如何防止对抗性训练中的过度拟合?
三个要点
✔️调查了正常训练和对抗性训练的错误行为差异
✔️发现过度拟合是对抗性训练的主要现象。
✔️表明,在对抗性训练中,提前停止对过度适应是有效的。
Overfitting in adversarially robust deep learning
written by Leslie Rice, Eric Wong, J. Zico Kolter
(Submitted on 26 Feb 2020 (v1), last revised 4 Mar 2020 (this version, v2))
Comments: Accepted to arXiv.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:

首先
近年来,人们已经知道过度拟合可以通过深度学习中的Double Descent等现象来抑制。然而,在对抗性训练(Adversarial Training)这种针对对抗性扰动的鲁棒性方法中,我们发现过度拟合是一个主要的现象,这与普通深度学习不同。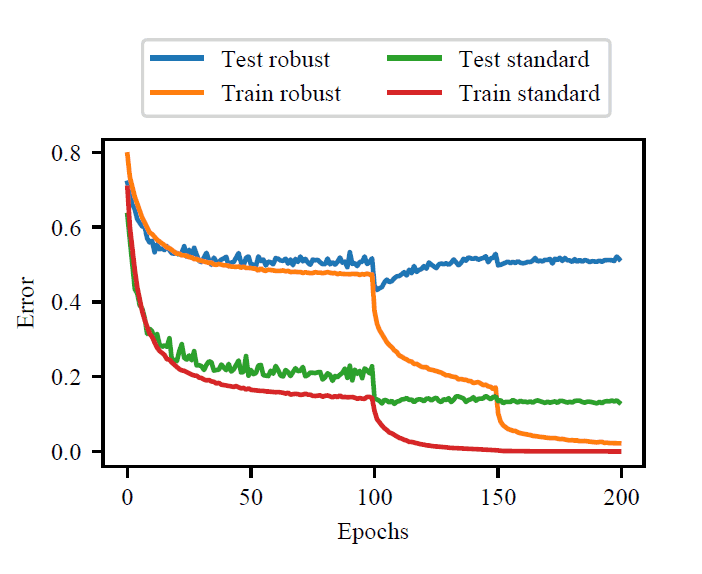
如上图所示,在CIFAR-10的训练实例中,我们可以看到,在普通训练(Train standard,Test standard)中会出现Double Descent,但在Adversarial Training(Train robust。在对抗式训练(Train robust,Test robust)中,训练数据(Train robust)的损失持续减少,而测试数据(Test robust)的损失在某一时刻后增加。从这个例子中,我们可以确认,当进行对抗性训练时,会出现过拟合。
我们发现,在对抗性训练中,提前停止是处理这种过度适应的最有效方法。我们通过与其他正则化方法的比较,表明早期停止是最有效的方法。
什么是对抗性扰动?
敌意扰动
