
不同的分辨率特征应该如何连接?:索尼对D3Net的建议
三个要点
✔️ 为需要高密度估计的任务提出一个机制D3块!
✔️ 解决了由扩张卷积和跳过连接引起的混叠问题!
✔️ 在语义分割和来源分离任务中实现了SoTA,并显示了模型的通用性!
Densely connected multidilated convolutional networks for dense prediction tasks
written by Naoya Takahashi, Yuki Mitsufuji
(Submitted on 21 Nov 2020 (v1), last revised 9 Jun 2021 (this version, v2))
Comments: CVPR2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
这里介绍的网络是由索尼提出并被CVPR接受的密集连接的多孔网(D3Net)。D3Net专注于高密度的估计任务,即语义它是一个专注于分割和源分离等任务的网络,这些任务需要估计与输入图像维度相同的维度。最近,有很多关于扩大CNN以接近ViT性能的研究,主要集中在卷积层,如改变核大小和采用可变形卷积(D3Net)来增加感受野。在这种情况下,本方法提出了一种利用扩张卷积(dilated convolution)扩大感受野的有效方法。特别是,它处理高密度的任务,并被设计成非常密集的连接,重点是在多个分辨率下提取特征的重要性,即全局和局部特征的兼容性。
主要贡献如下。
- 论证了多分辨率下密集特征提取的重要性,并提出了一个结合跳过连接和扩张卷积的D2块。
- D2块包含了多分卷积,解决了直接将扩张卷积纳入DenseNet时出现的混叠问题。
- D3区块,它将D2区块纳入一个嵌套结构,并以不同的扩展率进行多次卷积,在每个分辨率下灵活地提取特征。
