稳健过拟合抑制的平滑方法
三个要点
✔️ 引入两种平滑方法来抑制鲁棒超拟合
✔️ 使用对数平滑法和权重平滑法作为平滑方法
✔️ 成功地同时提高了标准精度和稳健精度
Robust Overfitting may be mitigated by properly learned smoothening
written by Tianlong Chen, Zhenyu Zhang, Sijia Liu, Shiyu Chang, Zhangyang Wang
(Submitted on 29 Sept 2020 (modified: 25 Feb 2021))
Comments: Published as ICLR 2021 Poster
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:
研究概要
对抗性攻击是一种针对深度学习模型的攻击技术。这种攻击被称为对抗性实例,即在正常数据的基础上给模型输入小的噪音,使其分类错误。为了防止这种攻击,一种叫做 "对抗性训练 "的学习方法被认为是有效的,它是在正常的训练数据之外,提前训练对抗性实例,以便对抗性实例能够被正确分类。我们的想法是要能够正确地对对抗性实例进行分类。
虽然这种对抗性训练取得了一定程度的成功,但它也有一个缺点,就是容易出现过拟合(称为鲁棒过拟合)。为了防止鲁棒过拟合,作者引入了两种平滑方法,成功地同时提高了标准精度和鲁棒精度。
相关研究
对抗性攻击和反措施
对抗性攻击是通过对输入到模型的数据增加一些处理来误导模型的输出的一种攻击。
针对对抗性攻击的一个著名对策被称为对抗性训练。它通过不仅用正常数据而且用对抗性样本进行训练来提高模型的稳健性。
欲了解更多信息,请参见下面的文章。
https://ai-scholar.tech/articles/adversarial-perturbation/Earlystopping