对抗性例子是设计成被判别模型误认的输入数据。这些对抗性的例子是通过在正常数据中添加噪声来创建的。这种噪音称为对抗性扰动,人们设计了各种制造噪音的方法。添加噪声的目的是使数据被误认,即增加将数据归入正确类别的误差。这可以表述为:
$$ max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i}) $$
其中$l$代表损失函数。如这个方程所示,我们可以通过找到一个当模型$f_{\theta}$将数据$x_{i}$与$y_{i}$识别时,损失最大化的扰动$\delta$来创建一个敌意扰动。解这个方程,我们可以建立一个对立样本,但如果样本是人眼已知的对立样本,那就不好办了,所以通常会在上述优化问题中加入约束条件,尽可能地增加小的扰动。这里衡量扰动的"小"有多种方法,但常见的是将L1规范、L2规范、L∞规范等定义为扰动的大小,在减小扰动大小的同时解决上述优化问题。
对抗性培训
对抗性训练是一种使网络对对抗性扰动具有鲁棒性的学习方法。除了正常的训练数据外,还可以在对抗性样本上训练网络,即对抗性扰动产生的数据,从而提高鲁棒性。形式上,网络的参数$\theta$由以下规则更新。$$ min_{\theta}\Sigma_{i}max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i}) $$内优化问题,$max_{\delta \in \Delta}l(f_{\theta}(x_{i} + \delta), y_{i})$是创建对抗性扰动时要解决的优化问题,对抗性训练这就是所谓的对抗性训练。
实验
在对抗式训练中,有几种可能的正则化方法来防止过拟合。在本文中,除了提前停止外,我们还研究了L2正则化和数据增强作为候选人。
结果摘要
在详细介绍之前,先对结果进行总结。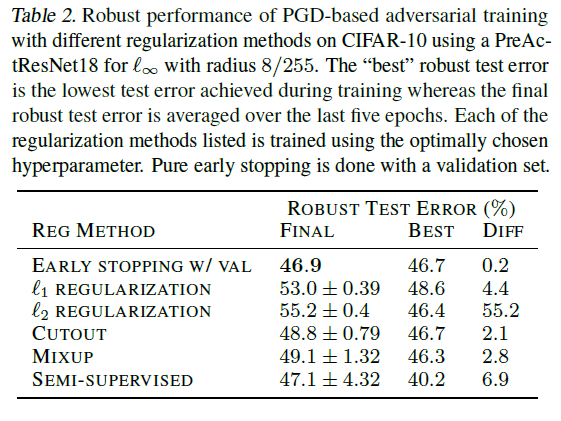
该表显示,提前终止的稳健测试误差最小。
提前终止
