保留重要信息的增量
三个要点
✔️ 避免了最先进的扩增技术中存在的信息不足的问题。
✔️ 提出了一种简单而通用的方法
✔️ 在保持低计算成本的情况下,实现各种任务的准确性
KeepAugment: A Simple Information-Preserving Data Augmentation Approach
written by Chengyue Gong, Dilin Wang, Meng Li, Vikas Chandra, Qiang Liu
(Submitted on 23 Nov 2020)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
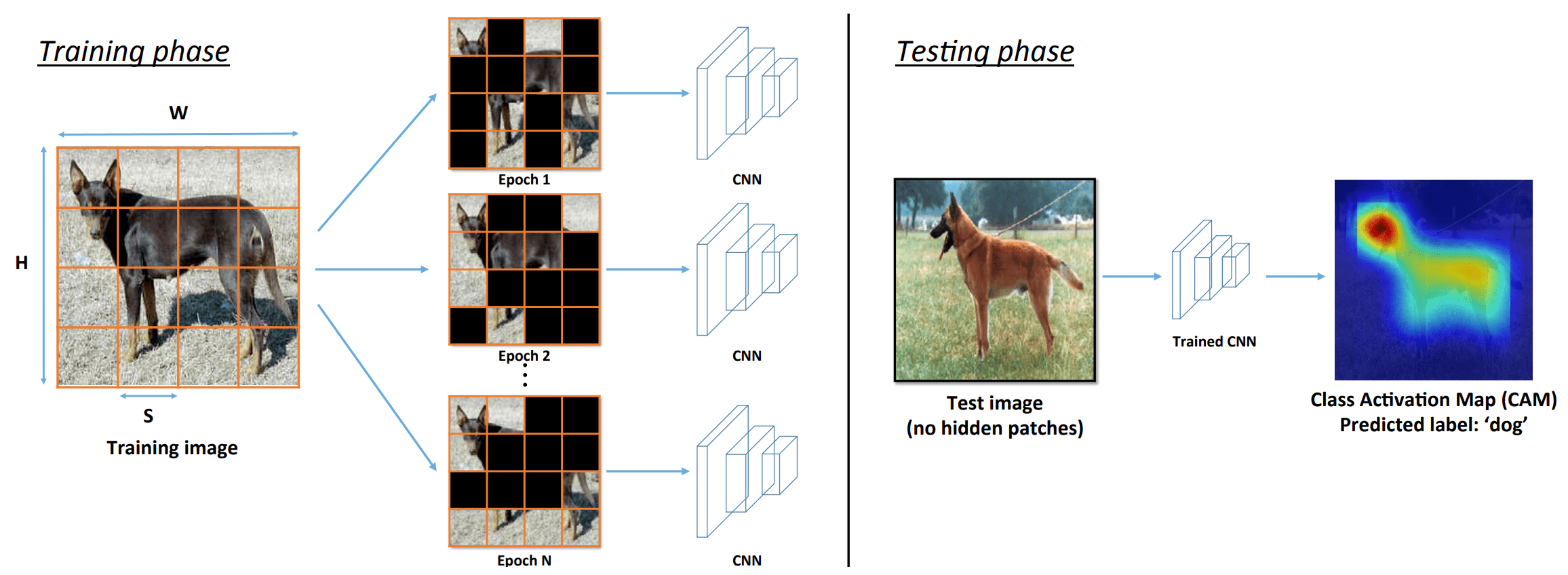
数据增强(DA)是训练当前深度学习模型的一项基本技术,因为它有望避免过度拟合,使模型更加健壮,降低模型对图像的敏感性,增加训练数据量,提高模型的概括能力,并避免样本的不平衡。由于这些原因,DA被许多人使用。然而,DA不可避免地在学习过程中引入了噪音和模糊性。请看下图。随机Cutout((a2)和(b2))和RandAugment((a3)和(b3))算法破坏了分类所需的原始图像的关键属性,并产生一个具有不正确或模糊标签的增强图像。

