![[MuLan] 使用对比学习的多模态音乐-文本。](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan.png)
[MuLan] 使用对比学习的多模态音乐-文本。
三个要点
✔️ 通过对比学习实现音乐-文本多模态
✔️ 使用两个编码器为音乐添加文本
✔️ 使用文本进行音乐搜索和标记的高精度命中率
MuLan: A Joint Embedding of Music Audio and Natural Language
written by Qingqing Huang, Aren Jansen, Joonseok Lee, Ravi Ganti, Judith Yue Li, Daniel P. W. Ellis
(Submitted on 26 Aug 2022)
Comments: To appear in ISMIR 2022
Subjects: Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Sound (cs.SD); Machine Learning (stat.ML)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
最近,人们对用自然语言解释和分类数据进行了大量研究。具体来说,这种想法是用文字来描述图像和声音。例如,图片中的狗可以用文字 "dog "来描述,声音也可以归类为 "birdcall"。
特别是在图像领域,有大量带字幕的图像数据可供使用,这使得学习更加准确。然而,由于缺乏此类字幕数据,语音数据的准确性不如图像。
因此,在本研究中,我们创建了一个名为 "MuLan "的系统,成功地将音乐图像("悲伤 "或 "摇滚")与文字结合起来。这个 MuLan 是一个对比学习模型,用于学习音乐与文字之间的关系。
MuLan 可以高精度地查找音乐信息,并用文字描述音乐。
技术
本研究采用的主要方法是对比分析法("音乐 "和 "文字 "的对比分析法),如下图所示。
