在评估分类模型的准确性时,标签是否总是必要的?
三个要点
✔️提出一种方法来预测无标签测试集上的分类模型准确性
✔️学习了一个回归模型,从数据集的统计数据中预测分类准确性
✔️在无标签的测试集上证明了准确性的估计
Are Labels Always Necessary for Classifier Accuracy Evaluation?
written by Weijian Deng, Liang Zheng
(Submitted on 6 Jul 2020 (v1), last revised 25 May 2021 (this version, v3))
Comments: CVPR 2021.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
在图像识别和其他计算机视觉任务中,标记的测试集被用来评估模型的性能。
然而,与提供预先标记的测试集的典型基准不同,如果你想在现实生活中使用该模型,这可能很难提供。
例如,如果你想把在模拟器的合成数据上训练的模型作为现实世界的训练集,可能很难准备一个现实世界的标记测试集。
本文通过提出一种方法(AutoEval)来解决这个问题,以估计一个模型在无标签的测试集上的性能。
例如,这种有问题的设置在下图中得到了总结
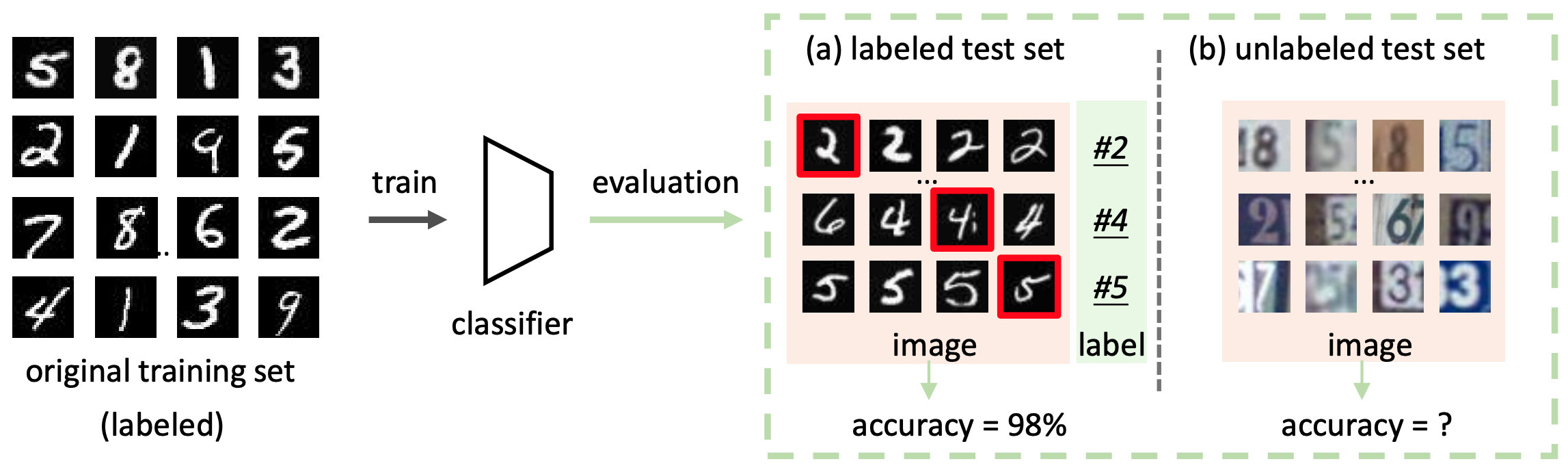
AutoEval的目标是评估一个分类模型在未标记的测试集上的性能,如图(b)所示。
论分布性转变与分类模型准确性之间的相关性
所提出的方法,即AutoEval,旨在评估分类模型在未标记的测试集上的性能。这个AutoEval是基于这样的发现:训练集和测试集之间的分布偏移与分类模型的准确性密切相关。
这在下图中有所说明。

在该图中,对于数字分类和自然图像分类,Fréchet距离(FD)显示在横轴上,分类分类精度显示在纵轴上。
如图所示,对应于分布偏移大小的Fréchet距离与分类精度之间存在着强烈的负相关,事实上Spearman等级相关系数$rho$约为-0.91。下面给出一个数字图像分类的实际例子。

在这个图中,样本集1的分类准确率为60%,其分布与训练集的差异很大;样本集2的分类准确率为86%,其分布偏差相对较小。
这表明,关于数据集的分布信息,如训练集和测试集之间的分布偏移的大小,可以用来估计分类模型在未标记的测试集上的准确性。
建议的方法(AutoEval)。
AutoEval的制定
基于上述发现,AutoEval旨在根据训练集和测试集的分布差异来预测分类模型的准确性。