本文介绍的论文就是关于这样的DA。它将通过一个简单而有效的方法提高DA图像的保真度。这个想法是使用显著性地图来检测原始图像上的重要区域,然后在DA期间保留这些信息区域。我们的想法是,这种信息存储策略使我们能够产生更忠实的训练实例。 在本质上,它与Attentive CutMix处于同一位置。
数据扩展(因为它包括一个审查
我们重点关注标签不变的DA:如果x是一个输入图像,DA产生一个新的图像$x'$=$A(x)$,标签与x相同。这里,A代表一个标签不变的图像变换,通常是一个概率函数。让我们快速了解一下最先进的DA,它被广泛用于高级计算机视觉研究,同时也是一个回顾。
训练数据是通过随机掩盖输入图像的矩形区域来创建的。在图像中随机选择一个小的方形区域,这个区域的像素值被设置为0,但标签保持不变。Cutout防止模型过于依赖某个特定区域的视觉特征,旨在更好地利用图像中的全局信息。

Cutout使用一个固定的正方形,而且替换值都是一样的,而随机擦除使用一个长和宽的掩码区域,区域内像素值的替换值都是随机的。

图像被划分为一个SxS斑块的网格,每个斑块都以一定的概率(0.5)被遮蔽。补丁的隐藏方式在每个历时中都会改变,这使我们能够学习与一个物体相关的多个区域。
从数据集中随机选择的两幅图像按一定比例融合在一起,包括标签值。例如,一只狗和一辆车将以大约0.50%的比例融合。
到目前为止,这些是在2017年提出的方法。
这种方法结合了Cutout、随机擦除和Mixup的中间混合变化,选择一个小区域进行遮蔽,但遮蔽后,其他图像会与该区域重叠。

GridMask是对上述方法的改进,在这种方法中,遮蔽区域的选择是随机的,因此重要区域被完全遮蔽。GridMask在此基础上进行了改进,以预先确定的网格排列的方块来掩盖区域。

这是对GridMask的修改。简单地说,我们提出FenceMask是一种更好的遮蔽形状。

一种找到选择和组合不同标签不变变换(旋转、颜色反转等)的最佳策略并学习选择适当扩展参数的策略的方法;一种利用DA技术找到最佳组合的方法。

结果是更快的AutoAugment。 我们还提出了一种方法,避免了同时学习几次的GPU消耗,可以快100到1000倍。
RandAugmentation改进了AutoAugment的缺点,如训练的复杂性和计算成本增加,以及无法根据模型或数据集的大小来调整正则化的强度。RandAugmentation大大减少了DA产生的增量样本空间,使其与模型训练过程结为一体。