- 在不同领域任务的密集估计任务(语义分割和源分离)中实现了SoTA,证明了所提方法的通用性。
这篇论文有点老了,但它很有趣,因为它侧重于扩展卷积的混叠,以提高精确度。让我们来看看D3Net。
高密度的估计任务
诸如语义分割和源分离等任务,要求输出与输入维度相同,需要在像素层面进行分类和回归。因此,识别细节部分或信号的局部特征和捕捉整个物体的全局特征都很重要。
自然,全局和局部特征之间存在着一种依赖关系。重要的是,要同时考虑几个不同分辨率的特征,而不是某个特定分辨率的特征。
然而,现有的方法(如FCN、UNet、HRNet)只能将不同分辨率的特征图连接几次(见下文)。本文针对这一问题,论证了同时对多个分辨率的特征进行密集建模的重要性,并提出D3Net。

大图片
D3Net是基于领先的CNN模型DenseNet,它是一个由四层DenseBlocks组成的非常密集的网络,每个块内的所有层之间都有跳过连接。连接允许局部特征保留到后期阶段,最大限度地利用信息,同时减少模型的大小。对于DenseBlocks来说,使用扩张卷积来实现高效的感受野扩展,使用多扩张卷积来解决混叠,使用嵌套结构来实现更灵活的建模,是DenseBlocks的一些主要特征。我们提出了一个更灵活的建模的嵌套结构,即D3 Block,并提出了一个由D3 Block组成的网络,即D3Net。
多分化卷积
让我们从核心要素开始:扩大CNN的感受野是大规模和准确的CNN的一项基本任务。通过扩大感受野,获得了长距离的依赖性,可以捕捉到全局特征,可以充分利用这些特征进行高密度的估计。为了有效地扩大感受野,本文重点讨论了扩张卷积。顾名思义,通过对参数数量相同的内核进行扩张,可以考虑广泛的特征。下图显示了一个图像。通过改变采样间隔,以相同的参数数量扩大感受野。
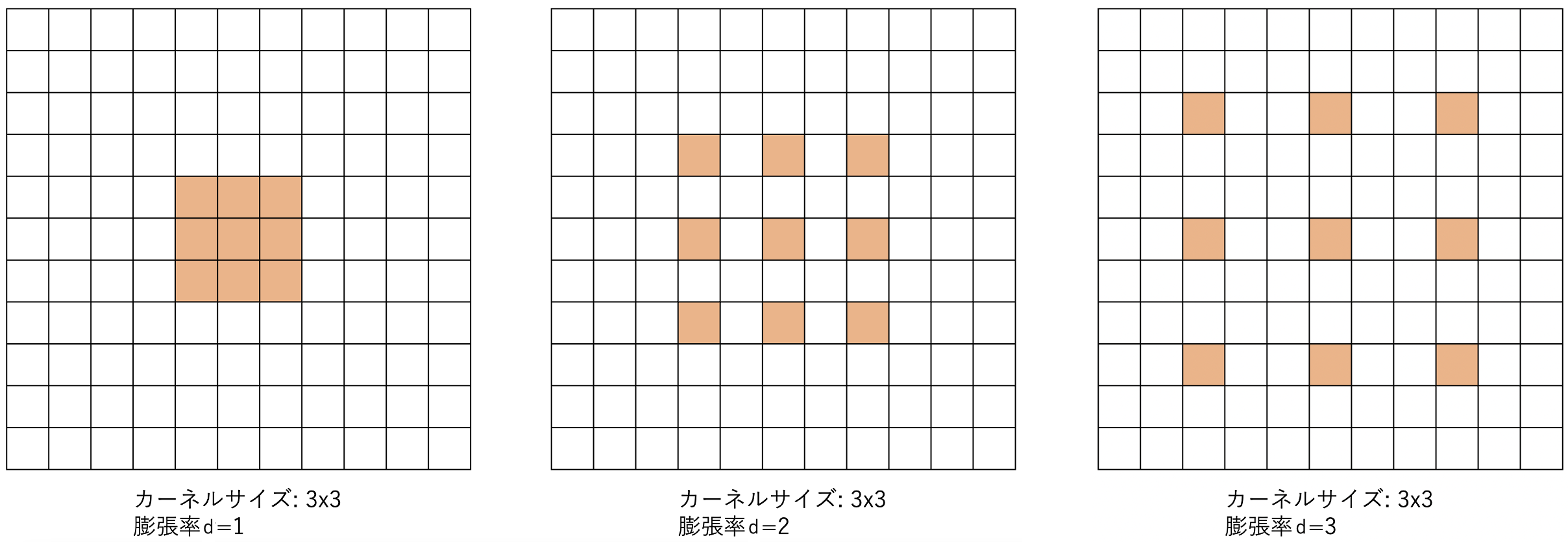
