深層強化学習によるストロークで質感豊かな自然なペイント生成
画面に対して、大きく腕を振るって筆を動かすような運動感のある行為を「ストローク」といい、画家はこれら、”ストローク”を使用し魅力的な絵を描くことができます。この研究では、AIに”ストローク”の位置と色を直接決定させ、何百もの視覚的に良い絵を生成させる方法を提案しました。
【論文】Learning to Paint with Model-based Deep Reinforcement Learning
画家は数本のペンとタッチで魅力的な絵を描くことができます。この研究では、機械にそのような能力をマスターさせる方法を追求しようとしてます。ニューラルネットワークのストロークレンダラーとモデルベースの深層強化学習を組み合わせることによって、AIはストロークで質感豊かな自然な画像を描くことができます。ストロークごとに、ストロークの位置と色を直接決定し、何百もの視覚的に良い絵を生成します。
以下の画像では、喧騒の白さから建物の輪郭までストロークを使って描いてることがわかります。

こちらは肖像画です。

こちらはゴッホの有名なひまわり

抽象画だって”ストローク”で描けます

フリーハンドペインティングAIの誕生
研究のメンバーである黄Zhewei氏のインスピレーションは絵画を勉強した経験から来ています。
彼は、Dürer(ドイツの画家)や初期のPicassoなど、画家の作品を見て、鮮やかなイメージを構築するために非常に少ないストロークと非常にシンプルなトーンを使用していることに気づきました。これらの技術的背景には、物の構造を深く理解し、ブラシをしっかりとコントロールし、ストローク間の関係をよく理解する必要があります。