目前的方法是这些的演变:如Gridmask指出的 "重要区域被完全掩盖 "的问题,以及由于AutoAugment的演变而没有掌握的信息,它自动执行越来越多的最佳DA。本文的内容是对这些问题进行改进。你可以在下面的讨论中阅读更多关于作者的想法。
DA和权衡
为了研究上述想法,作者在CIFAR-10数据集上使用Cutout和RandAugmentation两种方法进行了实验,并分析了DA方法的强度与准确性之间的关系。Cutout的强度由Cutout的长度控制,而RandAugmentation的强度则由Distortion的大小控制。 实验结果如下图所示。
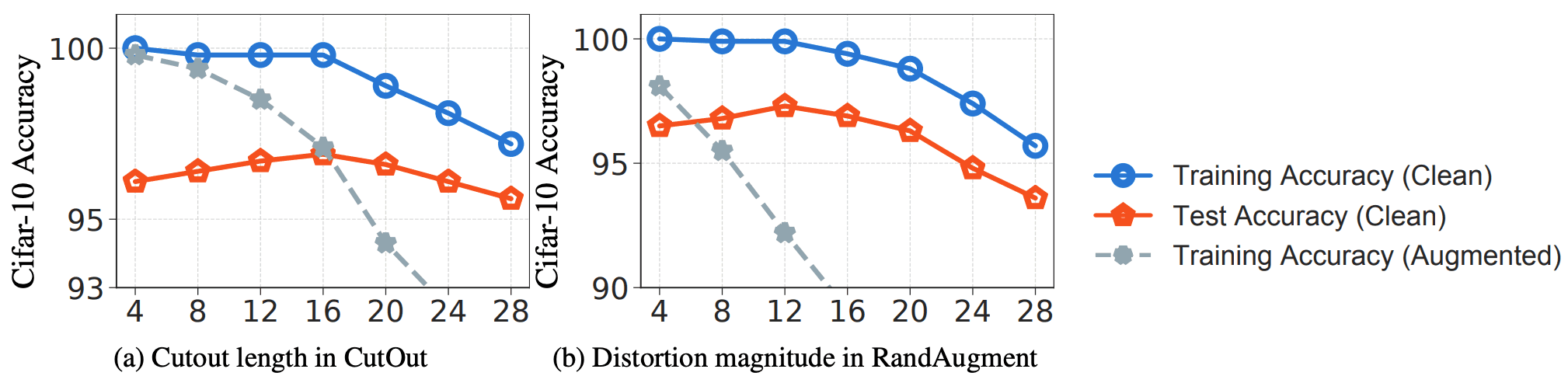
正如人们通常所期望的那样,在这两种情况下,泛化(原始数据的训练和测试准确性之间的差距)随着转换的大小而增加。 然而,当转换的大小过大时(对于Cutout≥16和RandAugmentation≥12),学习准确率(蓝线)和测试准确率(红线)开始下降。这表明DA数据不再是纯训练数据的忠实代表,DA数据的学习损失不能很好地替代纯数据的学习损失。
建议的方法
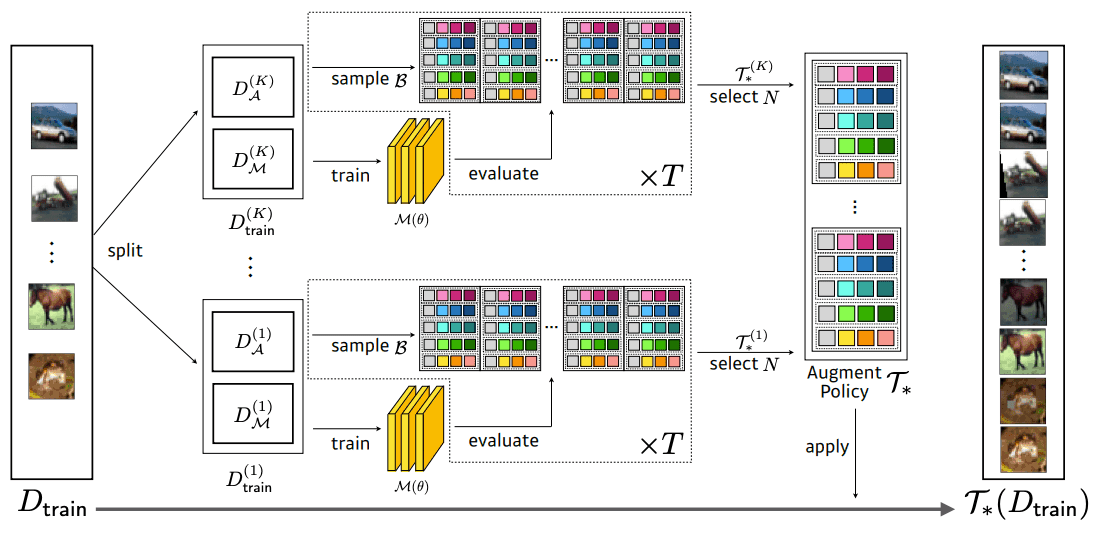
如a4和b4所示,KeepAugment的想法是通过显著性地图来衡量图像中的重要性,以便在DA之后保留重要性分数最高的区域。对于Cutout,它是通过不切割重要区域来实现的(a5, b5),而对于像RandAugmentation这样的图像级变换,则是通过将重要区域粘贴在变换后的图像上面来实现的(a6, b6)。

