ビジュアライズする世界。自動的に改善を提案する視覚ベースの検索アプリケーションが登場
これからますます普及していくであろう視覚ベースの検索法やコミュニケーション。今回紹介する論文では視覚的検索からユーザの意図する画像を検索するだけではなく、熟練していないユーザーても使いこなせる新しいシステムが提案されています。
論文:LiveSketch: Query Perturbations for Guided Sketch-based Visual Search
ビジュアライズする世界
近年、感性によって、マルチメディア・データベースを検索するインターフェースが活発化しています。
特に、2010年に登場したインスタグラムは、いまや世界中で10億人以上のユーザー数に達し、毎日何万もの写真がシェアされているといいます。インスタグラムによって公私の空間をめぐる視覚文化も一段と変容し、言わばそこには<拡張された>視覚空間があります。世界はメディア(技術)の進化によって急速にヴジュアル化してるといえるでしょう。

今回紹介するのは、これからますます普及していくであろう視覚ベースの検索法です。視覚的検索は、コンピュータビジョン、または情報検索コミュニティの中で長年の問題であり、「関連性フィードバック」として広く研究されてきました。今回は紹介するのは、その中でも、手書きの絵から関連イメージを検索するという”直感的”なものです。
ターゲットイメージにたどり着けない問題
スケッチクエリからユーザの意図する画像を検索することにおいては、未解決の課題があります。
たとえば、ユーザーが犬のスケッチを作成すると、米国の地図が返されるとします。この地図は、外見上は描かれた形状(構造)に似ていますが、概念的に関連性はありません。フリーハンドスケッチは大抵の場合、不完全で曖昧な記述になってしまい、ターゲットイメージにになかなかたどり着けないということが起こってしまいます。
本稿では、検索の意図を明確にし、結果の関連性を向上させるために、スケッチされたクエリを自動的に洗練していく反復型の新しい対話型手法LiveSketch(下図 )を提案しています。
