从对抗性攻击的角度看普通和医学图像分类模型的差异
三个要点
✔️研究基于深度学习的医学图像分析的对抗性攻击问题
✔️由于医学图像和DNN模型的特点,医学图像分类模型非常容易受到对抗性攻击。
✔️令人惊讶的是,对医学图像的对抗性攻击的检测非常容易,实现了超过0.98的检测AUC。
Understanding Adversarial Attacks on Deep Learning Based Medical Image Analysis Systems
written by Xingjun Ma, Yuhao Niu, Lin Gu, Yisen Wang, Yitian Zhao, James Bailey, Feng Lu
(Submitted on 24 Jul 2019 (v1), last revised 13 Mar 2020 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Image and Video Processing (eess.IV)
code:
研究概要
最近,人们发现了一种针对人工智能模型的对抗性攻击。在这种攻击中,人工智能模型的输入数据被修改,使人工智能模型产生不适当的输出。在这个领域已经有了大量的研究。然而,大多数被考虑的数据集都是通用图像。因此,作者专注于医学图像作为数据集,以了解对抗性攻击在不同数据集上的表现。
在本文中,我们研究了医学图像的对抗性攻击的性质,并表明医学图像分类模型非常容易受到对抗性攻击。我们还表明,虽然医学图像分类模型容易受到对抗性攻击,但它们却出奇地容易被发现。作者认为,普通和医学图像分类模型之间的这些差异是由于医学图像和DNN模型的特性造成的。
相关研究
什么是对抗性攻击?
对抗性攻击是指操纵输入数据以导致目标模型产生不正确输出的攻击。攻击是通过向输入数据添加噪声,称为对抗性扰动来进行的。更多细节,请参考以下文章。
医学图像分析
大多数诊断方法是基于将眼科、皮肤科、放射科等的各种图像输入CNN并学习其特征。这里使用的CNN是当时的技术水平,如AlexNet、VGG、Inception和ResNet。虽然这些方法和标准的计算机视觉物体识别一样做得很好,但它们被批评为缺乏透明度。由于基于深度学习的模型的性质,目前很难验证推论,而敌对样本的存在可能会进一步削弱对模型的信心。
对医学成像的敌对攻击的分析。
现在我们将展示对DNN模型的攻击结果,该模型在对付医学图像方面已经显示出一定的成功。
设置攻击
我们假设有以下四种类型的攻击。
- FGSM
- BIM
- PGD
- 妇产科
所有这些攻击都是在设定了要放在数据上的噪声的大小后产生对手的样本。因此,如果攻击即使在小的噪音下也能成功,那么攻击者就被认为是脆弱的,反之,如果攻击只有在大的噪音下才能成功,那么攻击者就被认为是强大的。
二元分类数据集的结果

二元分类数据集的结果如上所示。正如一般预期的那样,当加入大的噪声时,准确度会明显下降,就像对正常图像那样。然而,对于正常的图像数据,如CIFAR-10和ImageNet,攻击成功的噪声大小为$epsilon = frac{8}{255}$,因此,以$epsilon = frac{1}{255}$成功攻击的医学图像是相对脆弱的。这意味着医疗图像相对脆弱。
多层次分类数据集的结果。
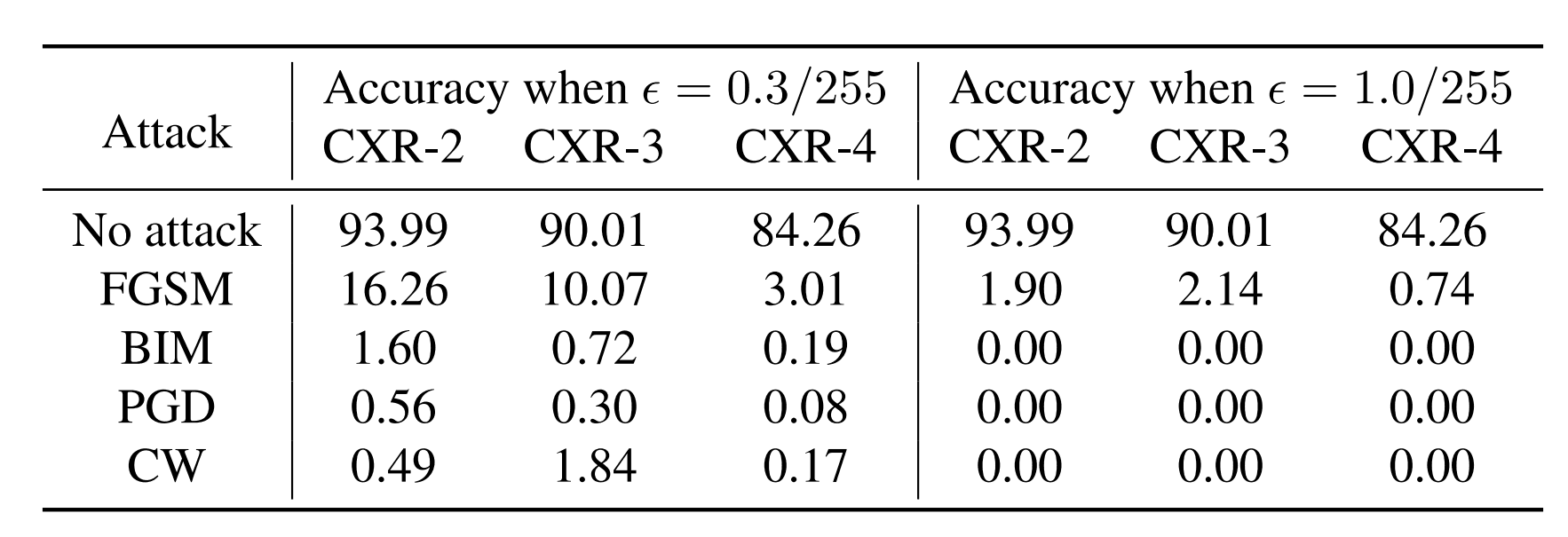
多级分类数据集的结果如上所示,其中CXR-2和CXR-3中的数字代表类的数量。因此,CXR-2是二元分类,CXR-3是三元分类。类的数量越多,攻击的成功率就越高。当相互比较相同的噪声大小时,可以看出,类别越多,准确率就越低。在我们的医学图像数据集中,即使是很小的$epsilon = frac{0.3}{255}$的值,攻击也能成功,这表明医学图像非常脆弱。
为什么医学图像比ImageNet图像更脆弱?这是一个非常有趣的事实,因为图像大小是一样的。我们现在将更深入地讨论这一现象。
为什么医疗模式如此脆弱?
医学图像分析