基于这些事实,KeepAugment可以分为两个步骤:计算突出性地图和保留关键矩形。 根据DA方法,关键矩形区域的保留可以分为 "选择性切割 "和 "选择性粘贴"。
显著性地图
KeepAugment使用一般的梯度方法来获得显著性地图。具体来说,给定图像x的一个像素(i,j)和一个标签y,显著性图为$g_{ij}$(x, y),其中对于图像中的一个区域S,显著性分数定义如下
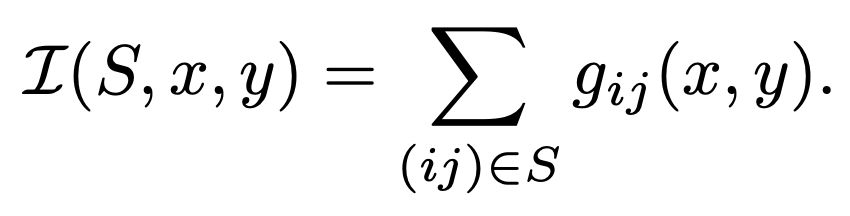
具体来说,给定一个图像x和相应的标签logit值y(x),KeepAugment将$g_{ij}$(x, y)设置为梯度的绝对值$|∇_(x)l_{y(x)}|$。 在RBG图像中,通道的最大值被用来为每个像素(i, j)找到一个显著值。
选择性切割
KeepAugment控制DA方法中的DA保真度,确保要删除的区域的重要性分数不会太大。 这在实践中是通过算法1(a)实现的,如下图所示。在算法1中,要切割的区域S被随机抽样,直到其重要性分数I(S,x,y)小于给定的阈值τ。

