
See Finer, See More. Imicit Modality Alignment For Text-based Person Retrieval.
三个要点
✔️ 在视觉任务中应用One-Shot NAS到Transformer。
✔️ 提出权重纠结,分享大部分的子网权重
✔️ 与现有基于变压器的方法相比,性能优越
See Finer, See More: Implicit Modality Alignment for Text-based Person Retrieval
written by Xiujun Shu, Wei Wen, Haoqian Wu, Keyu Chen, Yiran Song, Ruizhi Qiao, Bo Ren, Xiao Wang
(Submitted on 18 Aug 2022 (v1), last revised 26 Aug 2022 (this version, v2))
Comments: Accepted at ECCV Workshop on Real-World Surveillance (RWS 2022)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
人的重新识别,即搜索人的图像,在许多方面都有需求,如从安全摄像机中寻找嫌疑人或丢失的儿童。其中,基于文本的人的重新识别,即不搜索显示与输入图像相同的人的图像,而是从文本中搜索显示与之匹配的人的图像,已经引起了很多人的注意。这个领域相当热门,最新的是4月5日发表的一篇论文([2304.02278] Calibrating Cross-modal Feature for Text-Based Person Searching (arxiv.org)),更新了SOTA。(截至4月13日)。
在基于文本的人的再识别任务中,主要的方法是将图像和文本模式都映射到同一个潜在空间中。传统的方法通常使用单独的模型进行特征提取,如Resnet用于图像编码器,BERT用于文本编码器,但这种方法有两个挑战。
