順序付きニューロン。ツリー構造のリカレントニューラルネットワークへの統合
ICLR2019が開催されました。最優秀論文賞を受賞した論文では、隠れ層の更新頻度の順序を強制し、周期的モデルに潜在的木構造を統合することができる手法が提案されています。
【論文】Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks
一年一度のAI分野の進歩に貢献する大規模カンファレンスである ICLRは5月6日から9日まで、ニューオーリンズで開催されます。統計によると、ICLR 2019は合計1,591件の論文の提出を受け、去年と比較して60%増加したそう。
そんな中、ICLR 2019に最適な論文が発表されています。その一つが、「Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks」です。この記事では、最優秀論文賞を受賞したこちらの論文をざっくり簡単に紹介していきます。
言語における階層構造
ほとんどの言語学者は、言語は階層的に構造化されていると考えています。
言葉を理解し生産することは、より小さな構成要素がどのようにしてより大きな意味の構造を形成するかを支配する、入れ子になったツリー構造に対する獲得された能力を意味しています。
言語学者はこの規則を発見しましたが、その根本的な構造の本当の起源はまだ知られていません。いくつかの理論は、これが人間の認知の根底にあるメカニズムに関連しているかもしれないことを示唆しています(Chomsky&Lightfoot、2002)。また、ニューラルネットワークは、生物学的な神経系の情報処理に触発されているので、言語の根本的な構造を研究するためのニューラルネットワーク使用へのさらなる関心をもたらしました。
一方、標準的なLSTMは、異なるニューロンが異なる時間スケールで情報を追跡することを可能していますが、構成要素の階層をモデル化することに対して明確な偏りを持っていません。
本稿では、このようなバイアスをニューロンの順序付けによって追加することを提案しています。
具体的には、LSTMユニットを用いたRNNモデルに基づいて構築しました。入力テキスト内の各単語に対して、LSTMは、再帰的に更新され、シーケンス内の次の単語を予測するために使用される隠れ層を生成します。隠れ層に長期および短期の情報を別々に割り当てることによって、ツリー構造をRNNに統合することを目的としています。
もう少し詳しく
ツーリ構造では、情報は構成要素が終了するたびに、構文ツリー内のその親に伝達されます。構文木の根元近くのノードには、ゆっくりと変化する情報が含まれているのに対して、小さい構成要素ほど頻繁に更新されることを意味しています。
論文では、隠れ層を「順序付ける」ことによってこの力学をモデル化することを提案しています。低位のニューロンは急速に変化する情報をモデル化すると見なされる一方、高位のニューロンは長い時間スケールにわたって情報を保持します。各時間ステップで、モデルはどのニューロンを消去(更新)する必要があるかを選択します。重要なことは、それらの順に並んでいるすべてのニューロンも消去されるということです(更新されます)。
これは、構文ツリーに通じる隠れ層での情報の階層の出現を確実にします。特に、ツリー構造内のさまざまなノードを隠れ層のさまざまな部分にエンコードすることを目的としています。
実験では、系列中の次の単語を予測することにより学習した、更新/消去すべきニューロンに関する決定が、専門家の言語学者によってラベルをつけられる構文構造を伴う正確なものであることがわかりました。
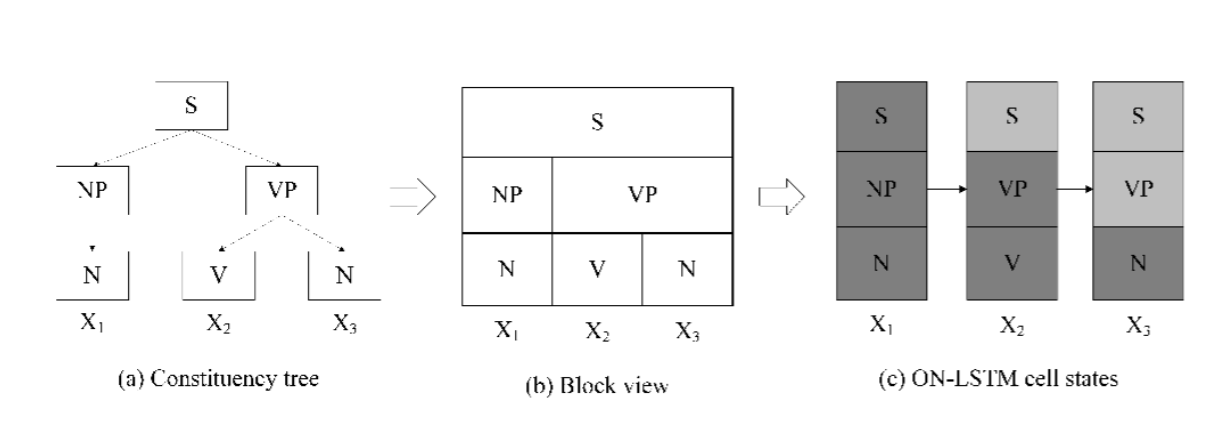
図1:構文ツリーとON-LSTMの関係
トークンシーケンス(x1、x2、x3)を与えた、その構成要素解析ツリーが図(a)に示されています。
図(b)は、SノードとVPノードの両方が複数のタイムステップにまたがるツリー構造のブロック図を示しています。 上位ノードのトークンは、複数の時間ステップにまたがって相対的に一致する必要があります。
図(c)はニューロンのグループ毎の更新の割合を示しています。各ステップごとに入力語を与えると、深い灰色のブロックが完全更新、浅い灰色のブロックが部分更新を表しています。三つのグループニューロン更新頻度は同じでないことが分かります。高レベルのグループの更新はそれほど頻繁ではなく、低レベルのグループの更新はより頻繁に行われます。
実験での非常に興味深い発見は、教師なしの構文解析で強力なパフォーマンスを達成していることです。ターゲットとされた構文評価では、このモデルが既存のモデルよりも長期的な構文上の合意をうまく扱えることが示されています。
まとめ
より優れた言語モデルを想像するという探求は、長年にわたりそして未だ開かれています。本研究では、RNN言語モデルの内部機能を言語理論の中核にある一般原則にうまく合わせる方法を提供しました。モデルに特定の先験的な構造を強制することで過度に介入的であると、そのパフォーマンスが損なわれると考えられますが、代わりに、ここではそのような構造の発見を支持するようにモデルを慎重に偏らせます。教師なし解析タスクに対する有効性は、このモデルが正しい構造を発見する能力を持っていることを示しています。
【参照】Brief Report: Ordered Neurons: Integrating Tree Structures into Recurrent Neural Networks



この記事に関するカテゴリー