其中$M(S)$=$[M_(ij)(S)]_(ij)$是S的二进制掩码,$M_(ij)$=$I((i, j) ∈S)$。
选择性粘贴
由于图像级别的转换会对整个图像进行修改,我们通过粘贴具有高重要性得分的随机区域来确保转换的保真度。算法1(b)显示了在实践中是如何实现的,通过绘制扩展的图像级数据$x_0$=A(x),对满足I(S, x, y)>τ的阈值τ的区域S进行统一采样,并将原始图像x的区域S粘贴到$x_(0)$。我们实现了以下目标。
同样,$M_(ij)$= $I((i, j) ∈S)$是区域S的二进制掩码。
高效实现KeepAugment
KeepAugment需要在每个训练步骤中通过反向传播来计算突出度图。直接计算它将使计算成本增加一倍。 在这里,作者提出了一种有效的方法来计算显著性地图。
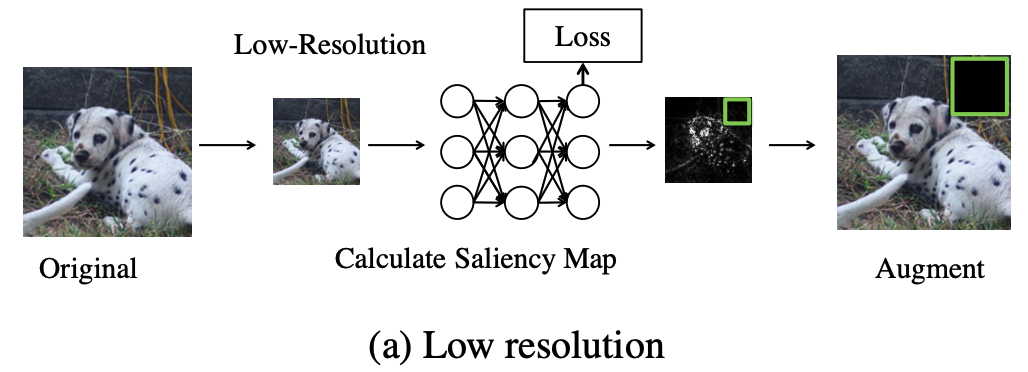
在低分辨率近似的基础上,作者进行了以下操作
- 对于一个给定的图像x,我们首先生成一个低分辨率的副本并计算其显著性图。
- 将低分辨率的突出性地图映射到相应的原始分辨率。
例如,这使得ImageNet通过将分辨率从224降低到112,实现了计算成本的三倍降低,从而大大加快了突出性地图的计算速度。
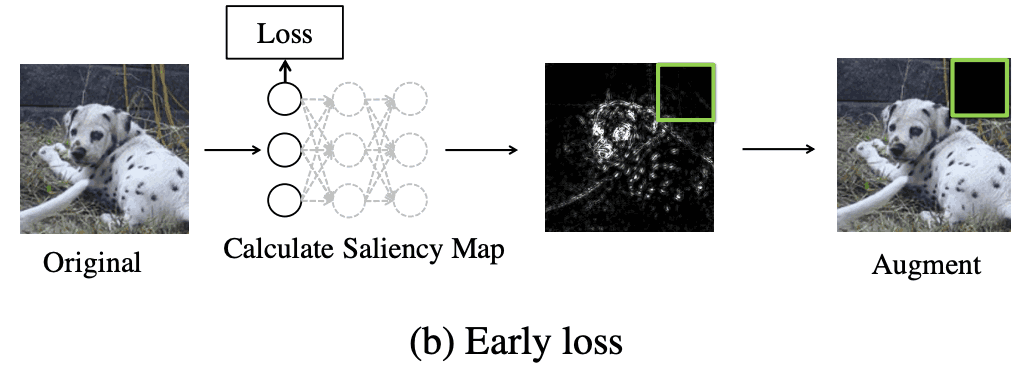