- 在单独的模型中,各模式之间没有互动。仅仅通过使用匹配损失,很难使一个具有大量参数和深层的模型考虑到相互作用。(图1a)
- 文本的多样性使得部分内容难以匹配。例如,一些展示同一个人的文本有关于发型和裤子的描述,而其他文本则有关于配饰和颜色的描述。
本文所采取的方法是在第一项任务中使用相同的编码器,而第二项任务的方法是更多地着眼于局部语义的匹配,而不是更仔细地寻找。
第一种方法引入了一个隐性的视觉和文本学习(IVT)框架,允许网络学习两种模式的表征(图1b)。
作为第二种方法,我们提出了两种隐性语义对齐范式,即多级对齐(MLA)和双向屏蔽建模(BMM),以实现细粒度的模态匹配。具体来说,如图1(c)所示,MLA旨在通过利用句子、短语和单词级别的匹配来探索细粒度的匹配,而BMM则允许模型通过屏蔽一定比例的视觉和文本标记来挖掘更有用的匹配线索。这两个提议的范式不仅可以实现更精细的视图,而且可以实现更多的语义匹配。
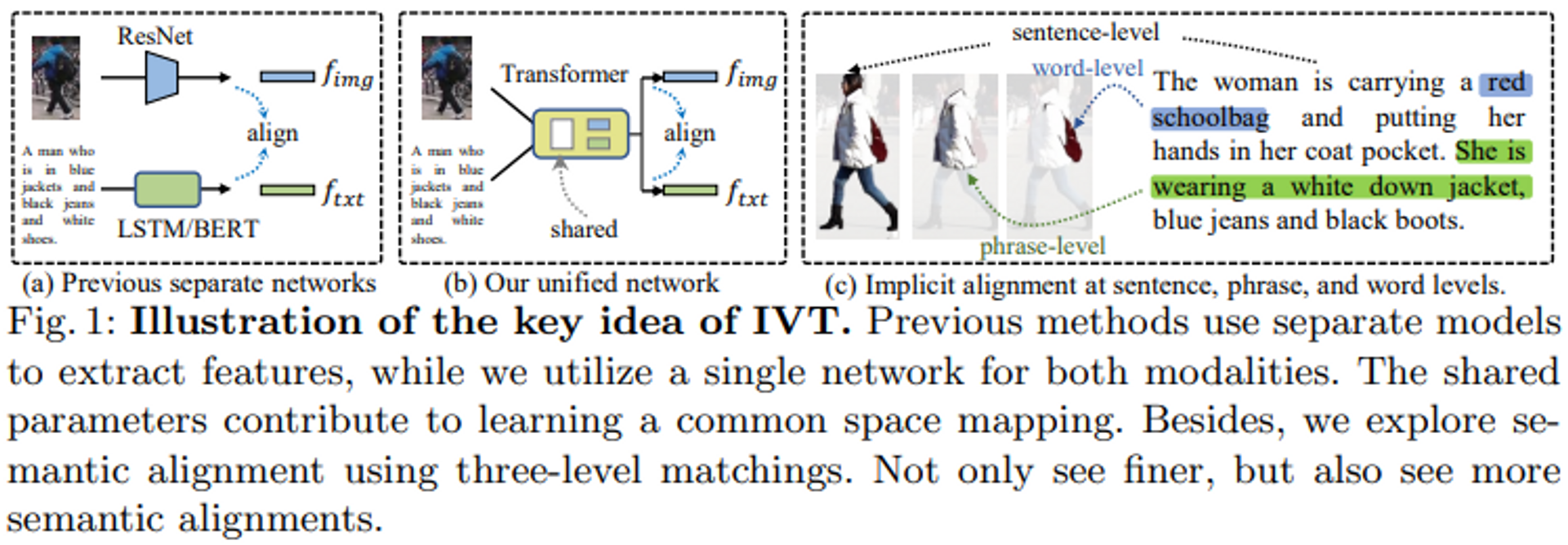
建议的方法
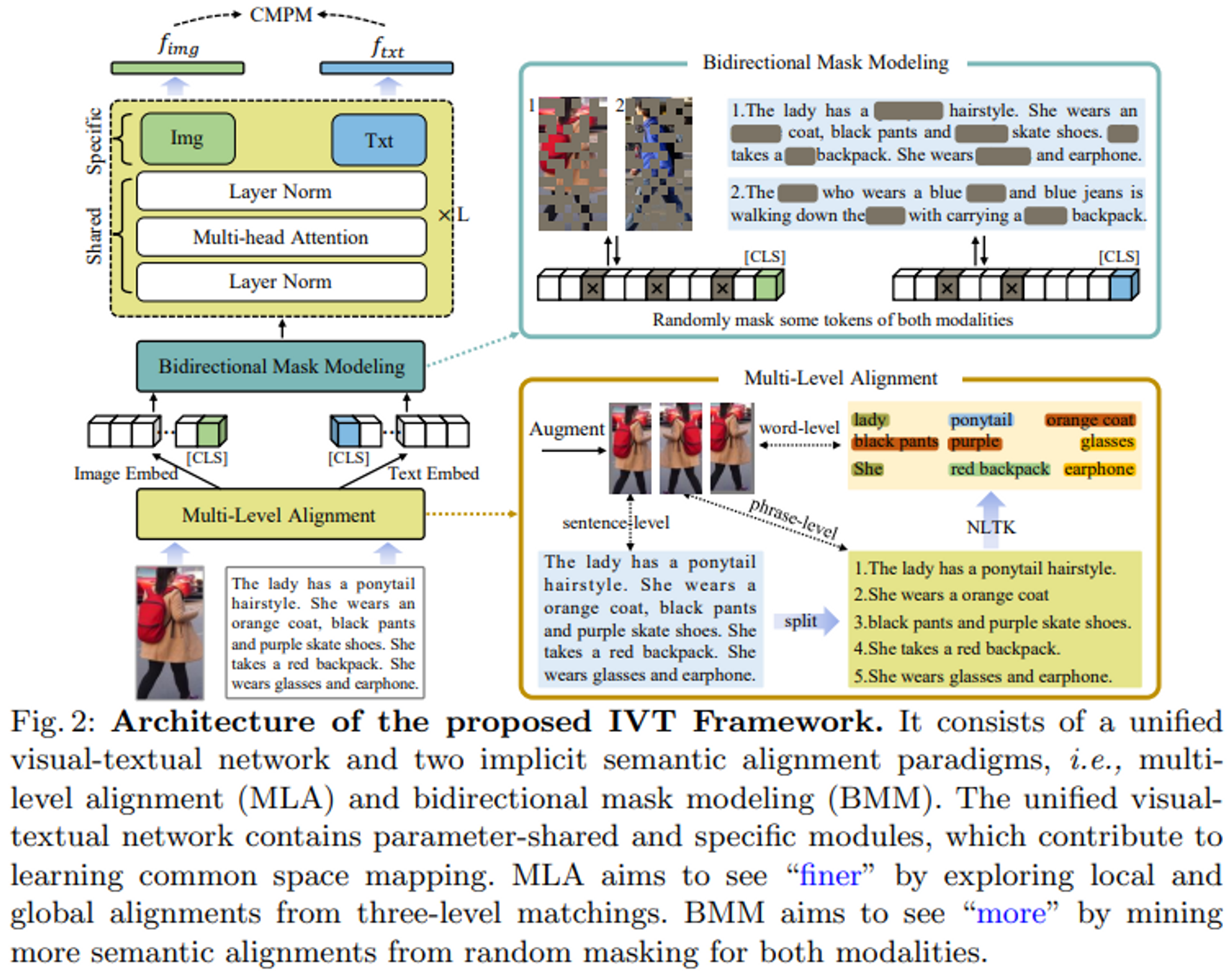
IVT框架包括一个统一的视觉-文本网络和两个隐性语义对齐范式(多级对齐和双向掩码建模)。
IVT的一个关键想法是使用一个统一的网络来解决模态对齐问题。通过共享一些模块,如层规范化和多头注意力,统一的网络有助于学习视觉和文本模态之间的共同空间映射。不同的模块也可以用来学习特定模态的线索。
提出了两个隐性语义对齐范式,MLA和BMM,以探索细粒度的对齐。
编码器
大多数传统方法都是利用文本和图像编码器的独立模型,缺乏模式间的互动。因此,本文建议采用一个统一的图像-文本网络。
如图2所示,该网络遵循标准的ViT架构,总共堆叠了L个块。在每个区块中,两个模态共享层归一化(LN)和多头自我关注(MSA),这有助于学习图像和文本模态之间的共同空间映射。共享的参数有助于学习共同的数据统计。例如,LN计算输入标记嵌入的平均值和标准偏差,而共享LN则学习两种模态的共同统计值。从数据层面来看,这可以被视为 "模态互动"。由于图像和文本的模态不同,每个模块都有一个特定模态的前馈层,即图2中的 "Img "和 "Txt "模块,以获得特定模态的信息。每个模块的完整处理过程可以表示如下。
