不使用批量归一化的新冠军NFNets!形象任务顶级性能!
三个要点
✔️ 使用新的自适应梯度剪裁方法替代批量归一化
✔️ 架构 NFNets 无归一化实现 SOTA。
✔️ 比使用批量正则化的模型有更好的学习速度和转移学习能力。
High-Performance Large-Scale Image Recognition Without Normalization
written by Andrew Brock, Soham De, Samuel L. Smith, Karen Simonyan
(Submitted on 11 Feb 2021)
Comments: Accepted to arXiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML)




首先
今天的许多深度学习网络经常使用残差连接以及激活函数,如批归一化、dropout和ReLU。然而,在几乎所有的任务中,批量归一化都是理所当然的使用。批次正则化已被证明可以平滑损失面,并对网络产生正则化效应,使其可以在更大的批次中进行训练。
然而,尽管性能有所提高,但批量规范化也有其缺点。这是一个相当昂贵的操作,更糟糕的是,它打破了训练实例之间的独立性。这也会导致模型在推理过程中和训练过程中的性能不一致,需要学习额外的隐藏超参数。因此,批量归一化是否能继续支持未来的模型是值得商榷的,而应该考虑它是否有不利的影响。有些人可能会觉得这里很奇怪。
在本文中,我们提出了自适应梯度裁剪(AGC),它主要是基于梯度法则与参数法则的单位比,AGC被用于NFNets,以获得ImageNet基准上的SOTA,尽管它没有使用正则化。经过对3亿张图片的预训练和在ImageNet上的微调,NFNet比使用BN(最佳模型)的模型更准确。在前89.5%1)。)
批量规范化如何帮助?
鉴于BN的优势和劣势,我们希望开发一种技术,在保留优势的同时消除劣势。那么我们来看看需要保留的东西。
残余分支的降级
鉴于BN的优势和劣势,我们希望开发一种技术,在保留优势的同时消除劣势。那么我们来看看需要保留的东西。
平移消除
ReLU等活化函数的平均活化度为非零。即使输入的点积接近于零,独立学习实例的激活的点积也较大,随着深度的增加,这个问题会越来越严重.在BN中,我们将每个通道的平均激活设置为零,并消除每一步的平均移动。
正规化效应
小批量计算的统计数据会引入一些噪声,提高准确性。
允许高效的大批量培训
BN平滑了损失面,可以实现更大的稳定学习率、更大的批次规模和更少的权重更新。
移除批次归一化
本文基于'Normalizer-Free ResNets',称为NF-ResNets,NF-ResNets使用残余块。
hi+1 =hi +αfi(hi/βi)
hi代表第i个残差块的输入。fi是方差,即Var(fi(z)) = Var(z)请注意,它认为βi = sqrt(Var()hi))是第i个残差块输入的标准差;和BN一样,这个残差块也有缩放激活的正效应,使得梯度更加稳定。为了防止均值偏移,NF-ResNets采用了标准化的标度权重,由(N为扇入)给出。

除此之外,激活函数(ReLU、GELU)还被激活函数特有的标量γ所缩放:在ReLU的情况下。γ = sqrt[2/(1 - (1/pi))]。.这样做的效果是撤消被比例权重标准化层改变的方差。此外,NF-ResNets还使用Dropout和Stochastic Depth作为正则化成分。
NF-ResNets与ImageNet上批量归一化的ResNets竞争,批量大小可达4096。但是,当批量大小超过4096时,性能往往会下降。更重要的是,性能不如EfficientNets。
建立更好的NF-ResNets
为了能够在更高的批次规模下训练NF-ResNets,我们首先尝试了梯度剪裁,它的工作原理是分配一个超出容忍度的梯度值。

但是,参数λ是不稳定的,必须根据批量大小的变化进行调整,模模型深度和学习率,而且必须根据模型深度的任何变化进行调整。为了解决这个问题, 。
自适应梯度裁剪(AGC)
梯度的法线与权重向量的法线之比,可以了解权重的变化程度。比值大,说明学习不稳定,需要剪裁梯度;我们不是一次计算一层的权重和梯度矩阵的规范,而是计算比值单位(行),利用这些信息剪裁梯度单位(行)。数学上,第i行的AGC与层权重ℓ的计算公式如下。

