如何解决BERT的微调不稳定问题?
三个要点
✔️ 分析基于变压器的预训练模型(如BERT)微调的不稳定性。
✔️ 确定由于梯度消失和广义化差异造成的初始优化困难是不稳定的来源。
✔️ 提出新的基线,提高微调的稳定性。
On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines
written by Marius Mosbach, Maksym Andriushchenko, Dietrich Klakow
(Submitted on 8 Jun 2020 (v1), last revised 6 Oct 2020 (this version, v2))
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)

code:.

首先
基于变压器的预训练模型,如BERT,已经被证明在各种任务上表现良好,并进行了微调。与如此良好的性能相比,BERT的微调并不稳定。也就是说,根据不同的随机种子,任务的表现会有很大的不同。
灾难性遗忘和数据集规模小被推测为这种微调不稳定的原因。在本文介绍的论文中,我们表明,这些假设不能解释微调的不稳定性。
此外,他们还分析了BERT、RoBERTa和ALBERT,表明微调的不稳定性是由两个方面引起的:优化和泛化。此外,根据分析结果,他们提出了一种新的基线,可以稳定地进行微调。
实验
数据集
对于微调的分析,我们使用了如下所示的四个数据集。
- CoLA(语言可接受性语料库):识别特定句子的语法正确性。
- MRPC(Microsoft Research Paraphrase Corpus):给定两个句子,识别它们是否同义。
- RTE(Recognizing Textual Entailment):给定两个句子,它识别我们是否可以推断出如果一个是正确的,另一个也是正确的。
- 问答式自然语言推断(QNLI):给定一个问题和一个句子,识别该句子是否为正确答案(SQuAD数据集的二元分类版本)。
这组数据的统计结果如下:
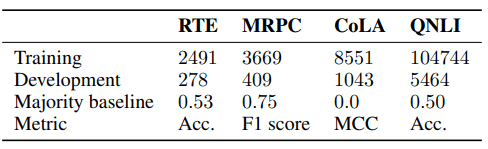
这些都是GLUE任务中包含的基准。在这四者中,以往的工作表明,CoLA的微调特别稳定,RTE特别不稳定。
超参数的设置等。
微调的超参数和模型的设置如下。
- 型号:无壳BERT-LARGE(或RoBERTa-LARGE,ALBERT-LARGE)。
- 批量:16
- 学习率: 2e-5 (在前10%的迭代中,从0到2e-5线性增加,然后线性减少到0)
- 辍学率:$p=0.1$(ALBERT中为0)
- 权重衰减:$\lambda=0.01$(在RoBERTa中为0.1,无梯度剪切)
- 优化器:AdamW(无偏差修正)
之所以采用LARGE模型,是因为它在微调BERT-BASE的过程中不会造成不稳定。
关于微调的稳定性
根据微调过程中性能(F1得分、准确率等)与算法随机性的标准差大小来判断微调的稳定性。
关于执行失败的判断
如果训练结束时的准确率小于或等于每个数据集对应的许多分类器的准确率,则判定微调为"失败"。
关于微调不稳定原因的假说
以往的研究假设,微调不稳定的原因是灾难性遗忘和数据集规模小。
在实验中,首先检验这些假设。
灾难性遗忘是否会诱发微调不稳定?
灾难性遗忘指的是当一个训练好的模型在另一个任务上进行训练时,它在前一个任务上的性能会下降的现象。在本实验的环境中,对应的是BERT等预训练期间,微调后无法正确执行任务(如MLM)。
为了研究这种灾难性遗忘和不稳定性之间的关系,他们进行以下实验。
- 对RTE数据集进行BERT微调。
- 分别选择三个成功的学习试验和三个不成功的试验。
- 对于他们,我们基于WikiText-2语言建模基准的测试集,对MLM(Masked Language Modeling)的迷惑性进行了测量和评估。
- 通过将24层中的上层$k$层($0 \leq k \leq 24$)替换为预训练模型,研究灾难性遗忘和不稳定性之间的关系。当$k=0$时,所有层都是微调模型,当$k=24$时,所有层都是预训练模型)。
本实验结果如下:
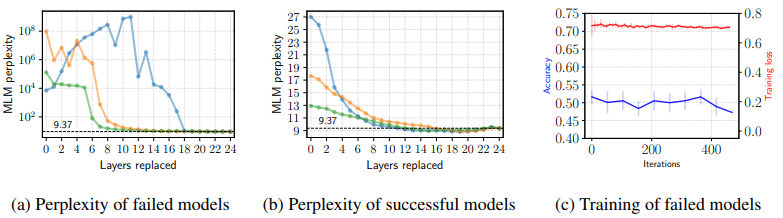
在失败的模型中(左图),可以看到灾难性遗忘确实发生了(注意垂直轴上的数值)。当他们更换除浅蓝色层以外的前10层时,迷惑性有所改善,说明前10层主要受到灾难性遗忘的影响。此外,灾难性遗忘通常应该是由适应新任务引起的。
然而,当微调失败时,训练损失有点小($\simeq -ln(\frac{1}{2})$),虽然准确率很低(右图)。文中指出,这说明微调故障是由优化问题引起的。
数据集的小,是否会造成微调的不稳定?