虽然扩张卷积可以用来有效地扩展感受野,但实际上已经有人提出了DenseNet和扩张卷积的组合。在本文中,我们重点讨论了这种情况下出现的混叠问题,并对其进行了改进:在扩张卷积中,参数之间的间隔可以被看作是采样频率,因为它是。这意味着会出现混叠问题,即高于奈奎斯特频率的高频变得与低频无法区分。
现有的方法在扩张卷积之前应用几个标准的卷积层,这些卷积层起着低通滤波器的作用,以去除不能被独特处理的高频成分。然而,在DenseNet中的Skip-Connection的情况下,这样的处理是不可能的,会出现混叠问题,如下图中的(a)所示。
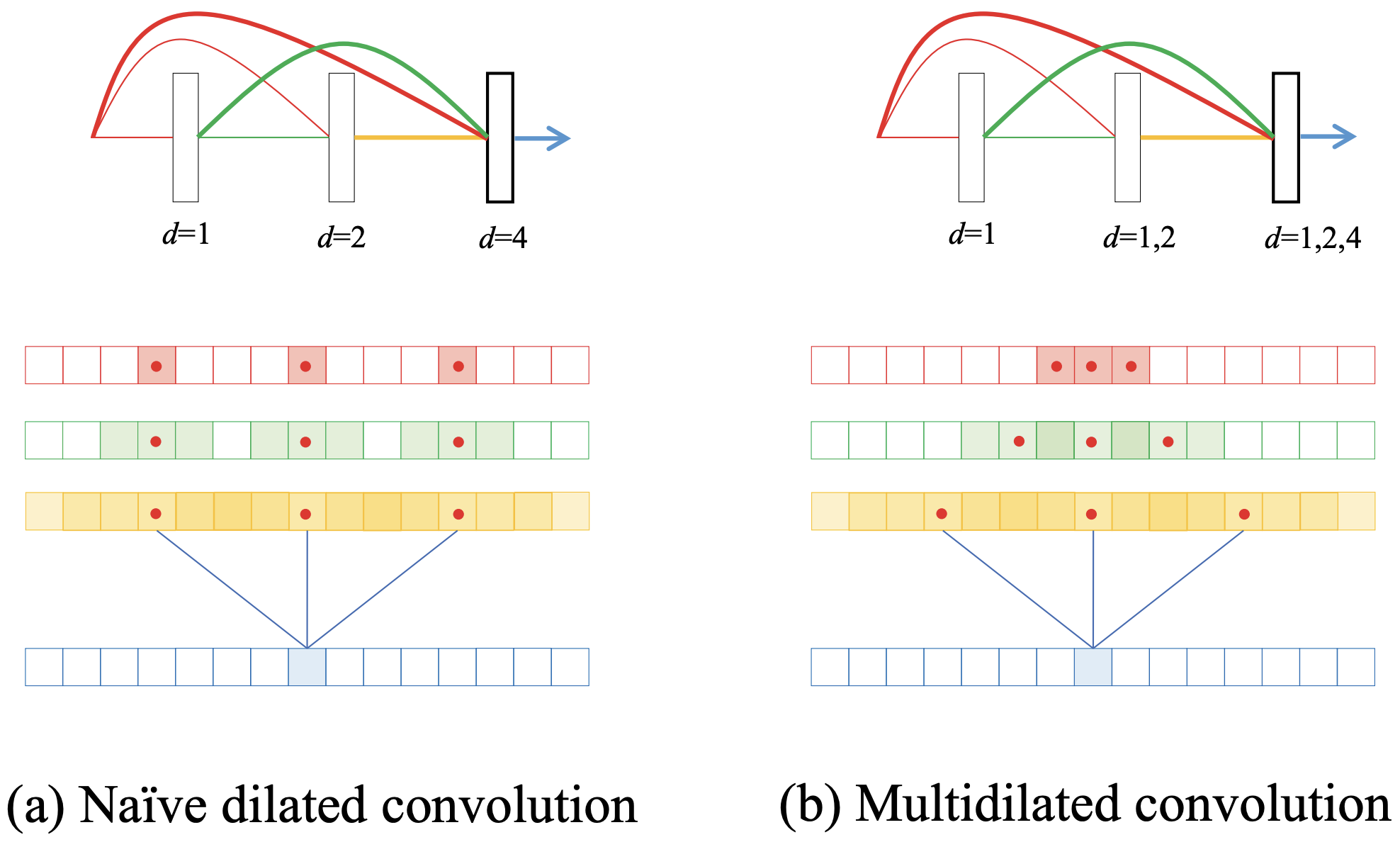
通过加倍的扩展率d,接受场会以指数形式扩展。为了简单起见,如果将特征图的采样用一个维度来表示,就可以理解混叠的问题。如果特征图的采样没有盲点,就不会发生混叠:第三层的扩展卷积(d=4)通过跳过连接与之前所有层的特征图相连。在这里,在d=4处对每张地图进行取样(红点),可以确定接受领域的盲点。由于红色地图是输入本身,接受场只在采样点(红色方块),那里的混叠问题是最明显的。然后考虑用d=1处理的绿色地图的采样,即通常的3x3卷积:通过采样一个方块,我们可以间接考虑3x3个方块(绿色方块),但我们仍然可以看到感受野中存在盲点。紧接着的黄色地图显示没有盲点,所以乍一看,如果我们继续增加d,似乎没有影响。然而,D3Net从未继续增加d,而是再次将d重置为1,逐个区块地进行扩张卷积,一次又一次地重复。这是因为密集地重复高分辨率和低分辨率的特征提取很重要。这意味着该模型是不稳定的,因为它导致了逐个区块的显著混叠问题。