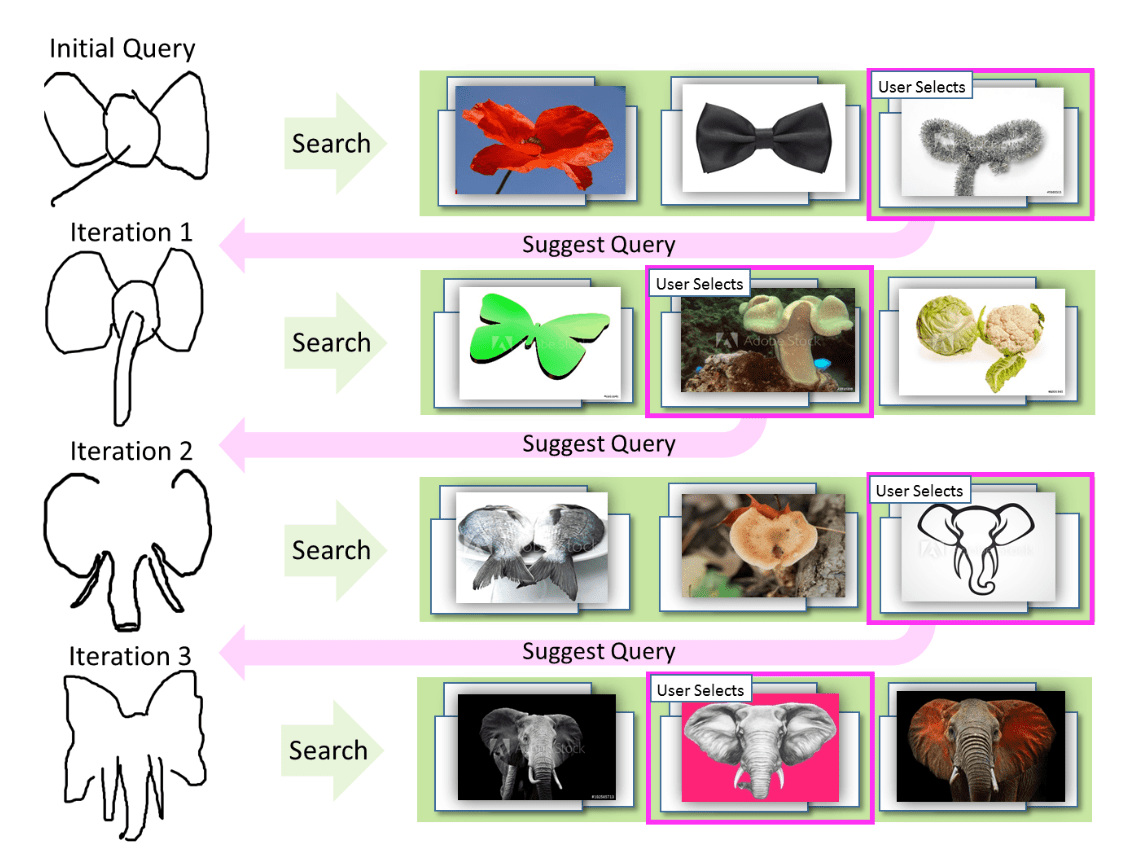
図1: 例えば、検索において、最初にスケッチされた図形(左上)がユーザーの検索意図と一致しない結果をもたらす可能性があります。LiveSketchでは、検索結果(ユーザーが選んだイメージ)に関連するクラスターに基づいて、システムがスケッチされたクエリの改良を提案し、検索をガイドしてくれます「こう描いた方が、ターゲットイメージに近い検索結果が得られるんじゃないかな〜」とAIが自主的にスケッチクエリを洗練させてくイメージです。この相互作用は、ユーザーの検索意図と一致する結果に向けて検索を明確にし、素早く導いてくれます。
敵対的”摂動”
このアプローチでは、画像特徴を符号化するために使用されるDNNの可逆性を利用しました。探索埋込み内の目的点を識別し、そしてそれらの目的点に写像するようにクエリを更新するといった感じです。
ユーザーの検索の対象となる可能性のあるクラスタを特定し、DNNエンコーダを逆転させ、クエリを適用することで、どのようなスケッチを描けばターゲットイメージを特定できるかを自動的に提案します。
この考えは、Adversarial Exampleに触発されています。これは、画像に”摂動(小さな攪乱・ずれ)”を加えることで、オブジェクトを任意のターゲットカテゴリに誤分類させるというものです。
Adversarial Exampleを作成するための一般的な考えは、人間の目には知覚できないと期待される微調整された摂動(小さな攪乱・ずれ)を、正しく分類された自然画像に追加することでモデルに間違った答えを出力させるように誘導することです。いくつかの研究では画像上の人工的な摂動(小さな攪乱・ずれ)がDNNの誤分類を容易にすることができることを明らかにしています。
今回の視覚的探索の文脈では、ユーザによって選ばれたイメージを手書きスケッチの外観に組み込むためにユーザの手書きスケッチを”摂動”させるという反復戦略を提案します。ユーザのスケッチしたクエリを、選択されたイメージに近づけるようにシフトするクエリ摂動としてキャストし、DNNを通して逆伝搬させることによりアップデートを促すスケッチを生成します。