一方、コンピュータでは、画像はn×nピクセルで構成され、各ピクセルはRGBの3つの値によって決定されます。この意味で、コンピュータに写真をコピーさせる最も簡単な方法は、ピクセル単位で塗りつぶすことです。しかし、コンピュータ上の絵を人間が使うストロークで再現させるにはどのようにすれば良いのでしょうか?
この論文では、強化学習の観点から、AIをデザインし、キャンバスとターゲットイメージを与えます。AIの各ステップはキャンバス上にストロークを描くことですが、描くストロークがターゲットイメージに近づくと、それに報酬を与えて学習させます。さらに一定のストローク数の後にAIが終了するようにストローク制限を設定します。
タスクの難しさ
ストローク位置と色を含むストロークパラメータ空間は、ペイントに不可欠です。各ストロークのモーションスペースは非常に大きいため、AIはストロークの位置、形状、色、透明度を決定する必要があり、各パラメータにはさまざまな選択肢があります。
一般的な強化学習アプローチでは、AIが多くの試みを通じて環境をモデル化する必要がありますが、これは非常に困難で時間がかかります。例えばDeep Q‐Network(DQN) などはこういったパラメータ空間を扱う能力が低く、連続空間上でストロークパラメータを定義することは難しいと考えられます。
ここでは、連続動作空間を扱うのが得意なDeep Deterministic Policy Gradient(DDPG)を採用し、微妙な制御います。さらに、DDPGをモデル―ベースのアプローチに変更しています。
ストロークレンダラー
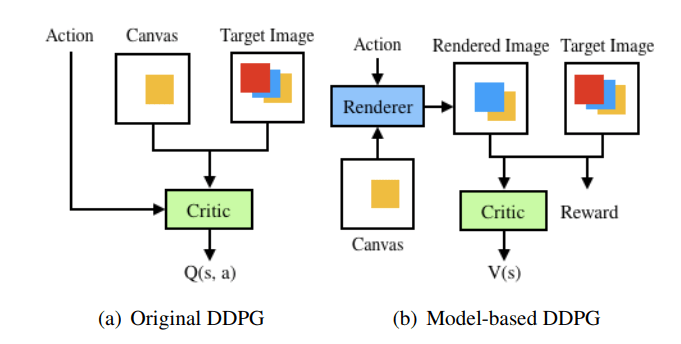
困難なモデリングの問題を解決するために、ストロークのパラメータに従ってキャンバス上のストロークを素早くレンダリングし、GPU上の並列処理をサポートすることができるニューラルネットワークストロークレンダラーを事前訓練しています。
ニューラルネットワークストロークレンダラーはまた、強化学習のフレームワークにプラグインすることもできます。これにより、DDPGをモデルベースのアプローチに変換し、AIトレーニングのスピードとパフォーマンスを大幅に向上させています(下記参照)。
報酬設計
エージェントの目的は、指定された目標のペイントを基に、白紙のキャンバスに”効率的なストローク”による再現性のあるペイントを作成することとします。
絵そのものと同時に”人間の塗装過程”も模倣するために、エージェントは”ストローク”に注目し、常に作成しているペイントが目標となる画像に近づけるようなストロークを、1ピクセルごとに計算し予測するよう設計されています。
また、最適な次のストロークを予測する能力を得るように、フィードバックを設計します。フィードバック機構では各ピクセル毎に次のストローク確率的にいくつか算出した後、得られるであろう報酬を計算し、候補の中から最適なストロークを選び出します。
この計算を繰り返すことで、DDPGは”人間と同じかつ、最適に効率化された手順(ストロークの繰り返し)”によって、”目標となる絵”を再現します。
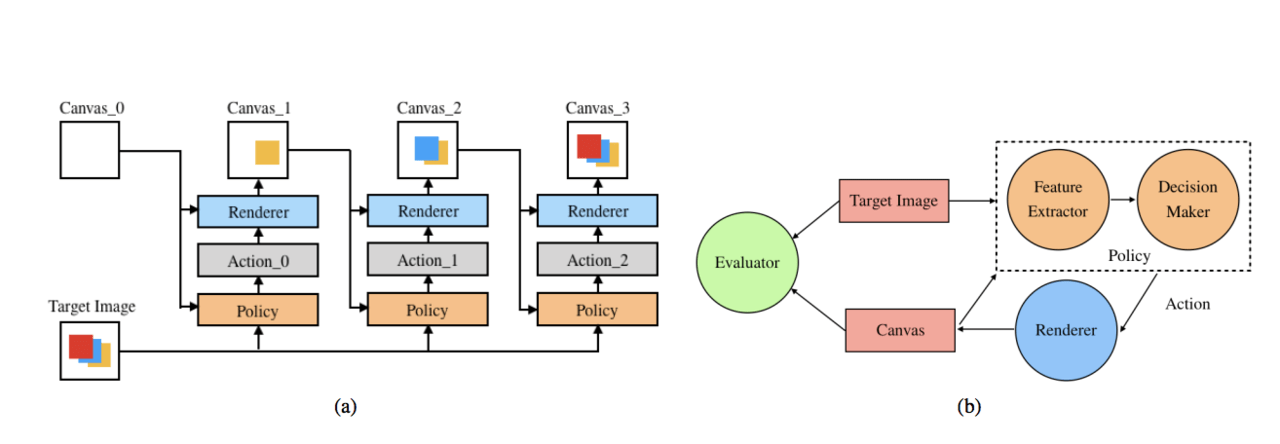
以下が、全体的なアーキテクチャの図です。
DDPGアルゴリズムとGANの利用
DDPGは戦略勾配法と価値関数法のハイブリッドアルゴリズムであるActor-Criticフレームワークを使用しています。絵を生成するのは、アクターと呼ばれ、価値ネットワークは評論家と呼ばれます。ペインティングのタスクでは、アクターは毎回ストロークを描き、評論家はアクターのストロークを評価しますが、その目標はより良い評価を得ることであり、評論家の目標はそれをより正確に評価することです。これにより報酬を最大化させます。
DDPGは最高の一枚を生成するために、ひたすら絵を繰り返し描いてきます。しかし生成されるイラストは、強化学習によって近似的に得られた確率分布から生成されたものであるため、最高の一枚の候補が何枚かある状態です。目標データとの分布との差が最小である最適な分布を選び出す必要があります。そこで、GANを用いた目標データの分布との差を最小化する識別を行います。
GANは生成データと目標データの分布の差を図る能力の高さから、転移学習や言語モデル、画像復元などにおける損失関数として幅広く使われています。ここでは、これらの識別をGANを進化させたWasserstein GAN(WGAN)で行います。
WGANの判別の目的関数は、以下の式で定義されます。
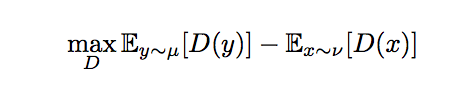
Dは識別器を意味しており、νとμはそれぞれ生成された絵と目標の絵の分布を指します。この生成された絵と目標の絵の分布の距離の最小化を目指します。
識別スコアの差を設定し、アクターの学習方向を決定づける報酬として以下の式を使います。
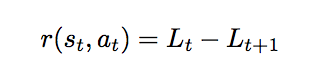
rは報酬、tは各ステップ数 (何番目のストロークか)を指し、Lは目標となる絵と生成中の絵の損失関数を表します。また、r (報酬関数) の中のs、aはそれぞれ各ステップにおける状態と行動を指し、報酬関数がある時点の状態と行動のみから計算できることがわかります。
この研究ではWGANの損失関数が、従来の損失関数よりもエージェントを学習させるために優れていることがわかりました。
結果
手書きの数字(MNIST)、ストリートビュー(SVHN)、Celebrity Faces(CelebA)、Natural Scene Images(ImageNet)など、いくつかのデータセットで実験を行いました。