建议的方法(以上(b))通过使用多个扩展率来解决混叠问题。这没有什么难的,它只是用不会引起混叠的最大扩展率对每张地图进行采样,如d=1的特征地图为d=2,d=2的地图为d=4。这就解决了混叠问题,同时允许在一层中进行多分辨率的卷积:在第三层卷积中,我们可以看到,从d=1处密集提取的局部特征图到依次在d=1、d=2和d=4处全局化的特征图是兼容的。该方程表示如下。上面是传统的扩张卷积,下面是应用多个扩张率的多扩张卷积。应用归一化和ReLU(方程中的ψ)。相比之下,传统的扩张卷积只是为每一层应用一个滤波器。相比之下,多分层卷积应用不同的扩张di和过滤器在i,代表哪个扩张d从卷积中跳过连接。
![]()
![\begin{align*}
x_l = \sum_{i=0}^{l-1}\psi([x_0,x_1,\cdots,x_{l-1}])\;\circledast_{d_i}\;w_l^i
\end{align*}](https://texclip.marutank.net/render.php/texclip20230113154150.png?s=%5Cbegin%7Balign*%7D%0A%20%20x_l%20%3D%20%5Csum_%7Bi%3D0%7D%5E%7Bl-1%7D%5Cpsi(%5Bx_0%2Cx_1%2C%5Ccdots%2Cx_%7Bl-1%7D%5D)%5C%3B%5Ccircledast_%7Bd_i%7D%5C%3Bw_l%5Ei%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
连接多个多分化卷积的区块被称为D2区块,并被建议作为D3区块的核心区块。D2区块因此避免了混叠,并以指数形式扩展了接受场,以模拟各种分辨率的信息。在一个指数级扩展的接收场中同时出现,从而避免了混叠。
最后,显示了D2区块的概览图。这是上图的一个二维例子。
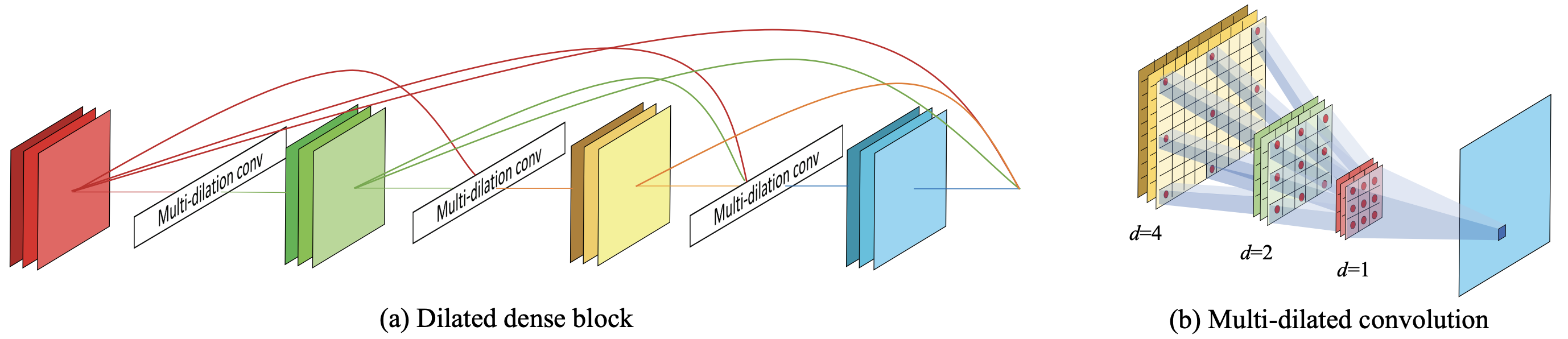
D3区块