另一个想法是在初始损失近似的基础上,在网络的初始层增加一个损失,并使用这个损失来创建一个突出性地图。实际上,在对网络的第一批区块进行评估之后,又增加了一个平均池层和一个线性头。 训练的目的与初始网络相同。神经网络是用标准和辅助损失来训练的。这个想法使我们在计算突出性地图时,可以将计算成本降低3倍。
在整个实际实验中,这两种近似策略都没有造成任何性能的下降。
实验
作者将通过实验表明,KeepAugment在各种深度学习任务中实现了更高的准确性,包括图像分类、半监督图像分类、多视角和多摄像头跟踪以及目标检测。我们将拿起其中的几个,看一看。
数据集
使用的四个数据集如下
- CIFAR-10
- 图像网
- COCO 2017
- 市场1501
CIFAR-10分类
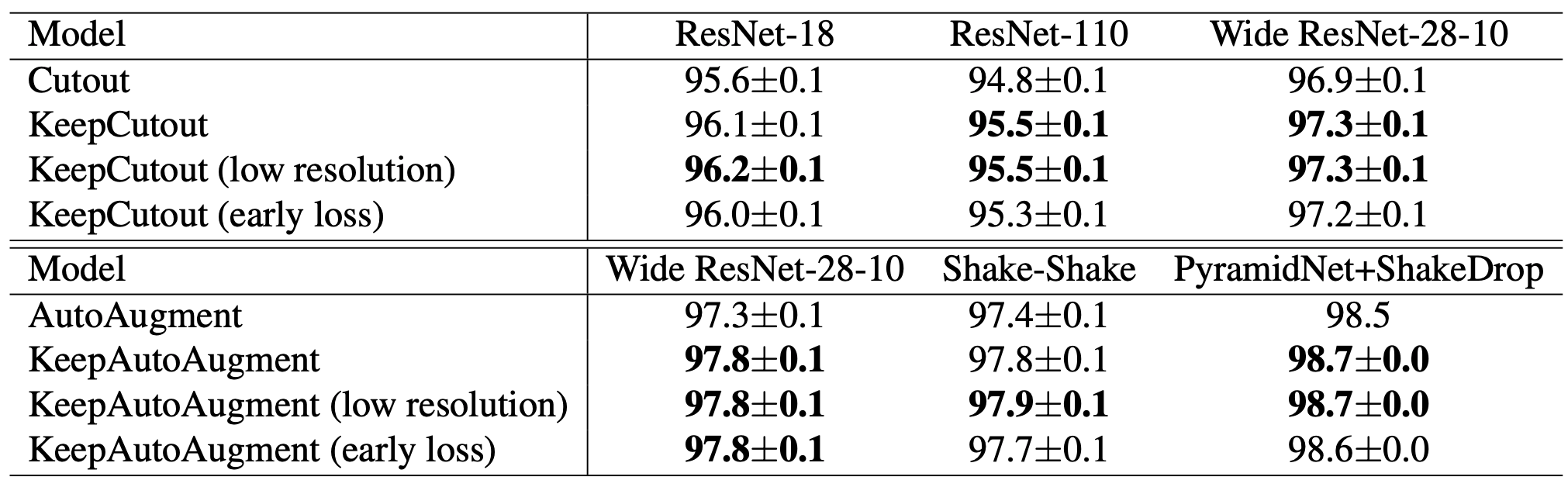
可以看出,在分类中可以提高准确性。可能是图像中出现了一些噪音。(按几次试验的平均值计算)
学习学习费用
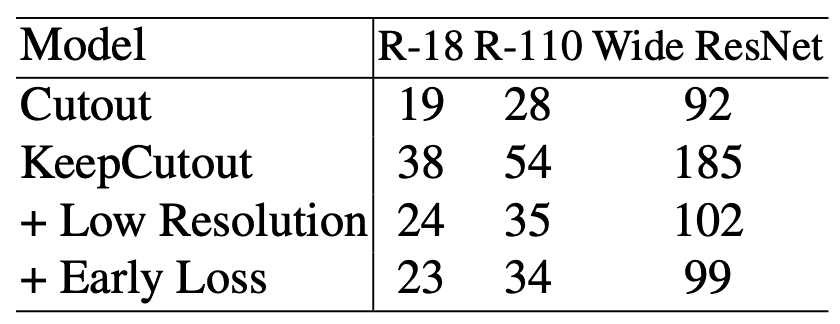
在分类中,Keep方法有助于提高准确性,但当我们看一下学习成本时,简单的KeepCutout几乎是普通Cutout的两倍。然而,正如我们在方法论中已经看到的,有两种降低学习成本的方法得到了回报。通过使用低分辨率图像和早期损失来计算突出性地图,我们可以看到,与Cutout相比,在学习成本小幅增加的情况下,准确性得到了提高。
半监督学习半监督学习
下面是结果:表达式4,000意味着4,000张图片被标记,其余4,6000张图片未被标记。