具体来说,我们学习一个回归模型$A:(f_{\theta}, D^u) rightarrow a$,从数据集预测分类模型的准确性,将数据集视为样本,将该数据集的分类模型的准确性视为标签($f_{\theta}为分类模型,$D^u={x_i}$是未标记的数据集,$a$是对分类模型精度的估计)。)
让我们假设有$N$的样本数据集,并将第j$的样本数据集$D_j$表示为$(f_j,a_j)$。
其中$f_j$是数据集$D/j$的一些向量表示,$a_j/in [0,1]$是分类模型$d_{\theta}$对$D_j$的分类精度。
在这一点上,AutoEval的目标是学习回归模型$A$,它由以下公式表示
$a_j=A(f_j)$
为了训练这个模型,我们使用标准的平方损失函数。
$L=\frac{1}{N}\sum^N_{j=1} (\hat{a_j}-a_j)^2$
$hat{a_j}$是对$D_j$的$A$分类精度的预测。
训练完这个模型后,我们通过$a=A(f^u)$获得对应于无标签测试集$D^u$的向量表示的分类精度估计。
关于AutoEval
为了根据前面的表述来训练AutoEval,需要进行三个设计
- 数据集代表$f_i$。
- 回归模型$A$。
- 一组用于训练回归模型的$N$样本(元数据集)。
让我们依次看一下。
关于数据集表示法$f_i$和回归模型$A$
线性回归模型
作为回归模型$A$的一个简单例子,我们介绍以下线性回归模型
$a_{linear} = A_{linear}(f) = w_1f_{linear}+w_0$
在这种情况下,$f_{linear}$是样本集$D$的表示,$w_0,w_1$是线性回归模型的参数。另外,$f_{linear}$代表训练集$D_{ori}$与样本集$D$之间的弗雷谢特距离(FD:Fréchet distance),由以下公式给出
$f_{linear} = FD(D_{ori}, D)$
$= ||\mu_{ori}-\mu||^2_2 + Tr(\Sigma_{ori}+\Sigma-2(\Sigma_{ori}\Sigma)^{frac{1}{2}})$
在这种情况下,$mu_{ori},\mu$分别是$D_ori,D$的平均特征向量,$Sigma_{ori},\Sigma$是协方差矩阵。
这些是通过使用在$D_ori$上训练的分类模型$f_{thteta}$来计算$D_ori,D$中的图像特征而得到的。
神经网络回归模型
除了线性回归模型之外,我们还将考虑使用神经网络的回归模型。
这表示为$a_{neural}=A_{neural}(f_{neural})$,回归模型的架构是一个简单的全耦合的神经网络。