接下来,为了研究数据集大小与微调不稳定性之间的关系,他们进行以下实验。
- 他们从CoLA、MRPC和QNLI训练集中随机抽取1000个案例。
- 他们用不同的随机种子对BERT进行微调,每个数据集25次。
- 他们用和平时一样的纪元数(3 epochs)和和平时一样的迭代次数进行实验,并比较每种设置下的结果。
目前的结果如下:
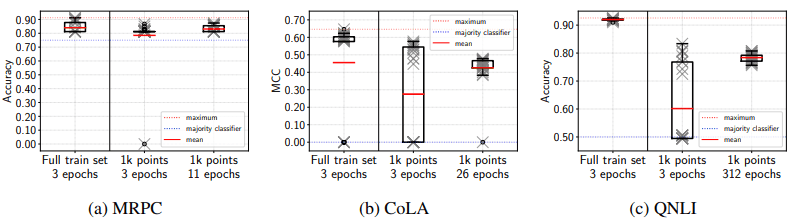
如图所示,当他们像平时一样训练相同数量的epochs(3个epochs)时,CoLA和QNLI失败的频率更高,方差更大。然而,当迭代次数与平时相同时,方差足够小。另外,MRPC和QNLI的失败试验次数减少为0,CoLA的失败试验次数减少为1,显示出与在完整训练集上训练时的稳定性相同。
这说明微调的不稳定性是由迭代次数不够造成的,而不是训练数据量不够。
微调不稳定的原因是什么?
我们的实验表明,灾难性遗忘和数据集大小与微调不稳定相关,但它们不是造成微调不稳定的主要原因。在下面的章节中,我们将进一步探讨导致微调不稳定的原因。
具体来说,我们研究的是(一)优化和(二)泛化。
(一)优化
梯度消失问题
如果微调失败,下面就会出现梯度损失。
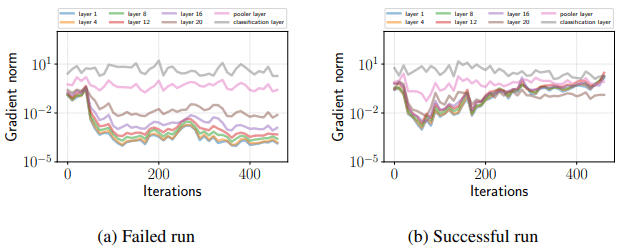
如图所示,在不成功的试验中,除了分类层外,梯度在学习初期变得非常小,并没有恢复到原始状态。另一方面,在成功的试验中,在前70次迭代中,梯度变小,但之后梯度变大,不会出现梯度损失。
在RoBERTa和ALBERT的情况下,同样会出现如下图所示的梯度损失。
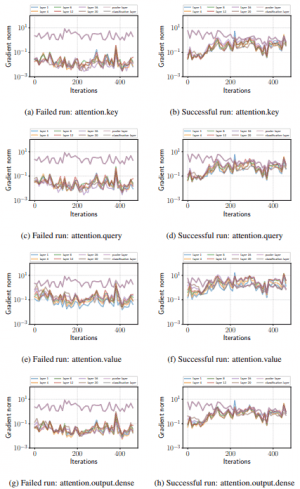
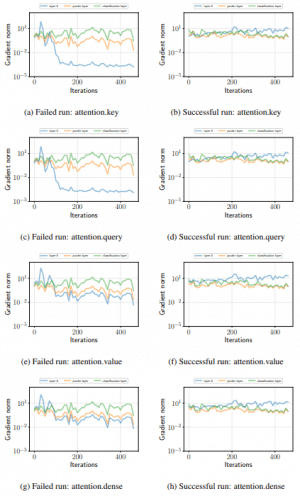
(左:RoBERTa 右:ALBERT)
因此,他们以预期,微调的不稳定性与梯度消失等优化失败有很大关系。
ADAM的偏差校正
BERT微调过程中使用ADAM偏差修正的结果如下图所示。
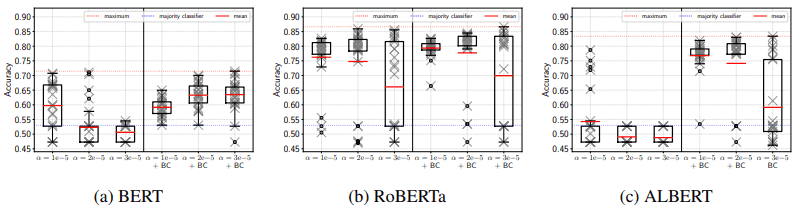
$\alpha$表示学习率,BC表示偏差修正。
如图所示,我们可以看到BERT和ALBERT出现了较大的性能提升,RoBERTa也有一定的提升。因此,ADAM的偏差修正会导致微调时的性能提升。
损失面的可视化
下图为二维表面微调过程中损失的可视化。
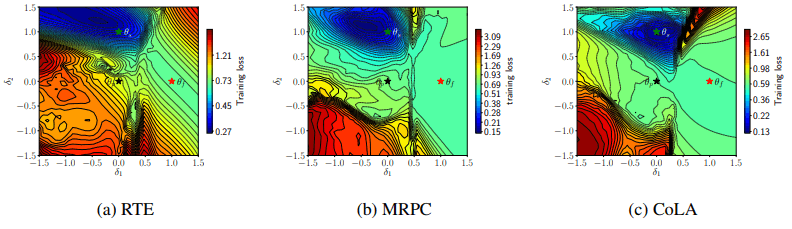
图中的$\theta_p$,$\theta_f$,$\theta_s$分别代表预训练模型、微调失败的模型和成功的模型。线代表等高线(平衡线)。从图中可以看出,失败的模型位于损失较小的区域(蓝色区域),并收敛到与成功模型和预训练模型截然不同的位置(如深谷)。
