オプティカルフローを用いたピクセル伝播によるビデオ修復
【論文】 Deep Flow-Guided Video Inpainting
この論文では、ビデオの欠けている領域を埋めることを目的とするビデオ修復に取り組んでいます。ビデオ修復は、空間的/時間的な一致を維持しつつ欠落領域を埋めなければならず、依然として難しいタスクです。ビデオを復元するだけではなく、望ましくないオブジェクトを除去したり、現実的な用途が数多くあります。
従来のディープラーニングを用いた画像修復アプローチでは、各フレームに画像修復アルゴリズムを直接適用したり、ビデオシーケンス全体を直接ペイントしたりなどする手法が主流でした。これらの方法ではズレが生じてしまったり、また非常に大きなモデル容量が必要で実用的ではありませんでした。

失敗例
本論文では各フレームのRGBピクセルを直接埋めるのではなく、ビデオ修復をピクセルの伝播問題と見なします。最初に、オプティカルフローを生成し、次に生成されたフローに基づき、ビデオ内の欠落領域を埋めるためにピクセルを伝播し補完していきます。
フレームワーク
(1)最初のステップでは、粗いフローから細かいフローを生成するDFC-Net提案を提案しています。DFC-Netは、DFC-Sという名前の3つの同様のサブネットワークで構成されています。最初のサブネットワークは入力として連続フレームを受け取り、比較的粗いスケールで中間フレームのフローを推定して、さらに洗練させるためにそれらを2番目と3番目のサブネットワークに供給して精度を徐々に向上させていきます。
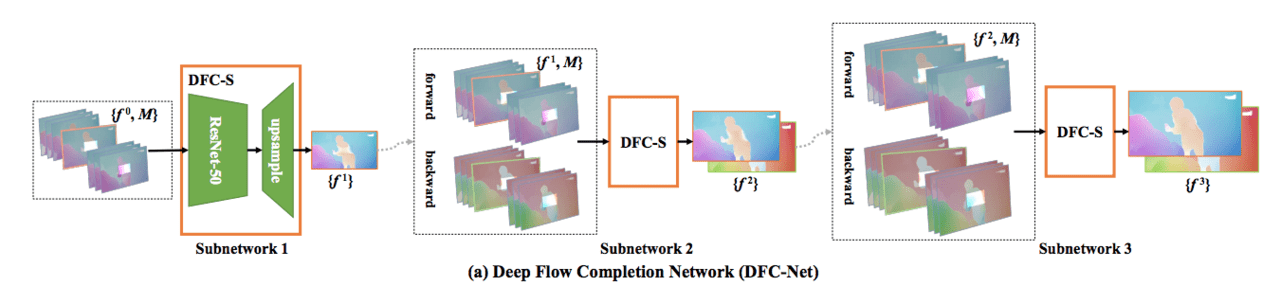
図1DFC-Net

抽出されたフロー
(2)1のDFC-Netによって生成されたフローは、フレーム間のピクセルの接続を助け、伝播によって欠落領域を埋めるためのガイダンスとして使用することができます。フローに基づいて、すべての既知のピクセルを双方向に伝播し、未知のピクセルを埋めていきます。
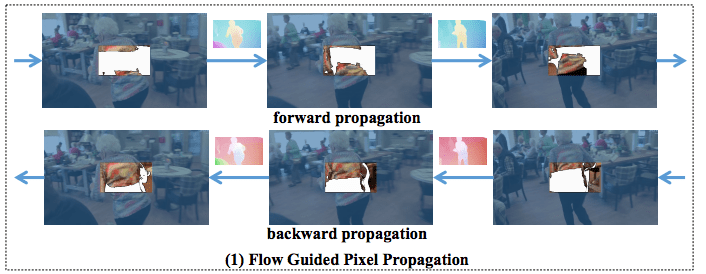
図2フローガイドによるピクセル伝播
(3)しかし、場合によっては、ピクセルで埋めることができないケースがあります。残ったピクセルを埋めるために、従来の画像修復ネットワークを採用し、ビデオシーケンス内の塗りつぶされていない領域を塗りつぶし完成に近づけて行きます。さらに、このインペインティング結果から推定したフローに基づいてビデオシーケンス全体に伝搬します。このように、画像の修復ステップと伝播ステップは、欠落領域が見つからなくなるまで繰り返し適用されます。平均すると、12%の欠落領域があるビデオでは、通常、欠落ピクセルが1%あり、1.1回反復すると完全に塗りつぶされます。

図3欠落領域をペイントする
実験
欠けている領域を埋めることを目的とした修復作業について、DAVI/YouTube-VOSデータセット上で他の既存の方法と比較しています。
表4に示すように、従来のビデオインペインティング手法と比較して、ビデオ修復品質とスピードの両方において最先端の結果を達成しています。また、画像インペインティングアルゴリズムを各フレームに直接適用すると、結果が劣ってしまうこともわかりました。
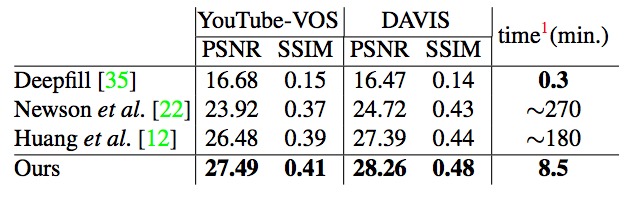
図4 従来手法との比較
続いて、オブジェクトを綺麗に除去できるかどうかを実験しています。一つの合理的な解を定義するのは難しいため、アプローチの性能を定量化するためにユーザアンケートを実施しています。各参加者に対してDAVISデータセットからビデオをランダムに選択し、異なる設定の下で本手法を含めた三つのアプローチによって塗りつぶされます。詳細を見やすくするために、ビデオは低いフレームレートで再生されます。各ビデオサンプルについて、参加者はビデオの再生後に3つの修復結果をランク付けするように要求されます。同じく他の2つのベースラインよりも著しく優れた評価を得ています。
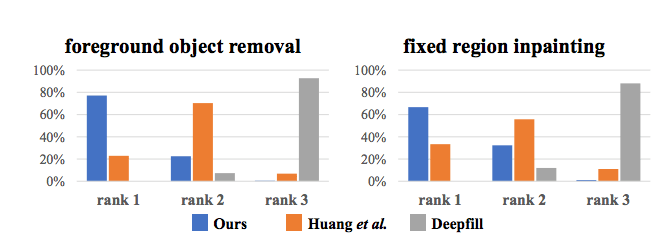
図5ユーザー調査 「ランクx」は、各アプローチからの修復結果がx番目に最良のものとして選択された割合を意味する。

詳しい結果はこちらの動画で確認できます。



この記事に関するカテゴリー