早盘涨停的问题之一是根据什么来涨停系统。因此,我们为训练数据、验证数据和测试数据建立了学习曲线。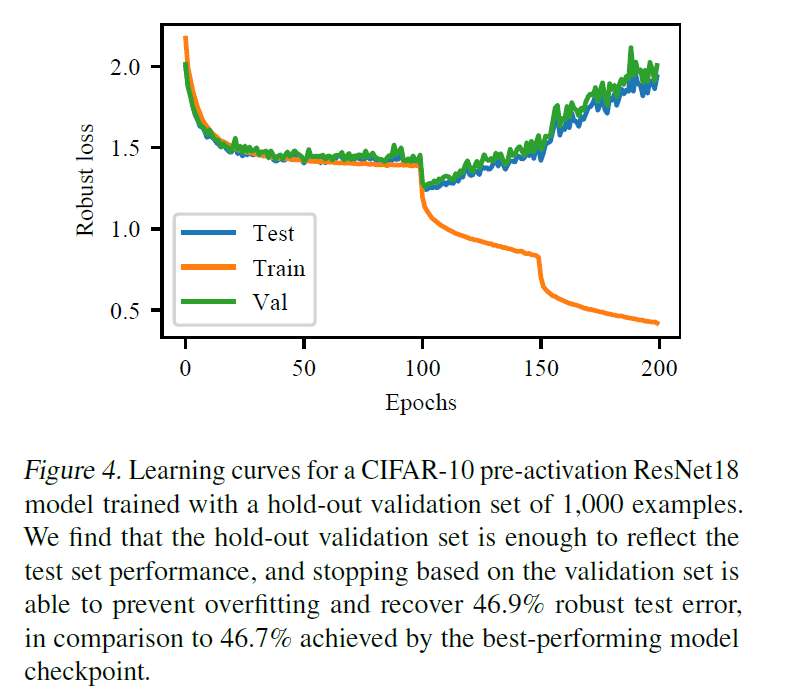
根据这个学习曲线,我们可以看到,验证数据和测试数据的损耗变化几乎是一样的,所以我们如果在验证数据的损耗开始增加的时候提前终止,就可以降低测试数据的损耗。
二级正则化
随着L2正则化强度的变化,测试数据的鲁棒误差(有敌意样本的测试数据误差)如下图所示。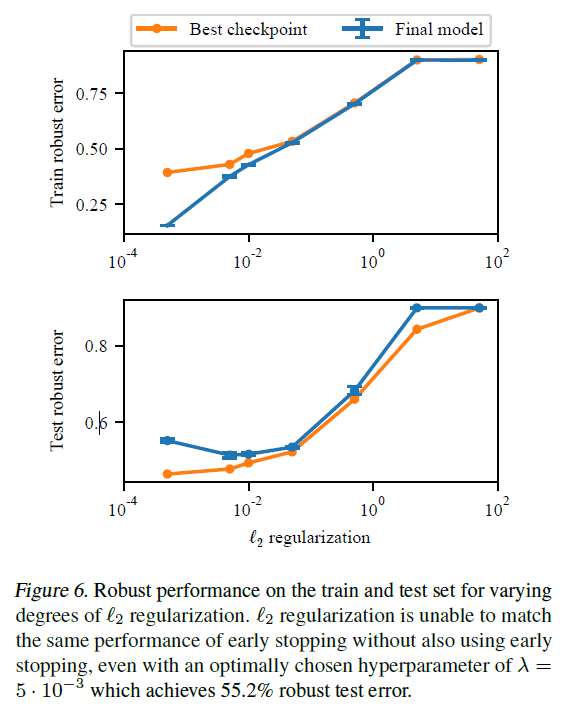
在超参数的最优选择下,我们在测试数据上实现了55.2%的稳健误差。然而,这一结果并不延伸到提前终止。
增加数据
我们考虑三种数据增强的方法:切出、混杂和半监督学习。
镂空
随着长度(Cutout的一个超参数)的变化,稳健误差的变化如下。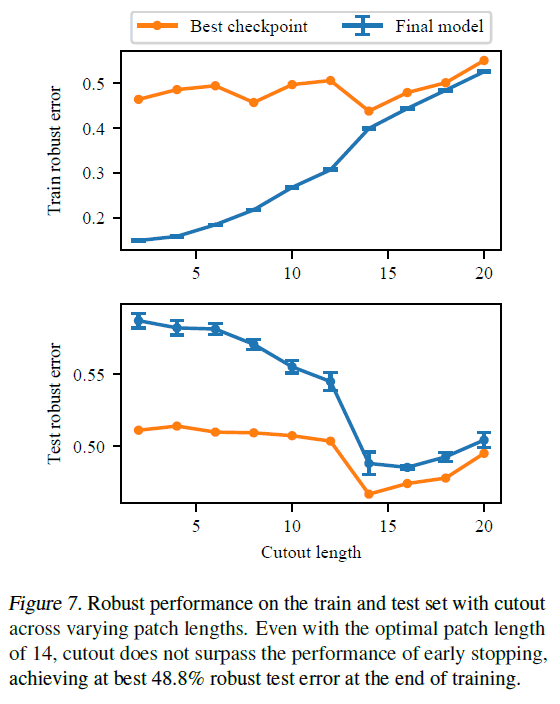
对于Cutout来说,当Cutout长度设置为14时,最好的成绩是48.8%,说明这也不如提前终止。
混搭
当在Mixup中改变超参数时,结果如下。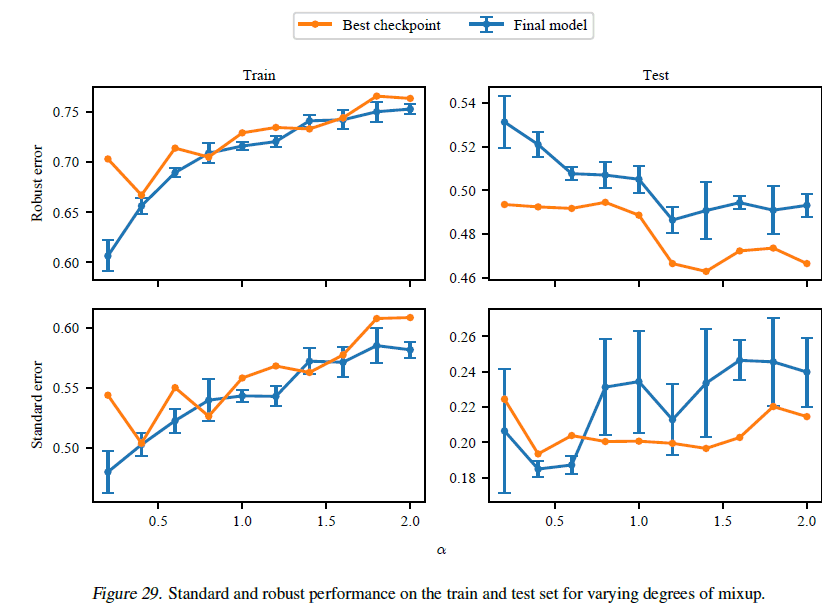
从图中可以看出,即使改变超参数,Mixup也不会提前终止。我们也可以看到,结果有一定的差异性。
半监督学习
如果我们用半监督学习中的标签来增加训练数据,我们会得到
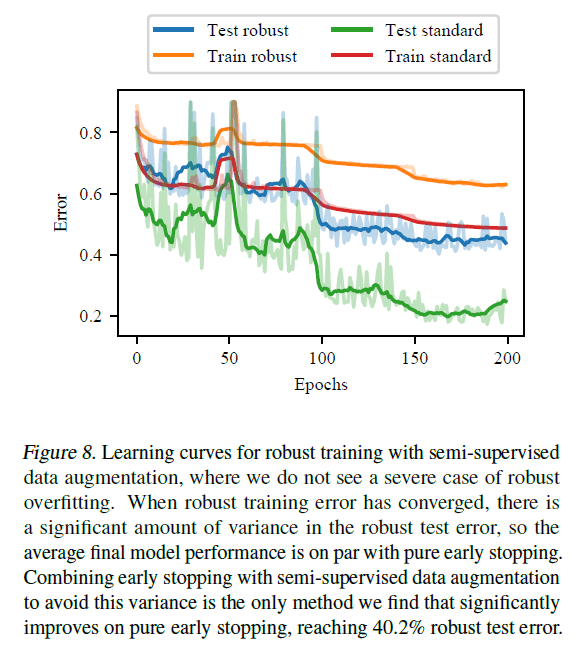
半监督学习的数据增强是唯一一种平均表现与早期终止一样好的方法,不过结果的高方差是个问题。将数据增强与半监督学习和提前终止相结合,在测试数据上的稳健误差为40.2%,比单纯的提前终止有明显的提高。因此,虽然半监督学习的数据增强与自身相比不如提前终止,但与提前终止结合起来,预计会有明显的效果。
摘要
我们发现,在深度学习中,常规训练和对抗式训练的误差收敛特性是不同的。大多数常用的正则化方法要么过度正则化,要么允许过度拟合。由于过度拟合在对抗式训练中很可能发生,因此使用验证数据仔细检查学习曲线非常重要。



与本文相关的类别