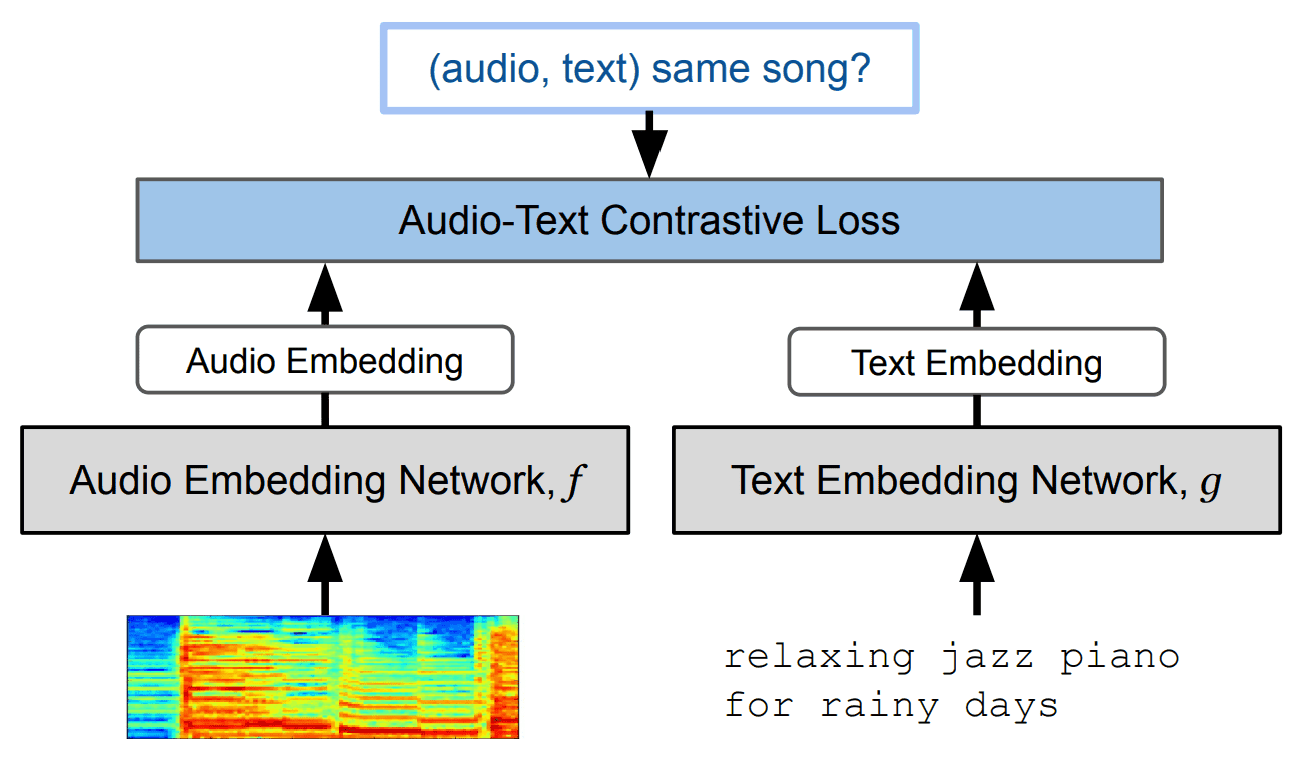
具体程序如下
- 使用 Resnet-50 或 AudioSpectrogramTransformer 对音乐对数-熔点频谱图进行编码。
- 用 BERT 对文本进行编码。
- 利用上述两个嵌入模型,最小化以下损失函数
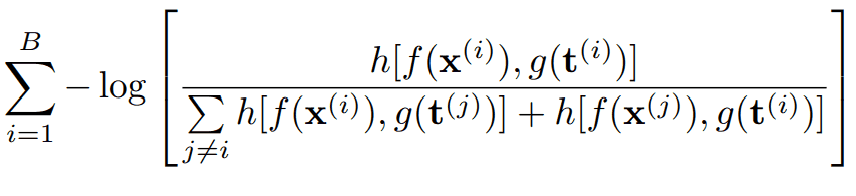
该损失函数的分量分别为
- B: 迷你批量
- f(x):音乐嵌入
- g(t):文本嵌入
- h[a,b]:批判函数
在这里,"音频谱图转换器"(AST)以图像处理领域成功的 "视觉转换器"(ViT)技术为基础。据说 AST 在音频分类方面具有特别高的性能,它使用 12 层 Transformer 处理作为 "标记 "的频谱图。
此外,还使用了 Resnet-50,这表明在音乐数据编码过程中,音乐对数音乐谱图被视为一种 "图像"。
数据集
MuLan 的训练使用的数据集来自互联网上的 5000 万部音乐视频。
语音数据
首先,从网络音乐视频中剪切出 "从第 30 秒开始的 30 秒音频 "作为音频数据。其次,为了确定这些声音是否真的是音乐,舍弃了一半以上不是音乐的音乐数据。因此,数据集的总时长约为 370,000 小时。
字符数据
此外,还使用了以下三类文本数据
- SF:简短文字,如歌名。
- LF:较长的文本,如歌曲描述或观众评论。
- PL: 包含此歌曲的播放列表标题
文本数据示例如下。

在此,我们使用 BERT 对文本进行清理,删除与 LF 和 SF 音乐内容无关的文本。由此得到的文本数据大小如下
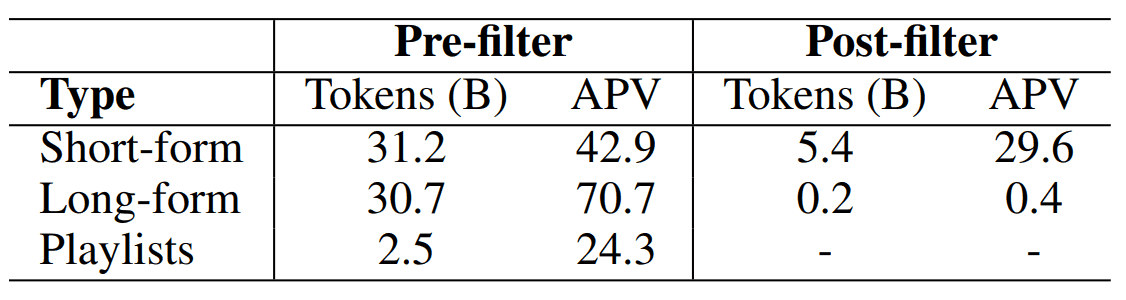
(APV 是每个数据文本注释的平均值,包括没有文本注释的数据)。
音频集
使用名为 AudioSet 的数据集来创建 10 秒钟的音频-文本对,为数据集增加了约 200 万个数据。
这些不同的数据源在规模和质量上差别很大,因此要进行平衡,并以小批量 "微型 "数据的形式混合在一起。