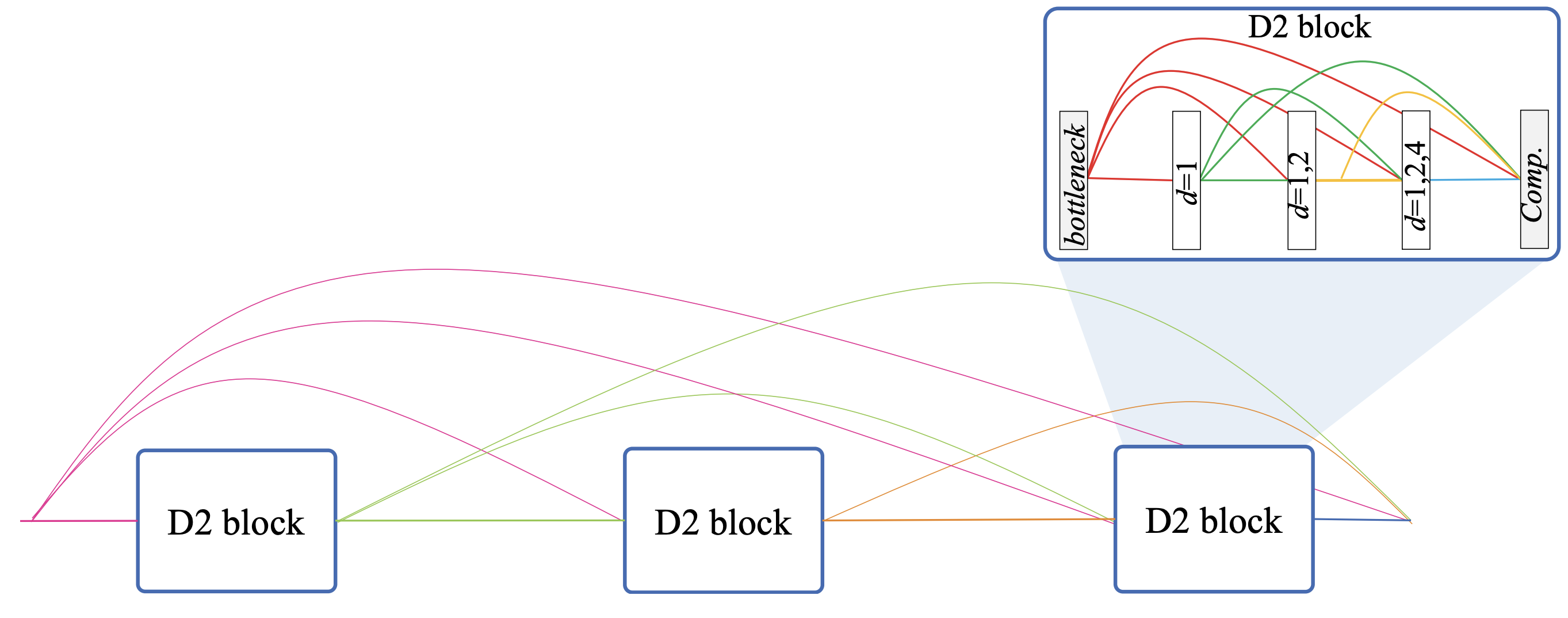
建议的方法更进一步,提出了一个D3块,它允许在每个分辨率下灵活地解释信息。D3块的结构如下图所示。首先压制了D2区块的细节。增长率k。
增长率k
如前所述,D3Net以DenseNet为基础,与ResNet简单地通过卷积增加通道数量的机制不同,D3Net从主的n个特征图中分支出来,并在主的特征图中增加生成的k个特征图(n+k)。因此,这个k被称为增长率;在D2区块公式中,每个x0,x1,...。xl有k个地图。然而,n+k并不是准确的通道数,因为D2块有一个瓶颈层和Comp层的前后,以及通道压缩。
另外,到目前为止,已经考虑用多分层卷积的方式进行多分辨率,但没有进行下采样,所以特征图的大小都是一样的。
巢穴结构
D3区块由M个D2区块组成。从图中可以看出,D3块有一个跳过连接的嵌套结构,与D2块的方式相同,它已经跳过连接了多分卷积的所有层。对D2区块的所有区块进行跳接。换句话说,该结构在区块之间和区块内部都是紧密跳接的。这使得D3区块成为一个极其密集和灵活的模型,因为一个D2区块在多个分辨率中解释已经考虑了前一个D2区块中多个分辨率的信息的特征。
超参数
D3块有五个参数(M、L、k、B、c)。如前所述,M是D2块的数量,L是D2块中多分卷积的层数,k是增长率,B是瓶颈层的通道数,本文设定为B=4k,c是Comp层的压缩率,它将通道数压缩为一个系数c。最后一个c是Comp层的压缩率,它将通道的数量压缩为c的系数。
D3Net
D3Net指的是任何采用D3块的模型,而本文使用的是基于DenseNet的改进模型。虽然到目前为止还没有进行降采样,但D3Net和DenseNet一样,在过渡层改变通道数量并进行降采样。这将导致在下一个D3区块的特征提取中,有不同的地图尺寸,也有多种分辨率。
实验
实验证明了所提方法在任务领域的通用性,在两个需要高密度估计的任务上进行了验证。