梯度规范的可视化也如下图所示。
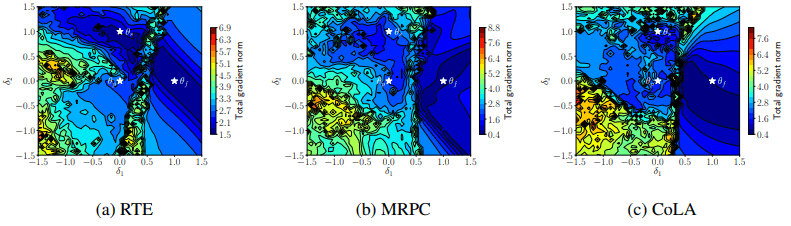
此时,在失败的模型$\theta_f$和其他模型之间有一道密集的等高线组成的山峰屏障,现在这些模型已经被分开了(三个数据集都是如此)。
从这些结果(梯度消失的确认、ADAM偏置校正带来的性能提升,以及从损失和梯度可视化的定性分析),可以预测,微调不稳定可能是由于优化失败。
(二)关于一般化
接下来,我们重点讨论一下微调不稳定和泛化的关系。
首先,在下文中展示了在RTE上对BERT进行微调的情况下,成功试验的开发集(10)的精度。
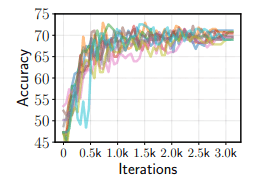
此外,对于在不同设置下进行的450次试验的结果,developing集的准确率和训练损失如下。
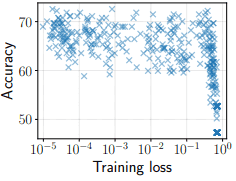
在这个图中,在训练损失$10^{-5}$到$10^{-1}$的范围内,准确率几乎没有变化。换句话说,在微调过程中不会出现过拟合(对训练数据的过度拟合)。因此,即使我们训练到训练损失变得非常小(有大量的迭代),我们也可以预期由于过度拟合而导致的性能下降不会成为问题。
稳定微调的简单基线
鉴于对微调的不稳定性及其与优化和泛化的关系的研究,一个简单的提高稳定性的策略(在小数据集上)将是
- 为了避免学习初期的梯度损失,采用小的学习率与偏差修正。
- 大幅增加迭代次数,训练损失几乎为零。
据此,提出一个简单的基线如下
- 使用ADAM进行偏置校正,学习率设置为2e-5。
- 训练进行了20个纪元,前10%的学习率呈线性增长,之后衰减为0
- 其他超参数不变。
结果
根据以上基线,运行结果如下图所示
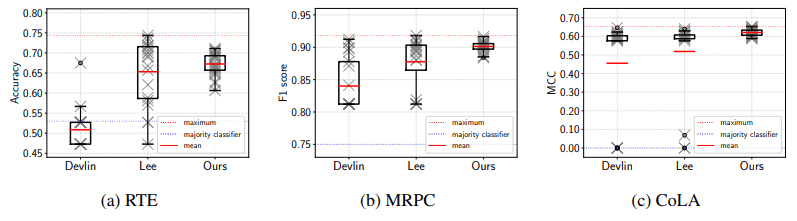
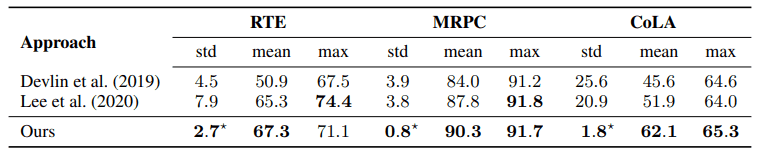
研究表明,与BERT论文中提出的默认设置和最近的改进方法Mixout相比,所提出的方法在最终性能和标准差方面产生了更稳定的微调。
摘要
在本文介绍的论文中,他们证明了BERT中微调的不稳定性是由两个方面造成的:优化和泛化。此外,根据这些分析结果,提出了一个稳定微调的简单基线。
BERT和其他基于Transformer的预训练模型都表现出非常好的性能。提高这些模型的微调稳定性是一个严峻的挑战。因此,本研究非常重要,因为它分析了微调不稳定的原因,并指出了稳定学习的有效方法。



与本文相关的类别