消融研究
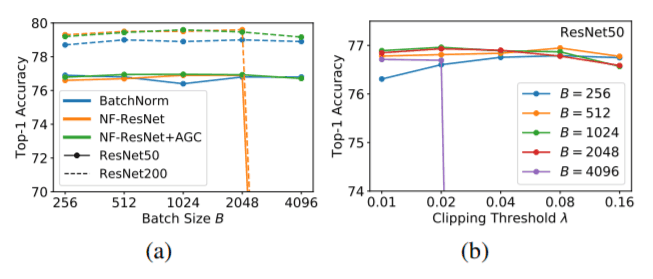
通过一系列的消融研究,我们发现NF-ResNet与AGC相比单独使用NF-ResNet能够以更高的批次规模进行训练。我们还发现,在较高的批次规模下,需要较小的剪裁阈值(<0.02)来进行训练。我们还发现,AGC对所有四个ResNet块组都是有效的。
相反,将AGC应用于最后的线性层会降低性能。
无归一化模型架构:NFN网 
NF-Net过渡段(左)和NF-Net非过渡段(右)
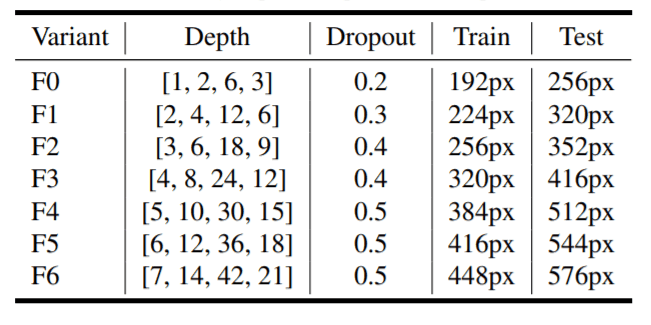 NF-Net的不同深度、落差和图像分辨率的变化。
NF-Net的不同深度、落差和图像分辨率的变化。
SF-Net可以通过对SE-ResNeXt中的GELU激活模型进行轻微修改来构建。如前所述,SE-ResNeXt中的所有GELU激活都由一个标量γ进行缩放,以保留方差。此外,除最后一个线性层外,所有权重都是基于AGC的。
有一个第一干有三个3x3 conv(两个有步幅2,一个有步幅1),将图像下采样成128通道的特征图。接下来的四个阶段,每个变种(F0到F6)的块数不同。如左上图所示,每个变体中的第一个块为过渡块,其余块为非过渡块。过渡块对特征图进行下采样,增加通道数。
每个块由1x1卷积组成,将该块的通道数减少到输出通道数的0.5倍。之后是两个3x3卷积,组宽恒定为128。最后,1x1卷积使通道数增加2倍(即等于块中输出通道数)。
实验和评估
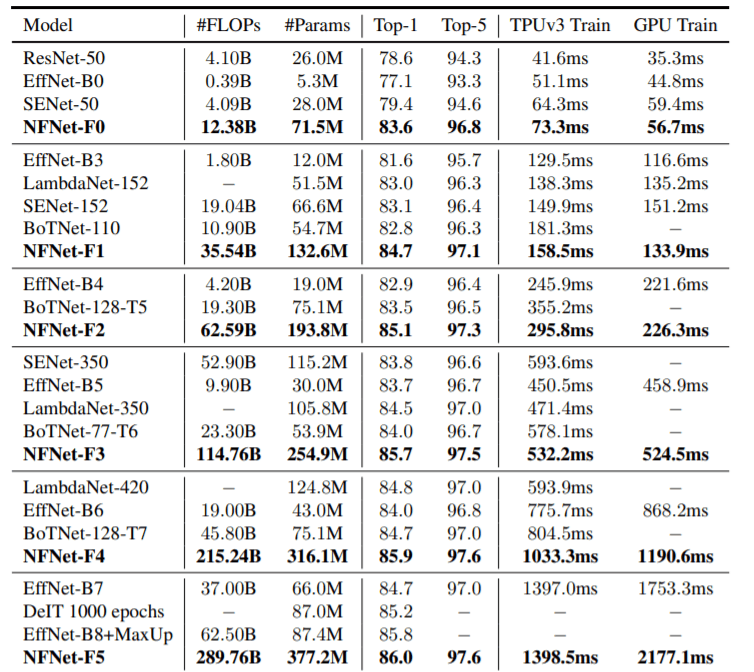
在ImageNet上比较NF-Net和SOTA模型。
上表显示了NFNet和ImageNet上其他最先进的模型在精度、模型大小(FLOPs和Params)和训练时间(单步)方面的比较,在GPU & TPU.NFNet-F5达到了86.0的精度,但参数数量和FLOPs数大;EfficientNet-B7的结果是NFNet-F1的8.7倍,在FLOPs数稍小的情况下,与之相当。
![]()
前期训练后的ImageNet的准确性
我们使用3亿张图像来预训练有BN的ResNets和无BN的NF-ResNets。在ImageNet上进行微调后得到的结果如上表所示。可以看出,NF-ResNets几乎在所有情况下都优于BN-ResNets。
结论
有趣的是,我们发现在图像识别任务中,没有BNs的模型与有BNs的模型相匹配,甚至优于有BNs的模型。模型保留了BN的最佳特征,部分模型的学习速度非常快。然而,本文并没有充分探讨没有归一化器的模型在NLP任务或其他视觉任务(如实例分割和对象检测)上是否同样表现良好。这些可能是今后研究的主题。详见本文。



与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