评估实验和结果
在性能评估方面,对四项任务的性能进行了评估
- 标签 零镜头 音乐
- 向上述模式过渡学习。
- 从文本查询中搜索音乐
- 文本编码器评估
至于 MuLan 的音频编码器,如前所述,ResNet-50 (M-ResNet-50) 和 AudioSpectrogramTransformer (M-AST),已分别进行了比较。
让我们依次从方法和结果两个方面来看看。
零镜头音乐标记和过渡学习
这项评估有两个基准
- MagnaTagATune (MTAT)
- 音频集
零镜头音乐标签的预测得分由音乐片段的 "音频嵌入 "与每个标签的 "文本嵌入 "之间的余弦相似度来定义。
在对过渡学习进行评估时,也采用了与以前相同的两个基准。
这些结果如下
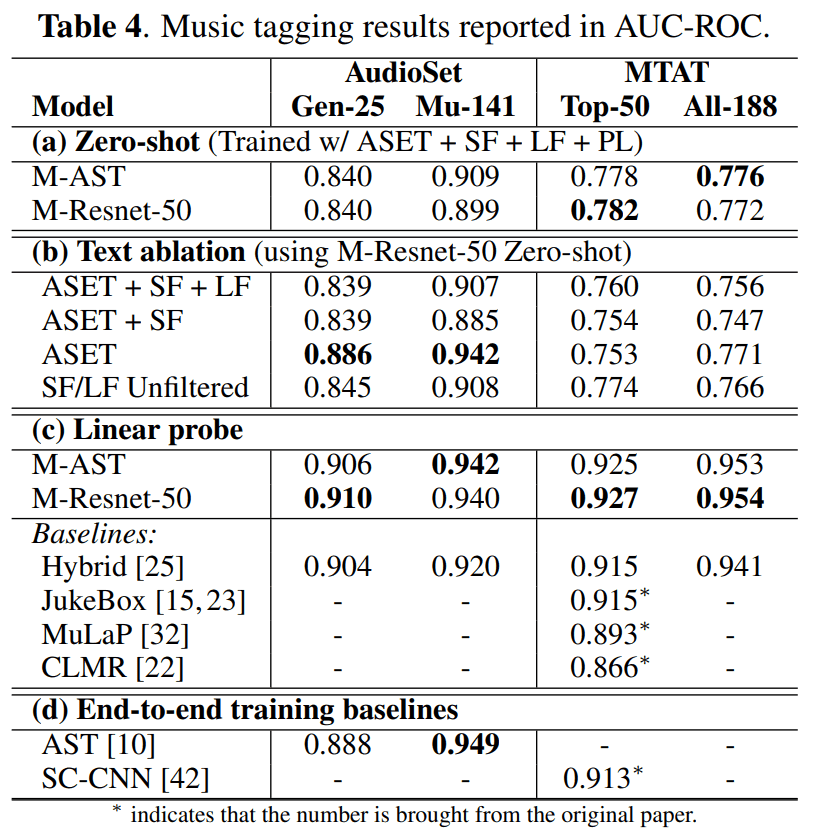
・用零镜头标记音乐的性能
表 4(a) 显示了 "标记零镜头音乐 "的结果。Resnet-50 和 AST 音频编码器显示出相似的性能。
・文本数据过滤的影响
表 4(b) 显示了过滤文本数据对性能影响的结果。可以看出,仅使用 AudioSet 进行训练时,准确率最高。
令人惊讶的是,使用未经过滤的数据进行训练所取得的成绩与经过过滤的情况不相上下。这有可能是文本过滤过度了,而且一些没有明确与音乐相关的判断文本实际上是有意义的。另外,也有可能是使用 MuLan 进行对比学习对噪音有很强的抗干扰能力。
・过渡学习的结果
表 4(c) 显示,当对 MuLan 的语音嵌入进行线性探索时,它在所有标记任务的过渡学习中都取得了最佳性能。
因此,MuLan 的预训练语音编码器可以转用于其他任务。
从文本查询中搜索音乐
评估使用的是 7,000 份专家选择的播放列表,与研究中使用的播放列表信息不重复。每个专家选择的播放列表都有标题和说明,包含 10,100 个音乐录音。
播放列表标题通常是短语,由流派、子流派、情绪、活动或艺术家名称组成。下表中的 "播放列表 "就是一个例子。

这里的指标是 AUC-ROC 和平均拟合率 (mAP)。它们还可以根据余弦相似度进行评估,就像零镜头标记一样。
