一枚の画像と音声から音声に合わせた顔を生成する音声駆動型の顔アニメーション
【論文】 Realistic Speech-Driven Animation with GANs
1枚の写真と音声データから「人が話す映像」を作り出す技術が新たに発表されました。有名女優のポルノや偽のニュースを無尽蔵に作れるディープフェイク技術がまた大きく進歩したとして話題となっています。
論文では、音声に合わせて動く顔のアニメーション生成に取り組んでおり、音声信号と単一の静止画像を合成し、音声に合わせて人が話す動画を生成するGANを提案しています(下図を参照)。
従来の合成技術では、主にリアルな唇の動きを得ることに焦点を当てており、顔全体の表情を生成することの重要性を無視していました。今回は、自然な表情に基づいた合成に焦点を当てています。

同じスピーチに対しても笑ってる表情から、怒ってる表情まで豊かな感情表現ができます。また、瞬きや眉毛の動きなども非常にナチュラルです。


モデル概要
(i) 生成器
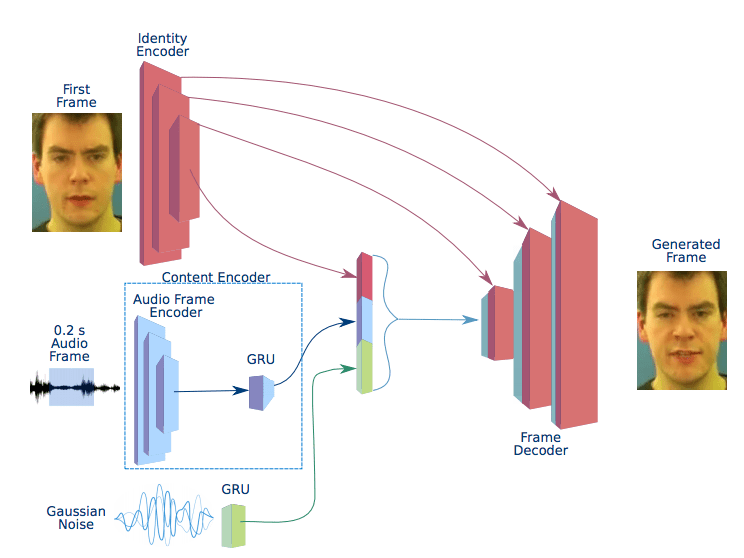
本生成器は、従来のGANと同様に、参照画像とガウスノイズ、さらに音声データを0.2秒区切りにし、それら3つをエンコーダーを通じて符号化し合成したあと、デコーダーにおいて再度画像化し生成を行います。
これらによって生成された画像を自然につなぎ合わせることにより、まるで音声を話している画像のアニメーションを再現します。
(ii) モデル全体図
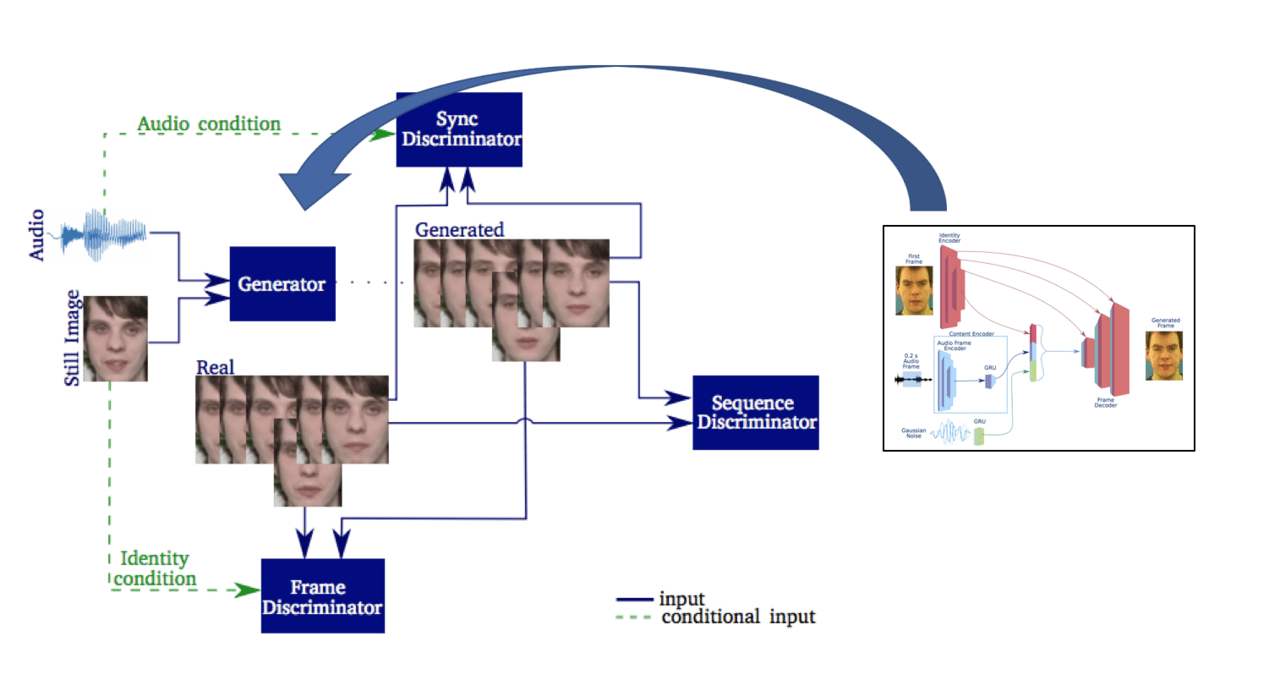
上画像はモデル全体図となります。
生成器の詳細は、(i)で紹介したものとなっており、さらに従来のGANと大きく異なる点は”3つの識別器”を用いる点です。
各識別器には正解を学習させ、生成された画像を1. 顔の輪郭, 2. 自然なアニメーションの繋がり 3.音声と画像の合成度合い の3つの要素で判別します。
1.顔の輪郭と、2.自然なアニメーションのつながりでは従来のGANと同様に、正解データを学習した識別器を通り抜けられるように、本物に近い一連の画像を生成できるよう学習を行います。
3.音声と合成度合いでは、0.2秒ごと切り分けられた音声と画像の音声フレームから特徴量を抽出し、正解データと見分けがつかなくなるまで合成アニメーションの生成を行います。