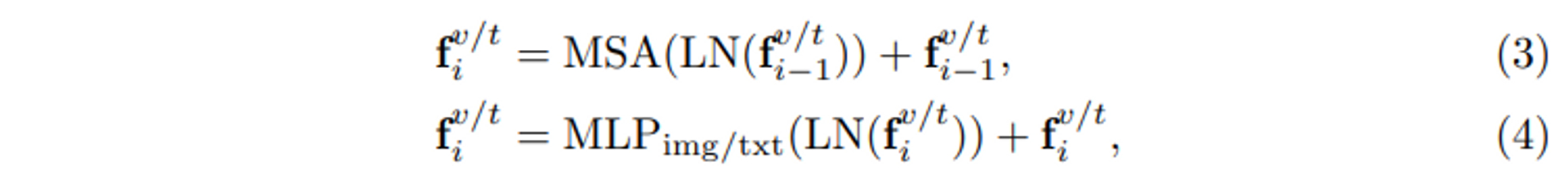
隐性语义对齐
多层次对齐
提出了一种直观而高效的隐性定位方法,即多步骤定位。
如图2所示,输入图像首先以三种不同的方式进行扩展,包括水平翻转和随机裁剪。输入的文本用句号和逗号分割,形成较短的句子。这些较短的句子被用作描述人体部分外观特征的 "短语级别 "的表述。为了提取更多的细节,自然语言工具包(NLTK)被用来提取描述特定局部特征的名词和形容词,如包、衣服和裤子。三个级别的文本描述--句子级别、短语级别和单词级别--对应于三种类型的增强图像;三个级别的图像-文本对在每个迭代中随机生成。通过这种方式,可以建立起一个从全局到局部的逐步完善的匹配过程,使模型能够采用更精细的语义对齐。
双向掩码建模
本文认为,局部对齐不仅应该更精细,而且应该更多样化。微妙的视觉和文字线索可以补充全局对齐。我们提出了一种双向掩码建模(BMM)的方法来挖掘更多的语义对齐,如图2所示。一定比例的图像和文本标记被随机屏蔽,以迫使视觉和文本输出匹配。通常情况下,被遮蔽的标记对应于图像中的特定斑块或文本中的单词。如果一个特定的斑块或单词被掩盖了,模型会尝试从其他斑块或单词中找到有用的对齐线索。以图2中的女性为例,如果突出的词 "橙色大衣 "和 "黑色裤子 "被掩盖,模型将关注其他的词,如马尾辫的发型或红色背包。通过这种方式,可以探索出更微妙的视觉文本定位。这种方法使模型在学习阶段更难对齐图像和文本,但有助于在推理阶段探索更多的语义对齐。
损失函数
CMPM损失被用来作为匹配损失。我们把细节留给Deep Cross-Modal Projection Learning for Image-Text Matching(thecvf.com),但简而言之,文本-图像嵌入匹配是通过KL发散进行的。