结果如下
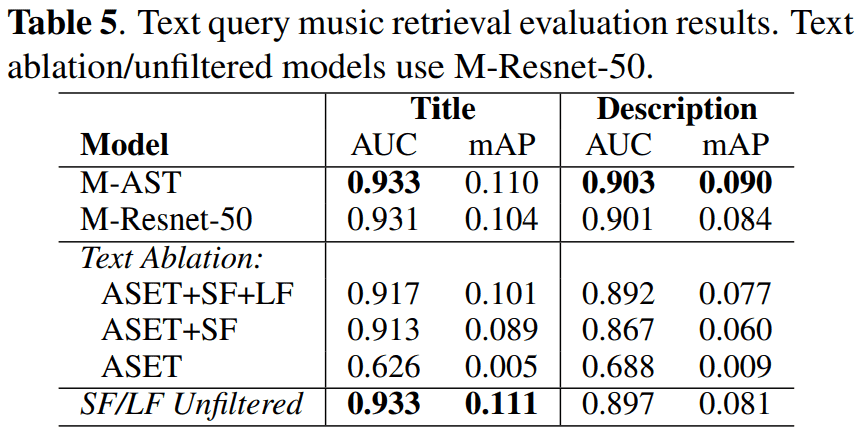
结果表明,在 ASET 中添加 "从互联网检索到的大型 SF "有助于模型学习更精细的音乐概念。此外,加入评论和播放列表数据还能让模型理解更复杂的查询。
同样,未经过滤的文本也表现出色。
文本编码器评估
为了衡量 MuLan 文本编码器与传统的预训练 BERT 模型相比的性能,我们使用三连音分类任务对其进行了评估。
每个三元组由 "锚"、"正 "和 "负 "三个文本字符串组成。在文本嵌入空间中,如果正字符串比负字符串更接近锚点,则被认为是正确的。
本次评估使用了两个数据集
| 数据集 | 目录 |
|---|---|
| 音频集本体 | 对于 141 个音乐相关类别中的每一个类别,我们都使用标签字符串作为锚文本、长格式描述作为正文本、五个随机类别的长格式描述作为负文本,构建了五个三元组 |
| 专家收集的播放列表数据。 |
对播放列表进行采样,并将其标题和描述分别设置为锚文本和正文。 ...负面文本作为另一个随机采样播放列表的描述。 |
数据集内容示例见上表 3。
结果如下
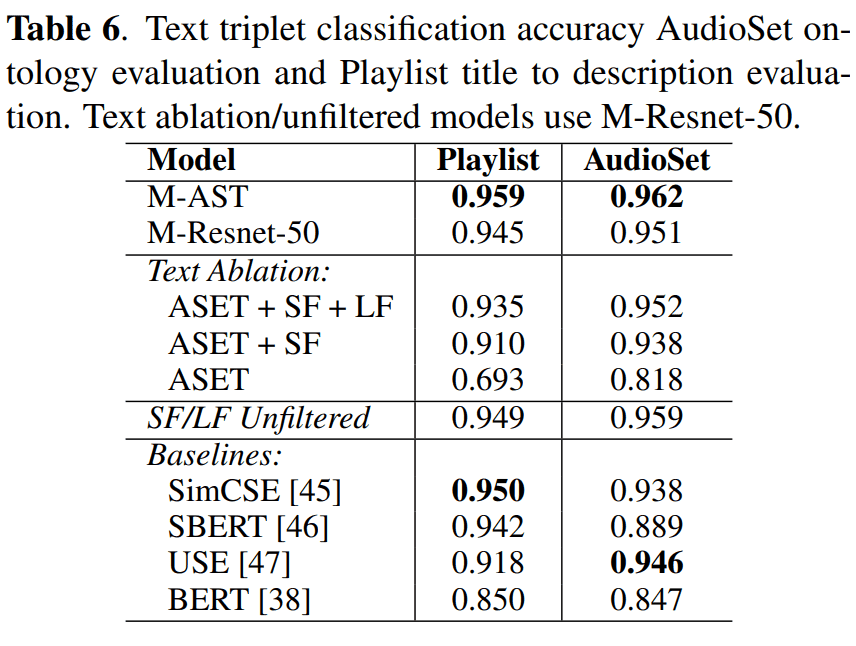
在此对以下四种模式进行比较。
- 句子转换器
- SimCSE
- 通用句子嵌入
- 伯特
结果表明,MuLan 文本编码器的性能优于其他通用模型。在这方面,MuLan 是一种音乐专用模型,因此它在音乐领域的高性能表现本身并不令人惊讶。
不过,在没有使用微调或其他手段的情况下实现 SOTA 是一项了不起的成就。
摘要
本文介绍的 MuLan 也用于 MusicLM,这是一种文本到音乐生成模型。该 MusicLM 模型将文本提示作为输入,并根据其内容生成音乐。
因此,"木兰 "有助于 "将音乐和文本联系起来"。



与本文相关的类别

![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)