本文介绍了与本文相关的一项研究,该研究表明早期终止能有效防止Robust Overfitting。
对数平滑
对数平滑是指对分类模型中的输出概率分布进行平滑处理。在本文中,我们使用知识提炼法对Logit进行平滑处理,与教师的预训练模型相同。这是受论文的影响,标签平滑是一种已知的对数平滑方法,是知识提炼的特殊模式之一。
重量平滑化
在本文中,我们使用一种叫做随机权重平均法(SWA)的方法来平滑权重。这种方法是一种叫做快速几何组合(FGE)的方法的近似值。
FGE是一种提高模型泛化性能的方法。80%的模型已经被训练过,剩下的20%使用独特的学习率调度进行训练。在训练剩余20%的过程中,基于原始调度的学习率在大值和小值之间摇摆了好几次。我们在学习率达到最小值的时候存储模型的权重,当所有20%的模型都被训练过后,就用这些权重来训练集合体。这种方法是基于这样的发现而设计的:损失函数的局部解决方案可以通过一条简单的曲线连接起来,而不会过多地改变损失的数值。
SWA是一种克服FGE缺点的方法,即它需要多个模型进行预测。重量。
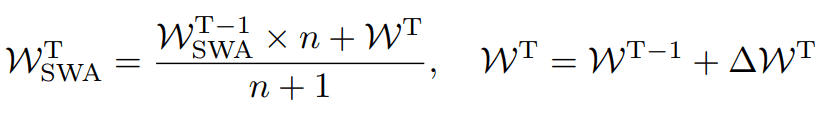
通过这种方式,我们可以通过更新FGE的规则来近似估计它的性能。由于这种方法不涉及合集,它消除了对多个模型的需求,降低了预测的计算复杂性。
建议的方法
对抗性训练中的Logit平滑化
作者认为,Robust过拟合的部分原因是在对抗训练的早期阶段产生的对抗例证过拟合。因此,作者使用logit平滑法来防止对初始Adversarial实例的过度拟合。具体来说,学习是通过解决以下优化问题来进行的。
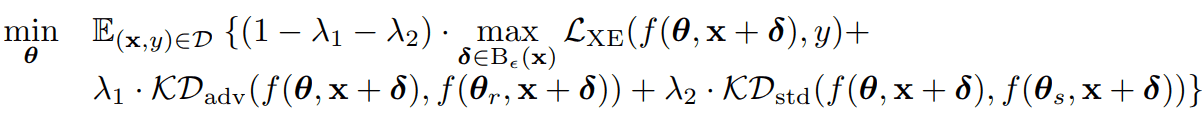
我们将损失函数定义为三个损失函数的加权和:普通对抗性训练的损失函数(第一项),由对抗性训练模型监督的知识蒸馏的损失函数(第二项),以及由正常训练模型监督的知识蒸馏的损失函数(第三项)。损失函数被定义为三个损失函数之和。通过使用这个损失函数,我们可以用其他两个正则化项(知识提炼的损失项)来正则化普通对抗训练。