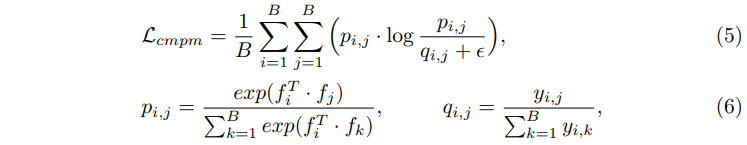
实验
提出的IVT方法在三个数据集上实现了SOTA。评估是用Recall@n(n=1,5,10)进行的。
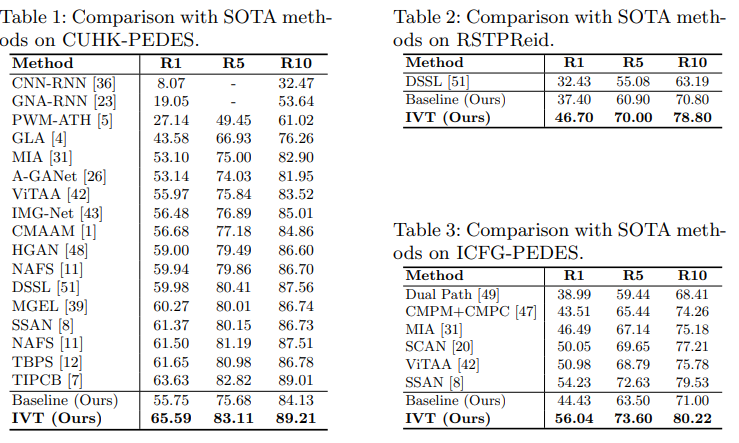
图4显示了基线和拟议方法IVT的决策基础的可视化。(用[CLS]标记的注意力图的可视化)。一般来说,文本描述可以对应于人体,表明模型已经学会了视觉和文本模式的语义相关性。与基线相比,IVT证实了它关注文本所描述的人体的更多属性。例如,这个男人(第1行,第1列)穿着灰色短裤。基线忽略了这个属性,但IVT能够捕捉到它。因此,拟议的IVT比基线方法更准确,可以处理更多的人的属性。

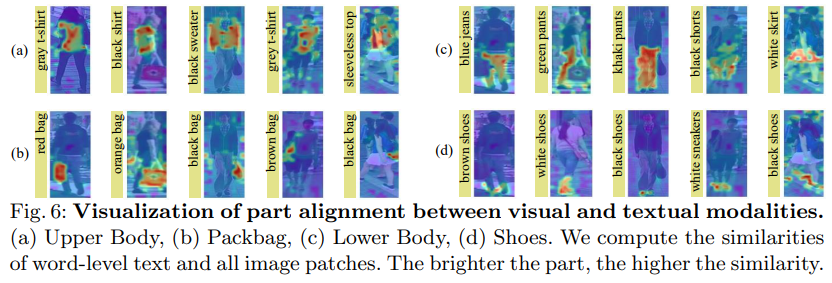
图6显示了带有本地令牌的属性。给出了四个不同的人物属性:上半身、包、下半身和鞋子。图6中的每一行都有相同的属性。如图6所示,该方法不仅能够识别突出的部分,如衣服和裤子,还能够识别细微的部分,如手袋和鞋子。这些可视化的结果表明,给定一个词级的属性描述,我们的模型能够准确地聚焦到正确的身体部位。这表明我们的方法即使在没有明确的视觉和文字部分排列的情况下,也能够探索精细的排列方式。这是所提出的两种隐含语义对齐范式,即MLA和BMM的好处。因此,可以得出结论,所提出的方法确实可以在基于文本的人物检索中实现See Finer and See More。
摘要
在本文中,我们提议从两个角度解决模态对齐问题:骨干网络和隐性语义对齐。首先,引入了一个基于文本的人物检索的隐性视觉文本(IVT)框架。它使用一个单一的网络来学习视觉和文本表征。其次,提出了两个隐性语义对齐范式,即BMM和MLA,以探索细粒度的对齐。这两个范式可以通过使用三层匹配看到 "更细",而通过挖掘更多的语义对齐来看到 "更多" 在三个公共数据集上的广泛的实验结果证明了该提议的有效性。.



与本文相关的类别