これらにより、よりナチュラルで高解像度な一連のアニメーションを生成することに成功しています。
結果
以下では、(i)音声情報と画像の合成アニメーション生成, (ii)感情に合わせたアニメーション生成, (iii) 従来モデルとの比較 の3つの視点から本モデルの生成結果を見ていきます。
(i)音声情報と画像の合成アニメーション生成
こちらの動画は、一枚の画像と音声から生成された新しいスピーチアニメーションです。
以下の動画は、100年以上前に生きていたラスプーチンに、ビヨンセの歌を歌わせたものです。
(ii) 感情に合わせたアニメーション生成
正確な唇の形を生成するだけでなく、しかめ面、まばたき、叫び声などの表情を持つ人のアニメーションも生成します。動画では、笑ってる表情から、悲しんでる表情まで繊細な表情を音声に合わせて生成されてることが確認できます。
以下の画像は本モデルを用いて生成された様々な表情の動きであり、上から (b)瞬き (c)しかめっ面 (d)怒りの感情を表しています。すごくナチュラルなのが分かります。

(iii) 従来モデルとの比較
こちらは、従来の顔と音声の合成モデル : Speech2Vidと比較したものです。(a) Speech2Vidでは口の形を作り出すことしかできていないのに対し、(b) 本提案モデルでは、口元だけでなく、目や輪郭まで違和感なく再現されていることがわかります。

また、このモデルで生成されたアニメーションと通常通り人が話しているアニメーションを人間に見分けさせたところ、ほとんど不可能というテスト結果も出ています。
終わりに
今後は、このモデルの制限である正面画像のみしか合成できない欠点を改善し、さらにはより長いビデオと音声から合成を行ったり、多人数が写っている動画に対して適切な音声を組み合わせるアニメーション生成なども期待されます。
こういった技術が発展することで、例えば電話越しにも相手がどんな表情をしているか読み取ることが可能になるかもしれません。さらには、自然言語処理の音声読み上げに感情を加えることができれば、SNSなどの文章から人の表情を予想できる未来も遠くはないかもしれません。



この記事に関するカテゴリー