另外,对于对应于数据集的表征$f_{neural}$来说,使用数据集的平均向量$mu$、协方差矩阵$Sigma$和上述的$f_linear$定义如下。
$f_{neural}=[f_{linear}; \mu; \sigma]$
由于协方差矩阵$Sigma$的维度很高,难以学习,我们使用$Sigma$,通过$Sigma$的每一行的加权和来降低维度。
关于用于训练回归模型的元数据集
上述回归模型的训练需要一个样本数据集和相应的分类精度。
那么,理想的情况是,样本集应该有足够的多样性,测试集包括在元数据集的分布中。
为了建立这样一个元数据集,我们综合了各种数据集。
具体来说,从与训练集$D_{ori}$(具有与D_{ori}相同的分布)相同的源域$S$采样的种子数据集$D_s$经过各种转换过程,生成样本集$D_j$。
转换过程分为两个阶段
- 背景的转换:从COCO数据集中随机选择的图像被随机裁剪并替换为背景。
- 图像转换:6个图像转换过程中的3个(自动对比度、旋转、颜色、亮度、锐度、平移:见自动增强)被随机选择并结合起来,对每个样本产生不同程度的转换。为每个样品。
下面是一个图像转换过程的例子。

下面是一个在实践中生成的样本集的例子。

这些样本集的标签直接继承自种子集的标签,因此可以预测每个样本集的分类精度。
因此,对于上述程序产生的每个样本集,我们用在训练集$D_{ori}$上训练的分类模型$f_{theta}$预测分类精度,并将其作为回归模型的样本$(f_j,a_j)$。
基于信心的方法(基线
作为评估AutoEval的一个简单基线,我们引入了一个直观的解决方案,基于这样的假设:如果SoftMax层的输出很大(≈Confidence很大),那么预测就很可能是正确的。
具体来说,如果分类模型$f_{theta}$的SoftMax层的输出$s_i$大于阈值$tau$,我们就认为图像$x_i$的分类已经正确完成。
$a_max=A_max(f_{\theta},D^u)=\frac{\sum^M_{i=1}[max(s_i) >\tau]}{M}$
$M$是$D^u$中包含的图像数量。
实验设置
我们在两个分类任务上试验了AutoEval:数字分类和自然图像分类。各自的实验设置如下
数字化的图像分类任务
- 原始训练集$D_{ori}$:MNIST的训练集
- 用于生成元数据集的种子集 $D_s$:MNIST测试集
- 测试集:USPS,SCHN
- 样本集的数量:训练集为3000,验证集为1000
- 结构:LeNet-5
在生成样本集时,COCO训练集被用于背景替换。