逆向训练中的权重平滑
对于权重平滑,我们使用SWA,它可以直接用于对抗性训练,和
你可以通过简单地将这个表达式纳入你的更新规则来实现这一点。
实验和分析
标准和稳健的准确性
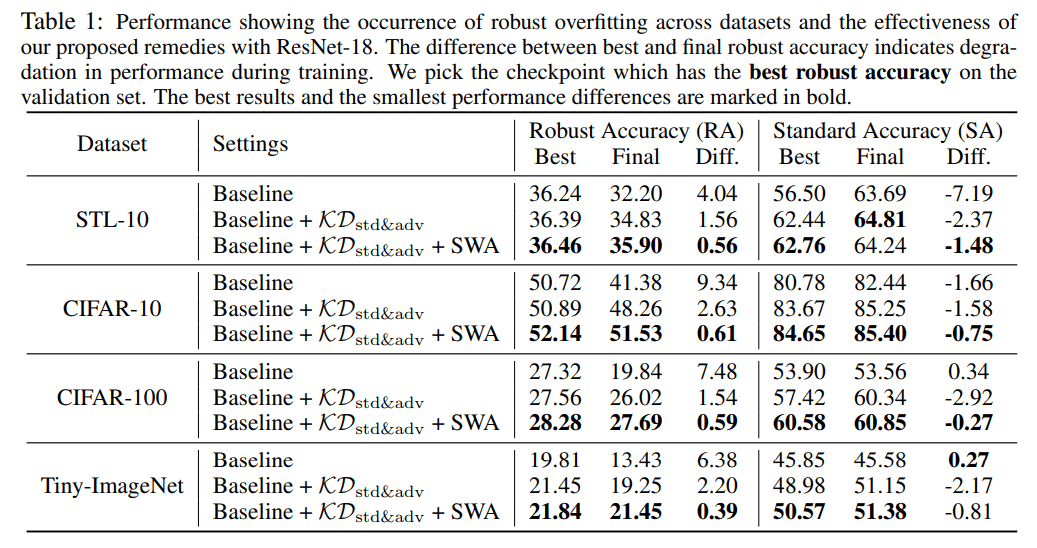
对于所有的数据集,采用建议的方法的模型取得了最高的稳健准确性。大多数的标准精度也达到了最高精度。
不同攻击方法时的准确度
我们准备了三种攻击方法,PGD、FGSM和TRADES,每种方法的准确度如下。
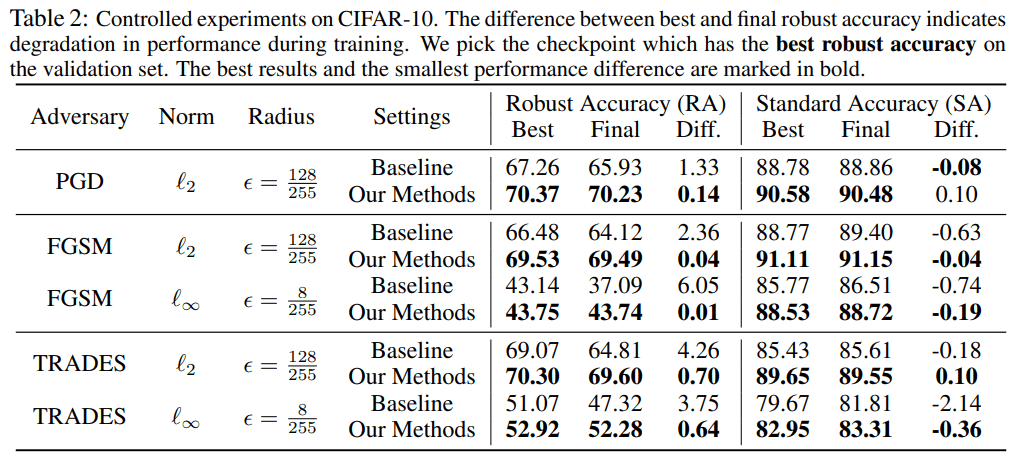
对于所有的攻击方法,拟议的方法在鲁棒性和标准准确性方面取得了比基线更高的数值。
不同架构上的准确性
对于VGG-16、WRN-34-4和WRN-34-10这三种架构,使用CIFAR-10和CIFAR-100两个数据集时的准确度如下。
所有的架构都取得了高于基线值的成绩,同时具有稳健和标准的准确性。
平滑化分析
对数的平滑化
下图显示了如何通过使用t-SNE的对数平滑法来捕捉数据。
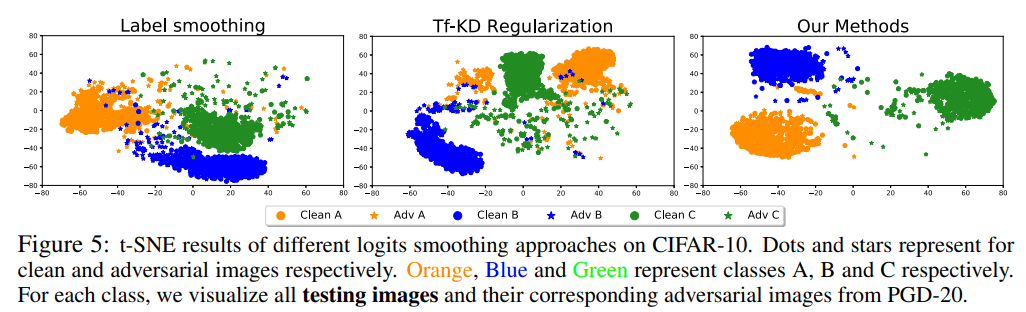
与其他logit平滑方法相比,如标签平滑和Tf-KD(无教师知识蒸馏),我们可以看到分离是正确的,包括对抗性例子。
损失函数的平滑化(权重的平滑化)。
我们检查了损失函数是否可以通过使用所提出的方法进行平滑处理,并发现
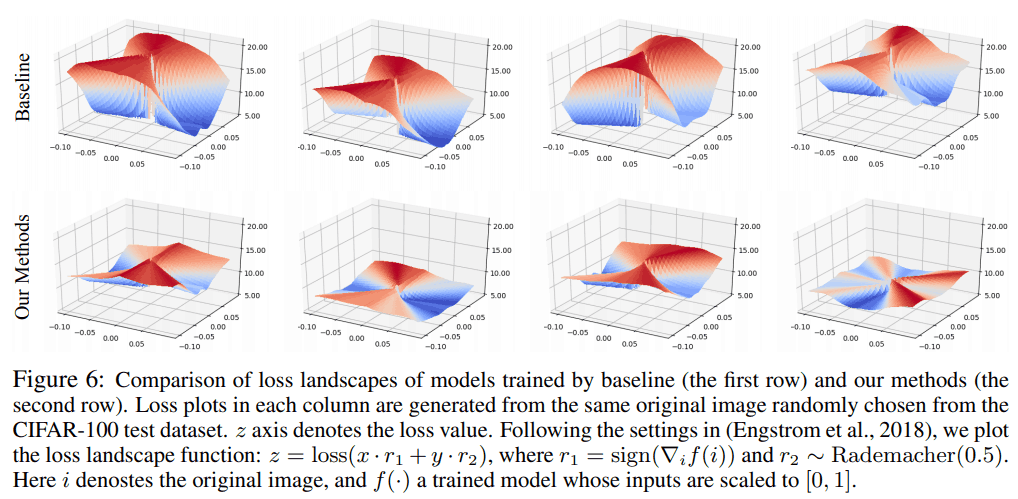
可以看出,在使用所提出的方法时,损失函数被拉平了。
摘要
在本文中,我们提出了两种平滑方法,即Logit平滑和权重平滑,作为防止Robust Overfitting的方法。通过使用这些方法,我们发现,我们可以实现比以前更高的鲁棒性。然而,Robust Overfitting的原理还不清楚,所以需要进一步研究。



与本文相关的类别