上图显示了正常图像和医疗图像的显著性图。在正常图像中,高显著性区域集中在一个小区域,但在医疗图像中,它分布在一个宽广的区域。由于敌意攻击会给整个图像增加噪声,所以当噪声大小相同时,医疗图像在高突出区的噪声比例会更大。人们认为这导致了医疗图像容易受到敌意攻击。然而,我们不能得出结论说这是完全的原因,因为也有一些正常的图像具有这种突出性图。
DNN模型的分析
在医学图像上执行任务的DNN的结构是基于已经在正常图像上获得巨大成功的网络结构,如ResNet。我们将表明,这些网络对于简单的医学图像分析任务来说过于复杂,这是漏洞的一个来源。

上图中的第三行显示了在ResNet-50的中间层学到的表示。令人惊讶的是,我们可以看到,医学图像的深度表示比正常图像的表示简单得多。这表明,在医学图像中,DNN模型从一个大的兴趣区域学习简单的模式,也许只与病变有关。
在上面的讨论中,我们已经看到,我们只需要学习简单的模式来进行医学图像分析。复杂的DNN模型不需要学习简单的模式。因此,作者决定调查单个输入样本的损失分布,以了解高脆弱性是否可归因于使用了一个过度参数化的网络。

上图直观地显示了输入图像的损失分布。正常图像显示出温和的损失分布,而医学图像显示出相对陡峭的分布。医学图像很容易受到对抗性攻击,因为损失值很大,除非损失急剧下降。这是由于使用了一个对任务来说参数过高的网络造成的。
因此,如果我们从DNN模型的角度考虑医学模型的脆弱性,我们可以看到,这是由于使用了过度参数化的模型。
医学图像上的攻击检测

上图显示了敌意样品检测的流程。我们使用医学图像分类模型的中间特征来创建分类器。结果如下。

对三个不同的数据集(眼底镜、胸部X射线和皮肤镜)的四种不同攻击的结果显示。在大多数情况下,正常图像的AUC小于0.8,而医疗图像的AUC则更高。特别是在基于KD的探测器的情况下,它是对于所有的数据集和攻击都有非常高的AUC,DFeat是只使用深度特征的情况,但即使在这种情况下,它也取得了非常高的AUC,表明深度特征对于敌对和正常样本可能有根本的不同。
深度特征分析

为了比较正常和敌对样本的深层特征值,使用t-SNE进行可视化的例子如上图所示。在这个可视化中,我们可以看到,正常样本和敌对样本之间的特征值有很大的差异。在正常图像数据集的情况下,即使使用t-SNE也很难像这样干净地分开,所以我们可以看到,医学图像的深层特征具有不同的属性。
摘要
在本文中,我们研究了医学图像分类模型对对抗性攻击的脆弱性。结果,我们发现医学图像分类模型比普通图像分类模型要脆弱得多。然而,我们也发现,医疗图像的攻击检测比正常图像更容易,这是由于医疗图像的对抗性样本和正常样本的深层特征比正常图像更容易分类。这些发现大大有助于确保医学图像分析模型的可靠性。



与本文相关的类别