语义分割
重点是评估作为骨干网的D3Net。使用的数据集是CityScapes,这是一个由50个城市的5000张汽车前部图像组成的数据集。每幅图像中相应的物体类别在像素层面上被注释如下。评级是19个班级每班的平均信息量。
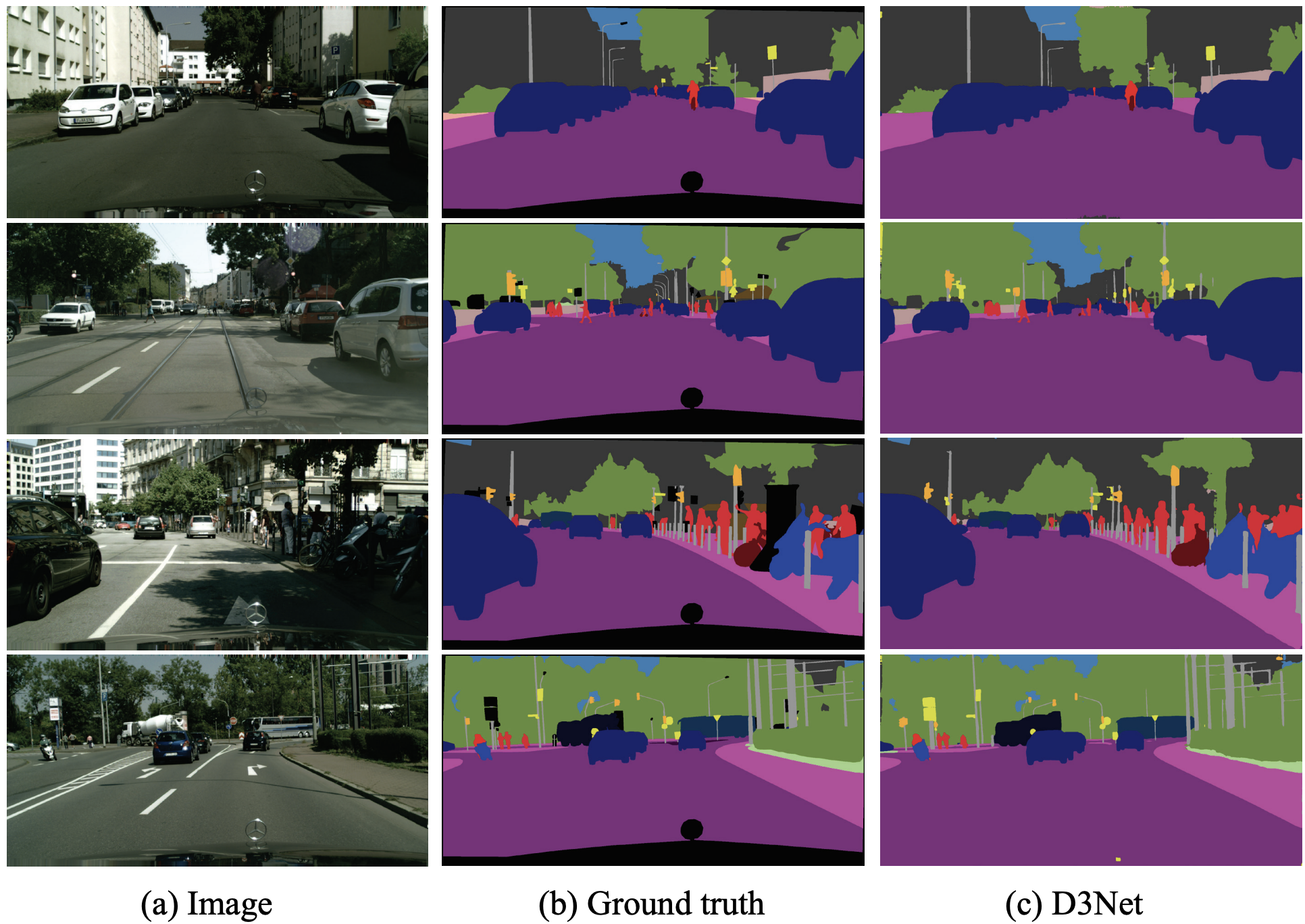
建筑
D3Net假设有两种模式,D3Net-S的(M,L,k,c)=(4,8,36,0.2),每个D3块的输出通道数为(32,40,64,128);D3Net-L的(M,L,k,c)=(32,48,96,192)。
结果。
这里的消融显示在表格中。为了显示多扩张卷积(D2块)的有效性,我们还用标准卷积(无扩张)和标准扩张卷积(standatd扩张)进行了训练。为了证明D3块的有效性,还准备了参数数量相似的DenseNet-133和DenseNet-189,并与DenseBlock进行了比较。
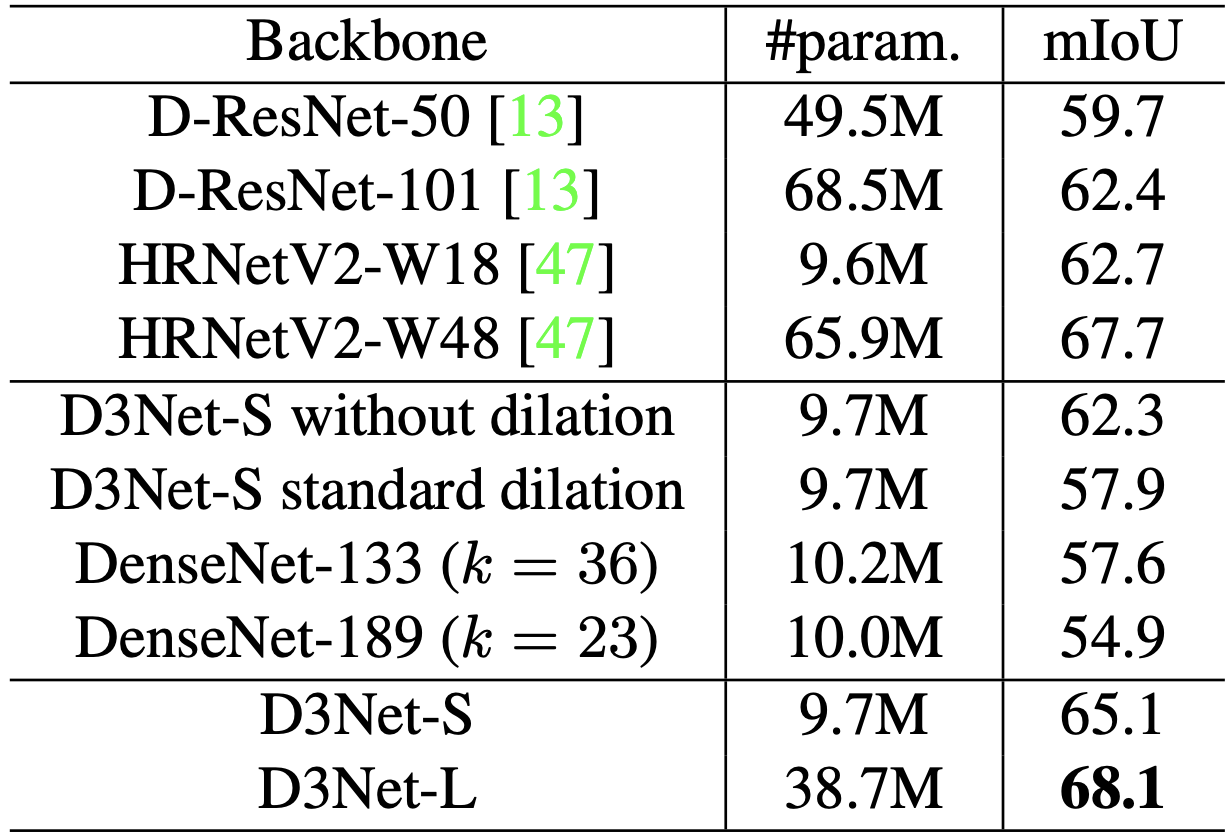
D3Net-S的表现明显优于无扩张和标准扩张,改善了mIoU。有趣的是,标准扩张也显示出比不扩张更低的准确性。这可能是由于混叠问题。所提出的方法避免了混叠,成功地提高了精度。对于与D3Net规模相近的DenseNet,它也取得了更高的准确率,显示了D3Net在通过扩张conv增加感受野方面的有效性,并且由于有效的参数数量,允许有更高的k。
在论文发表时,D3Net-L比SoTA模型HRNetV2W48的参数器少,在所有基线中达到了最高的准确度。
接下来是与SoTA模型的比较,只是D3Net-L的训练次数增加了,以确保模型规模的公平性。
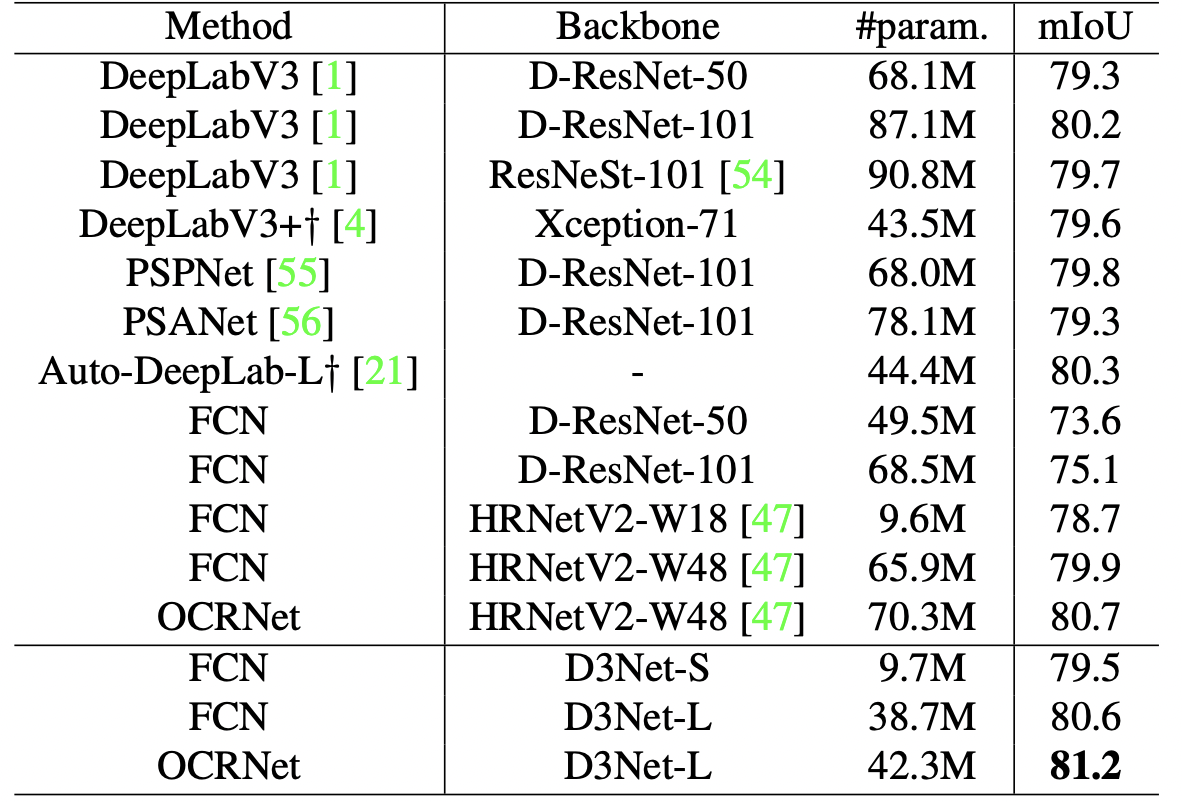
