视频识别]使用YouTube进行监督学习!新的视频识别框架OmniSource!
三个要点
✔️新的视频识别框架OmniSource获得SOTA认证
✔️。 利用Instagram和YouTube等网络上的图片和视频进行督导学习。
✔️联合训练克服了图像、短视频和未剪辑的长视频等数据格式之间的差异。
Omni-sourced Webly-supervised Learning for Video Recognition
written by Haodong Duan, Yue Zhao, Yuanjun Xiong, Wentao Liu, Dahua Lin
(Submitted on 29 Mar 2020 (v1), last revised 25 Aug 2020 (this version, v2))
Comments: Accepted to ECCV2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
official
comm
勾勒
这篇被ECCV2020接受的论文提出了一种新型的视频识别框架OmniSource。它克服了网络上各种数据格式的差异(如图像、短视频和未经修剪的长视频),通过网络监督学习实现了高精度的视频识别。
首先,收集具体任务数据,TEACHER MODEL将多种格式的数据转化为单一格式。其次,提出了一种称为联合训练的方法,以解决多种数据源和格式之间的领域差距。联合训练采用了数据平衡、重采样和交叉数据集混合等技术。
实验表明,OmniSource通过使用多种数据源和格式的数据,在训练中具有数据效率。在仅有350万张图片和80万分钟视频从互联网上抓取的情况下,在没有人工标注的情况下(不到之前研究的2%),OmniSource训练的模型在Kinetics-400基准上比2D和3D-ConvNet基线模型的表现要好3.0%。OmniSource也通过这种和其他的前期培训实现了SOTA。
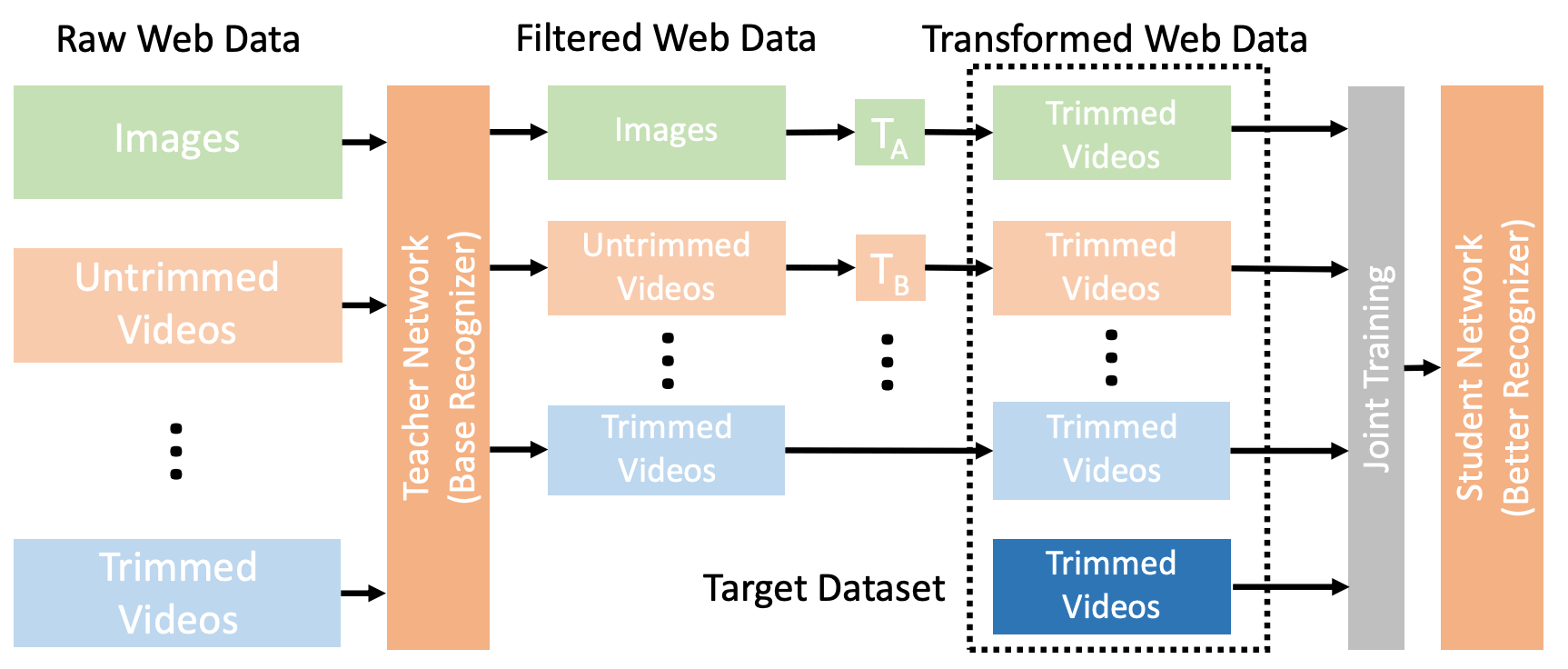
上图是OmniSource的概念图。首先,我们在感兴趣的数据集上训练一个教师网络。然后利用教师网提取各种收集到的网络数据,降低噪音,提高数据质量。我们还对每种格式的提取数据进行了特殊的转换。利用目标数据集和补充网络数据集对教师网络进行联合训练。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