一直以来,准确率都比RandAug高。然而,这种改善是轻微的。
多视角多机位追踪

给出了基线和其他方法之间的比较。可以看出,所提出的方法取得了最好的性能。
迁移学习:物体检测
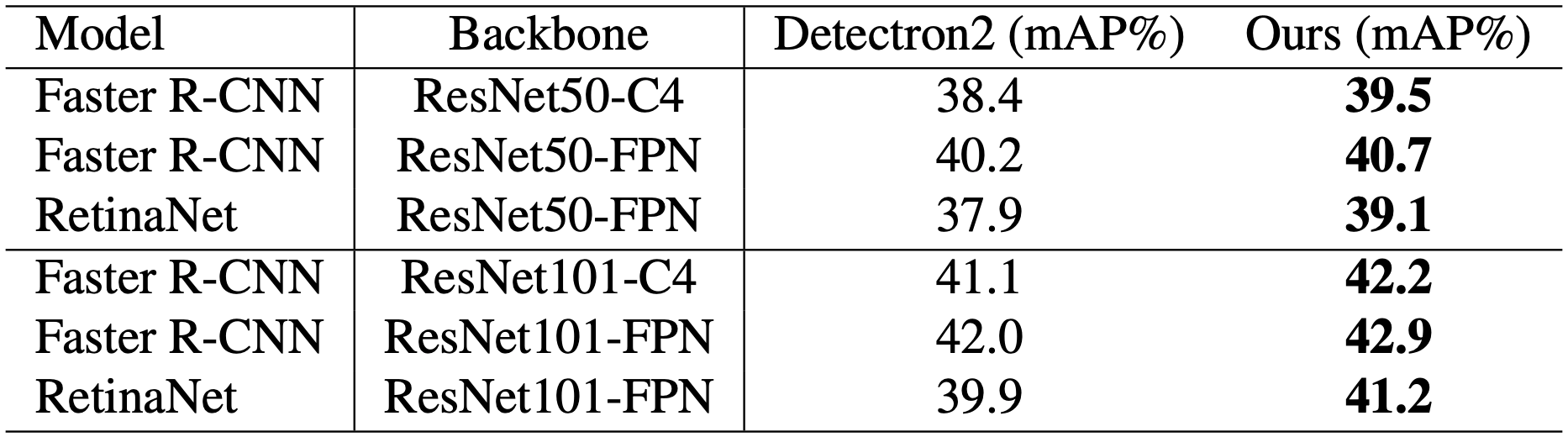
我们可以看到比基线有持续的改善。通过简单地将骨干网络替换为由所提出的方法训练的网络,COCO 2017中物体检测任务的性能得到了改善,而没有任何额外的成本。特别是对于单级检测器RetinaNet,ResNet-50和ResNet-101分别将37.9 mAP提高到39.1和39.9 mAP提高到41.2。
然而,ResNet50 + CutMix的表现极差,C4、FPN和RetinaNet的设置分别为23.7、27.1和25.4(mAP)。尽管CutMix是一种非常有效的DA方法,但对于某些任务和模型来说,它可能会造成强烈的精度损失。
发展
可以说,对DA中忠实性和多样性影响的实证研究表明,一个好的DA策略需要共同优化这两个方面。最近,其他一些研究也表明了平衡忠实性和多样性的重要性。例如,"MaxUp:提高神经网络训练泛化的简单方法"和"对抗性自动增强"。表明进行最差的优化或选择最难的强化策略是有效的,这表明了多样性的重要性。
另外,在"Attentive CutMix: An Enhanced Data Augmentation Approach for Deep Learning Based Image Classification"中,我们为了减少CutMix的噪音,我们考虑提取信息量最大的区域。这个想法与我们的方法相同。然而,他们提出的Attentive CutMix方法的缺点是,它需要加入一个预先训练好的分类模型作为老师。此外,我们的方法的优点是,它可以比Attentive CutMix适用于更多的DA方法和任务。
摘要
有人认为,由于可能引入噪声和模糊样本,现有的DA方法在提高整体性能方面的能力有限。 因此,作者提出使用显著性地图来衡量每个区域的重要性,并避免区域级DA方法切出重要区域(cutout)或通过粘贴原始数据中的重要区域来执行图像级DA(RandAugment)。
它是相当直观的,并且可以在未来发展。例如,虽然我们关注的是标签不变的DA,但似乎也可以研究将其应用于标签变量。不仅如此,我们还可以想到一些衡量重要性的方法。过去做DA和提高精度的日子已经过去了,我们现在处于如何做正确的DA和提高精度的阶段。



与本文相关的类别