有基于DCN和OCRNet的方法,其中基于FCN的D3Net-L在参数远远少于HRNetV2p-W48、D-ResNet-101和DResnet-50的情况下,性能优于所有基线。D3Net-L的表现甚至更好,在发表时达到了81.2%的最高准确率。
声源分离
声源分离是将音频信号分离成单个声源的任务。在本文使用的MUSDB18数据集中,目标是将大约10个小时和150首歌曲的声源分成四个声源:低音、鼓、人声和其他。
评价
许多方法使用短时傅里叶变换(STFT)将时域信号转换为时间窗口单位的频率信息,并将其视为图像。这意味着这项任务也类似于分割任务,即为二维STFT图估计每个声源的振幅。它在某些方面与细分市场不同。估计振幅不仅仅是一个分类问题,而是一个回归问题,语音信号是多个声源的复杂叠加,与图像不同,它只显示最靠近摄像机的前方物体,而且STFT对频率不具有全局不变性。
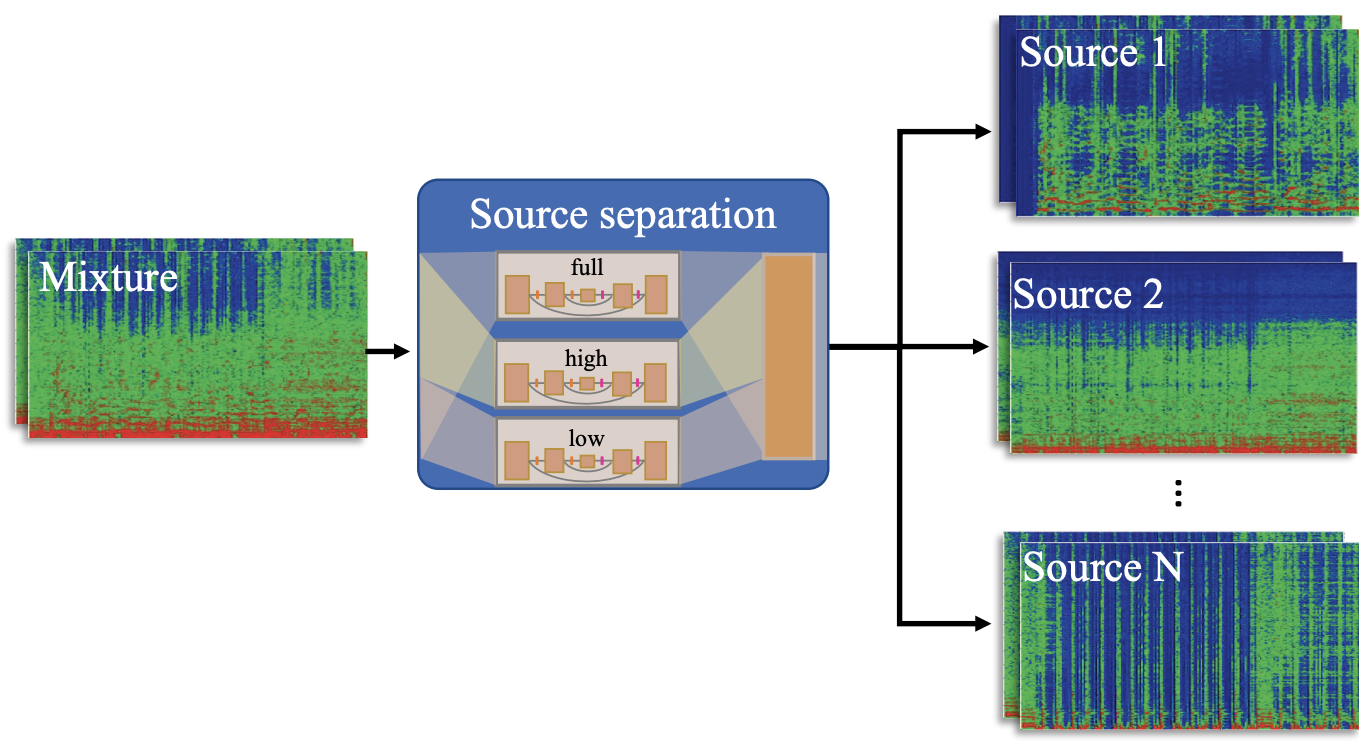
建筑
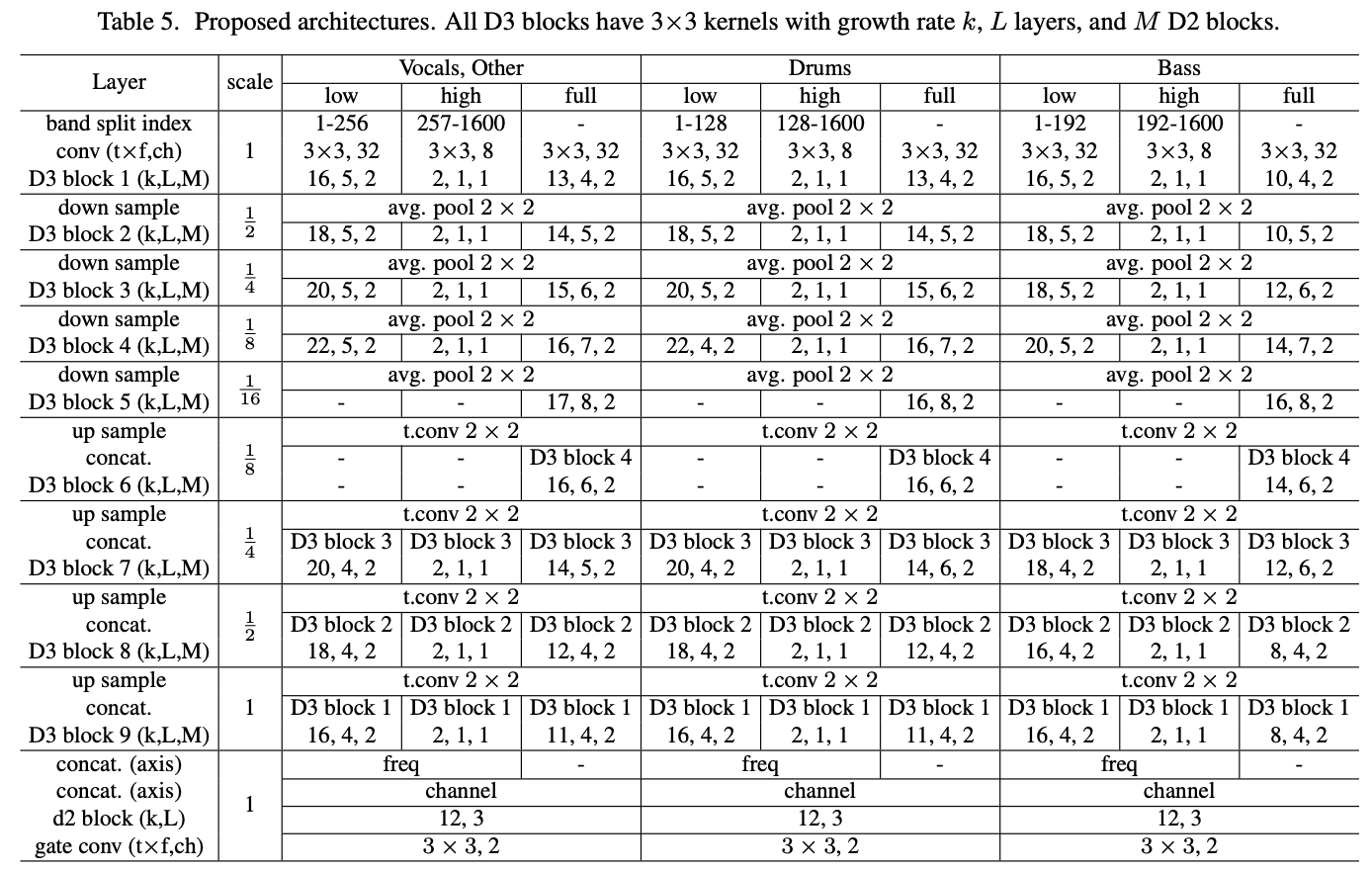
D3Net为四个音源中的每一个提供一个网络,并训练和估计频谱图。网络的输出是损失的MSE。它根据最佳模型,在低、高和全三个频段进行训练。换句话说,D3Net对四个来源中的每一个都使用了在三个频段上训练的总共12个网络。网络的输出被用于一个常用的频域声源分离方法,即多通道维纳滤波器(WMF),以获得最终的分离结果。该模型的细节在下表中给出。
结果。
所提方法和SoTA模型的信分比(SDR)。 有两种方法,一种是在频域处理,另一种是在时域处理(*)D3Net对人声、鼓声和伴奏(Acco)显示出最高的准确性,其中Acco是鼓声、贝斯和其他的总和 四种乐器的平均SDR为6.01dB,优于包括TAK1和UHL2在内的所有基线。这一结果优于所有基线,包括SoTA模型。
