盛んに行われています。モノラル音楽生成、重なった音楽生成、表現力豊かな音楽の作成など、いくつかの異なる音楽生成タスクによく適用されてきました。
しかしながら、これらのモデルの大部分は過去の音楽に依存しています。
さらに対話性という点で厳しい制限を有しており、生成された後は、ユーザの美的感覚や構成要件に適合するように調整する方法を持ち合わせていません。
本論文では、過去と将来の音楽的文脈から「欠落した情報を楽譜に記入するようにモデルを訓練することを提案しています。画像に用いる補完のネットワークを音楽に適用させたというと分かりやすいでしょうか。
従来モデルでは入力された譜面を元に楽譜の”予測”を行うことが主だったのに対し、本モデルは楽譜の欠落した部分の”前後”を入力することでその間の”補完”を行うことが可能です。
この技術を用いることで、 既存の音楽から一部分をあえて削除しAIに補完させることで新しいメロディーアイデアを獲得したり、異なる2つのジャンルの音楽を自然に繋ぐことなどができます。
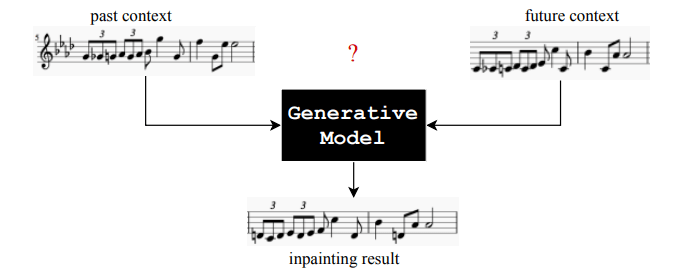
モデル概要
1.モデル俯瞰図
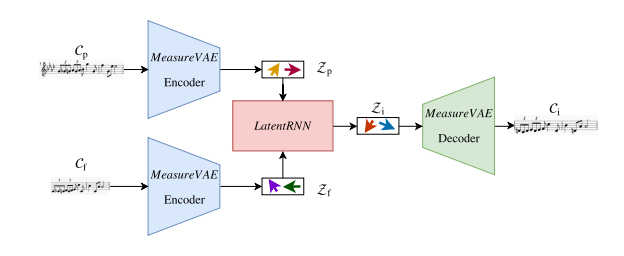
上図がモデル全体の概要になります。
入力データとして、補間したい部分を現在としたとき、Cp (補間部分の直前)、Cf (補間部分の直後)を用います。それらを、それぞれMeasure VAE Encoderに入力し、潜在ベクトル表現(Zp, Zf)に変換します。次に得られた潜在ベクトル表現をLatent-RNN (下記2.参照) に入力することで特徴量を算出し、補間v部分のベクトル表現を得ます。最後に、Measure VAE Decoderを通じて予測部分のベクトル表現をメロディーに変換し出力します。
VAEは既存モデル「A hierarchical latent vector model for learning long-term structure in music」を用いて、音楽と潜在ベクトル変数の変換を行なっています。そのため、潜在変数空間の確率モデルとして、正規分布を仮定しています。
また、学習を通じて任意の拍子数分(実験では2 ~ 8拍子分でテスト)の予測、かつ譜面の間のどこであっても、直前直後のデータを入力することで再現可能です。
2.Latent-RNN
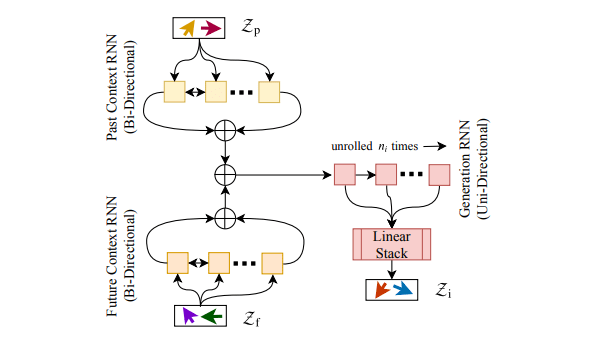
Latent-RNNは、直前・直後の入力と合成、ループ展開による出力部分の3つのパートに分かれています。入力データである、補間部分の直前・直後の潜在ベクトル空間からそれぞれ特徴量を抽出し、合成します。最終的に、合成した特徴量をGeneration-RNNにおいてループ展開し、線形変換を行うことで補間された潜在ベクトルを出力させます。
RNNを上記のように用いて合成を行う事により、これまでのモデルとは異なり補間したいパートの直前データだけでなく、直後のデータも用いて補間を行えます。これを用いて、(直前データのみを入力データとして用いる)従来モデルよりも高い精度で補間予測を可能にしています。
結果
実験は、Sessionウェブサイトから得られたスコットランド風とアイルランド風の単調フォークメロディのデータセットを使用しています。
1.既存モデルとの比較
既存モデルの”ARNN”と本モデルを、ホールドアウト法により比較しています。
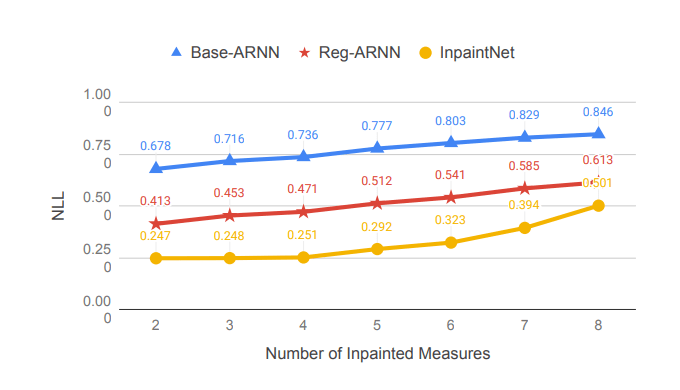
上の図は、本モデルとベースラインの比較を行なったグラフです。横軸は補間する拍子数を表しており、2~8拍子までの予測を行なっています。指標(縦軸)として、負の尤度関数(NLL : negative log-likelihood)を用いているため低ければ低いほど尤もらしいメロディーを生成していると読み取ることができます。この時、本モデル(黄色)がベースラインと比較し全ての拍子において低い数値を表していることがわかります。
2.”前後”データを用いることによる精度向上の検証
また、本モデルを用いて、token-wise NLL(負の尤度関数)において平均した補間精度は、0.300となっています。”直前のメロディー”からのみを入力データとして補間した場合の精度は0.643、”直後のメロディー”からのみを入力データとして補間した場合の精度は0.481となっており、本モデルは”直前と直後”の両方の特徴量をしっかりと合成し、最適化できていることがわかります。
この学習アイデアは、他の音楽生成タスクにも有用であると考えられます。例えば、LatentRNNモデルのアーキテクチャを変更して、他の音声/楽器からのコンテキスト情報を追加することで、マルチ楽器音楽生成に応用するなんて考えてみても面白いかもしれません。



この記事に関するカテゴリー