100ストロークから1000ストロークまで、ストローク数が多いほど細部の復元性が向上することがわかりました
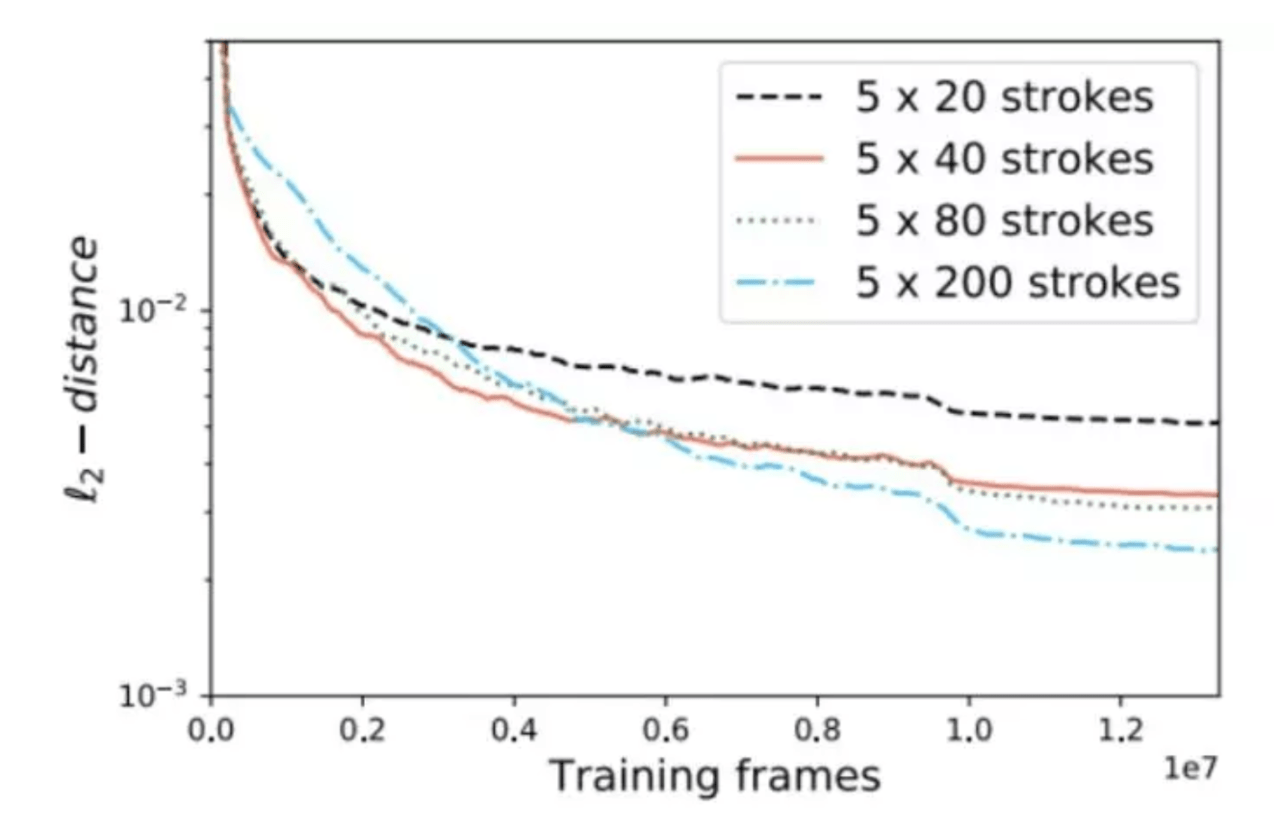
さらに興味深いことに、AIを制限して円を描く、三角形のみを描くなど、非常に興味深い結果を得るためにさまざまな形状のストロークを設計することもできます。これらのストロークは、さまざまなデータセットに適応できます。




この記事に関するカテゴリー