自然图像分类任务
- 原始训练集$D_{ori}$:COCO的训练集
- 用于生成元数据集的种子集 $D_s$:COCO的验证集
- 测试集:PASCAL,Caltech,ImageNet
- 样本集的数量:训练集为1000,验证集为600
- 架构:在ImageNet上预训练的ResNet-50
在样本集生成过程中,COCO测试集被用于背景替换。
对于每个数据集,选择了12个常见的类别(飞机、自行车、鸟、船、瓶子、公共汽车、汽车、狗、马、监视器、摩托车、人)来使用(人的类别限制在600张图片)。人的级别限制在600张图片)。)
实验结果
对于上述三种方法(基于信心的方法、线性回归模型和神经网络回归模型),实验结果如下
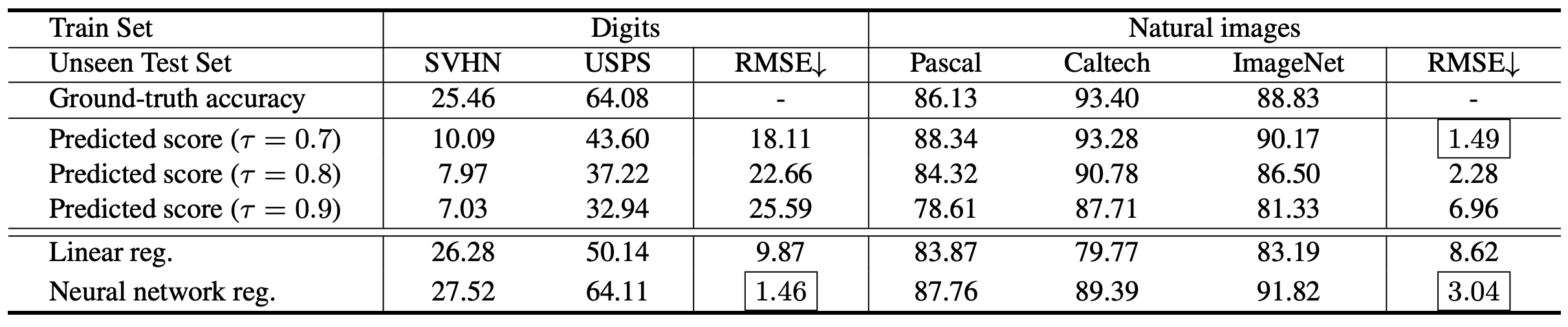
可以看出,基于置信度的方法对阈值很敏感,RMSE(越小越好)的变化,导致数字图像分类的性能很差,而AutoEval(线性调节/神经网络调节)工作稳定。
在加州理工学院的数据集上,线性回归模型也明显较差,这可能是由于线性回归模型受到加州理工学院数据集的简单背景的影响。
线性回归/神经网络回归模型的比较
为了验证这两种回归方法,在自然图像数据集(PASCAl、Caltech和ImageNet)上进行图像转换的比较实验结果如下。
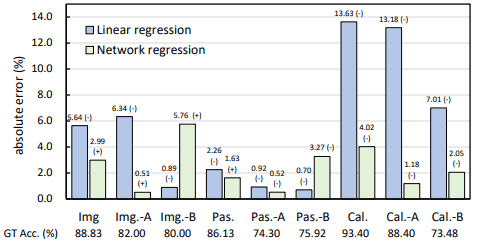
图像转换用"-A "和"-B "表示。
我们发现,除了加州理工学院的数据集,线性回归模型表现良好,而神经网络回归模型的表现一直很好。
关于元数据集
调查元数据集的大小(样本数据集的数量)和样本数据集的大小(样本数据集中的图像数量)对回归模型的影响,结果如下。
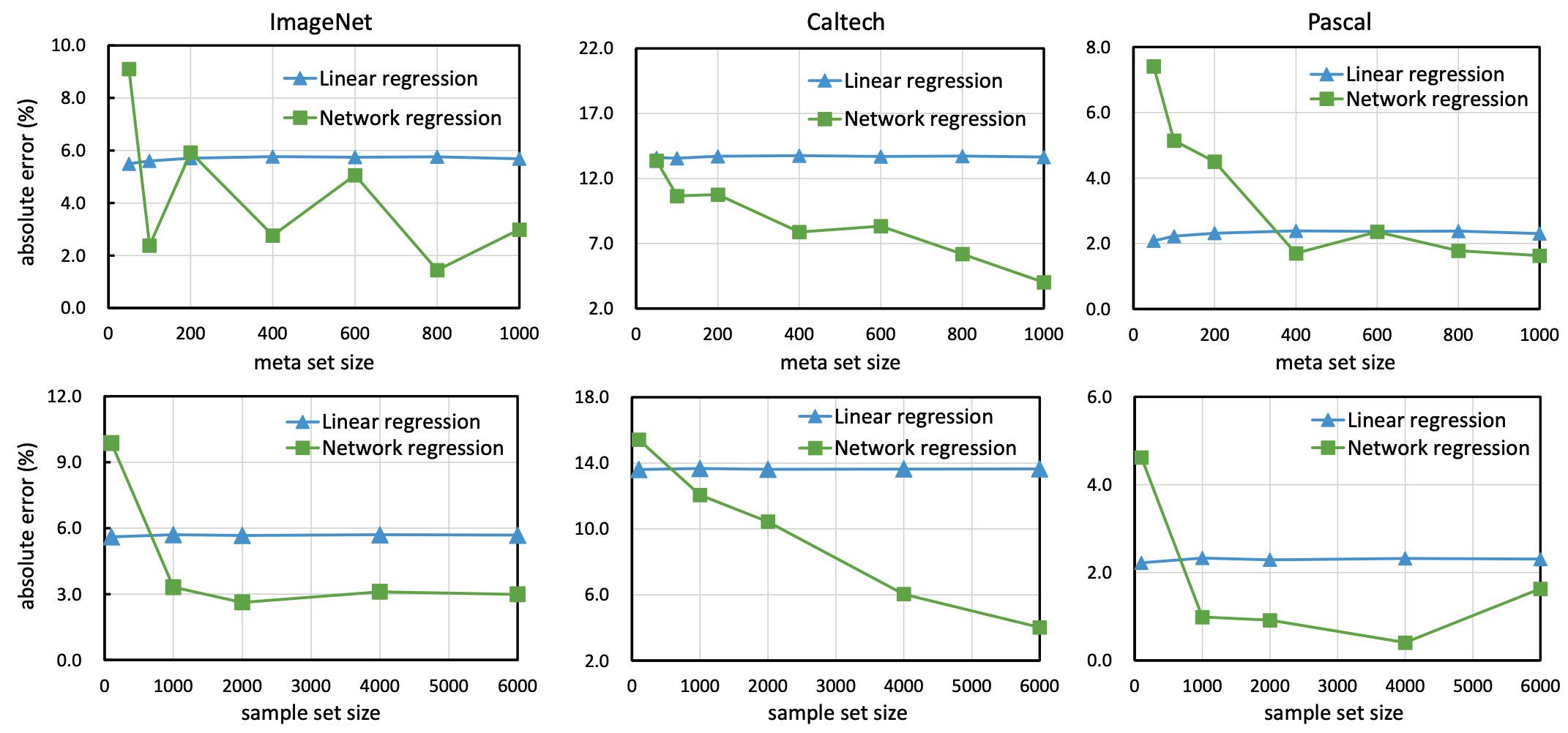
总的来说,我们发现线性回归模型在数据数量较少的情况下效果很好,而神经网络回归模型在元数据集/样本数据集规模合理较大时效果最好。
摘要
在本文中,我们解决了在没有标签的情况下预测测试集的分类准确性的新问题。
所提出的方法AutoEval在这个问题上取得了一些成功,它通过背景替换和图像转换过程创建合成样本数据集,并学习一个预测每个样本集的分类准确性的回归模型。
然而,(1)元数据集依赖于合成数据,根据测试集的分布情况,合成数据可能效果不佳;(2)除了均值和协方差之外,可能还有其他有效的数据集表示;(3)尽管FD得分被用来衡量数据集之间的相似度(3) 虽然FD分数被用来衡量数据集之间的相似度,但可能还有其他有效的标准。



与本文相关的类别