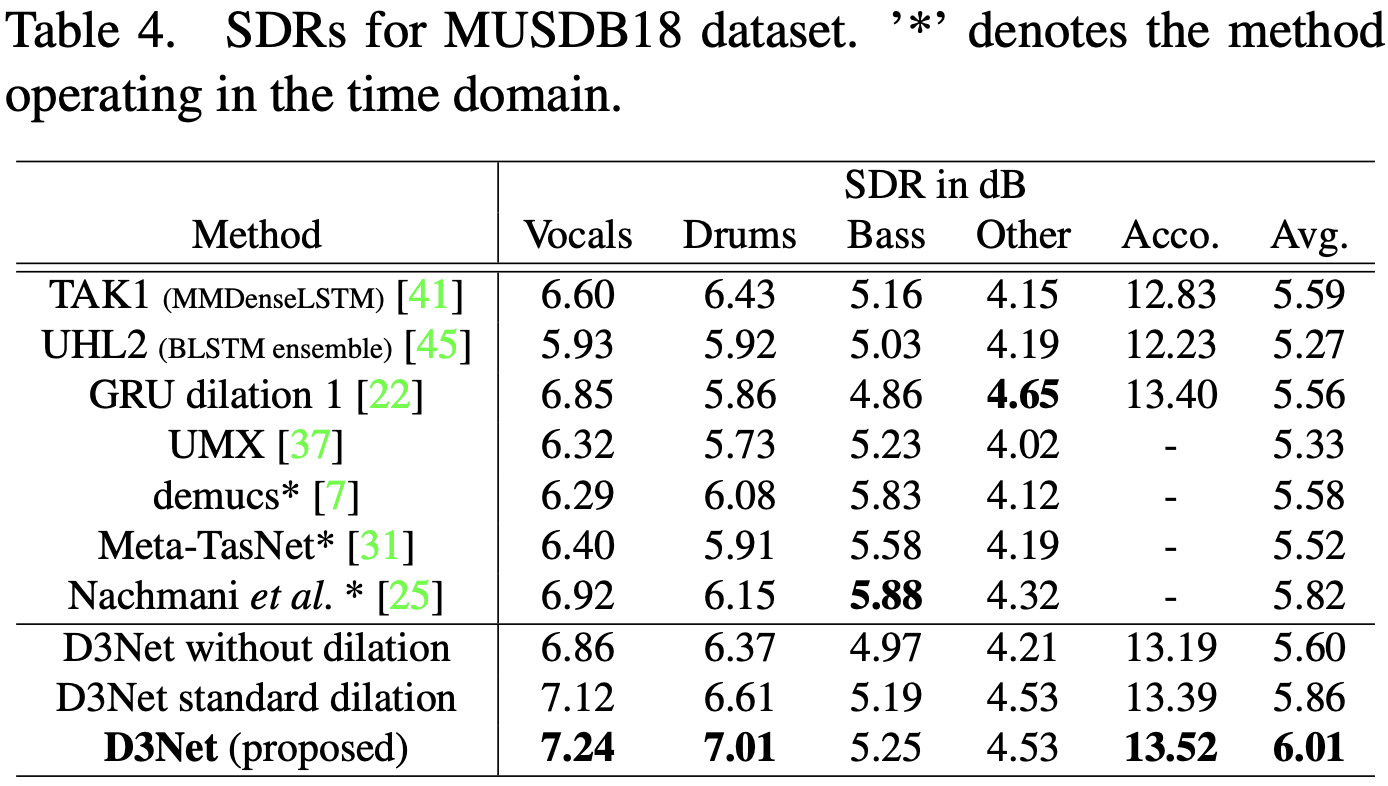 D3区块的有效性,它采用了多分叉的conv及其嵌套结构,显示了TAK1的有效性,它使用LSTM来扩大感受野。GRU稀释1也是由稀释的conv和稀释的GRU单元组成,没有使用上采样或下采样,这表明D3Net在多分辨率下密集处理的有效性。
D3区块的有效性,它采用了多分叉的conv及其嵌套结构,显示了TAK1的有效性,它使用LSTM来扩大感受野。GRU稀释1也是由稀释的conv和稀释的GRU单元组成,没有使用上采样或下采样,这表明D3Net在多分辨率下密集处理的有效性。
对于低音的声音,D3Net的表现不能超过现有的方法,因为时域更容易恢复。然而,D3Net是性能最好的频域方法。
在源头分离消融方面,标准扩张比无扩张的表现更好。在任何情况下,所提出的方法的多分频卷积明显优于标准卷积和标准扩展卷积,这一结果表明处理混叠问题的重要性。
印象
扩张的信念是一个很好的见解,因为我一直想知道两者之间的盲点会受到怎样的影响,但没有想到从混叠的角度来解决这个问题。
顺便说一下,有一个可变形卷积(Deformable Convolution),它比dilated conv更灵活,动态采样更多,但我很好奇混叠在这里会有什么影响。之前介绍的InternImage使用DCNv3作为策略,使性能更接近ViT,但我想研究是否会出现混叠问题。
摘要
在这篇文章中,展示了在高密度估计任务中密集学习多个分辨率的重要性,并提出了D3Net。它通过结合密集的跳过连接和采取嵌套结构,在高密度估计任务中具有很高的准确性,同时解决了标准扩张卷积中出现的混叠问题。
关于语义分割和源分离的实验显示了所提方法在不同任务和领域中的有效性和通用性,以较少的参数超越了最先进的骨干系统。
该论文声称,在设计CNN时,显示了对多分辨率的局部和全局信息紧密耦合的频率的重要见解。我们期待着未来的发展。



与本文相关的类别