これにより、クエリはキャンバス上の 「生きたスケッチ」 となり、ユーザが表現した意図に対してインタラクティブに反応し、その後の検索反復を形成することができます。
インタラクティブ検索の概要
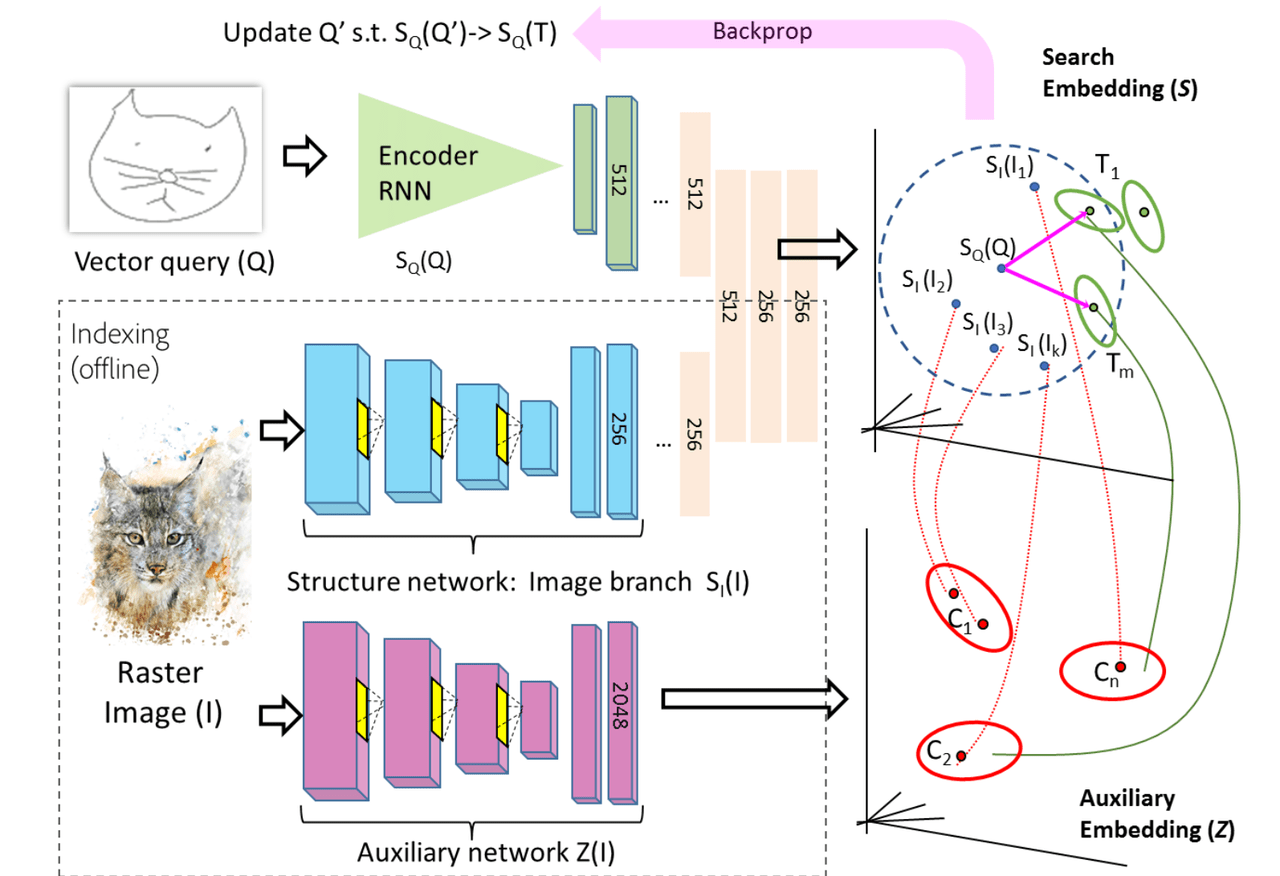
上図 は、インタラクティブ検索の概要を示しています。スケッチと画像コンテンツはそれぞれRNNとCNN分岐を介してエンコードされ4つの完全に接続されたレイヤを介して統合され、検索埋め込みSに符号化されます。最初のスケッチQが与えられると、ユーザーから高い評価を得たターゲットイメージを組み込んだ次の検索反復を導くためのスケッチ提案(Q’)を形成します。これらの画像はQの視覚的構造を共有していますが、セグメントと意味的に多様なコンテンツをふくんでいます。
パフォーマンス
QuickDraw50MデータセットとAdobe Stockからの67Mのストックフォトとアートワーク画像(Stock67M)のコーパスを使ってLiveSketchのパフォーマンスを評価します。

インスタンスレベルの検索ターゲットを取得するための平均時間と、 右の括弧は失敗した検索の確率です(一定の時間を超えてもターゲットイメージにだどり付けなかった時は”失敗”とみなします)。
ユーザーは特定のポーズまたは視覚的属性を持つ特定のオブジェクトを検索するように促されました(「3つの尖塔を持つ教会」、「サメが泳いでいる側面図」など)。ユーザがターゲットイメージが見つかったことに自信があるときに終了します(自己評価)
失敗率は突出して低いというわけではありませんでしたが、LiveSketchは、画像コーパスに対して検索時間を著しく短縮することを示しています。システムが繰り返し自主的に提案していくことで、ターゲットイメージにより早く近づけることが分かりました。
このようなビジュアル検索でのクエリ詳細化のために敵対的な”摂動”を用いるのは非常にユニークなアイデアではないでしょうか。



この記事に関するカテゴリー






