
VoxFormer "用于从图像中生成3D体积,在自动驾驶技术中具有潜在的应用。
三个要点
✔️ 基于Transformer的语义场景完成框架 "VoxFormer "的提议
✔️ 仅从二维图像输出全三维体积语义是可能的
✔️ LiDAR信息使用数据集的基于相机的方法
VoxFormer: Sparse Voxel Transformer for Camera-based 3D Semantic Scene Completion
written by Yiming Li, Zhiding Yu, Christopher Choy, Chaowei Xiao, Jose M. Alvarez, Sanja Fidler, Chen Feng, Anima Anandkumar
(Submitted on 23 Feb 2023 (v1), last revised 25 Mar 2023 (this version, v2))
Comments: CVPR 2023 Highlight
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Robotics (cs.RO)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
在过去的几年里,随着人工智能和信息技术的普及,自动驾驶的社会实施和普及的举措越来越多。尽管自动驾驶仍然存在许多挑战,但通过广泛使用驾驶记录仪和传感器以及其他各种方法,研究正在向更安全的驾驶方向发展。其中,图像处理技术往往负责该领域以及自动驾驶的发展和应用。
在自动驾驶的 "传感 "方面,通过三维手段对场景进行全面的概述是一个重要的问题。它对诸如自动驾驶车辆行程及其路线的规划等任务有直接影响。然而,由于传感技术不足、视角有限和遮挡造成的不完美,很难从现实世界中获得完美的三维信息。
本文描述的VoxFormer从图像中生成3D体积语义,以实现安全的自动驾驶,而不考虑相机和传感器的规格。
相关研究
为了解决从真实世界获取信息时出现的挑战,人们提出了一种完全从有限的观察范围推断场景的形状和意义的技术,称为语义场景完成(SSC)。SSC解决方案是基于从部分人类观察中预测整个场景及其意义。在预测的基础上,它同时解决了两个子任务:将场景重建到可见域和将场景虚幻地完成到隐藏域。然而,最先进的SSC方法和汽车驾驶中的人类感知之间存在着明显的差异。
许多现有的SSC解决方案也使用LiDAR(光探测和测距)作为主要传感器,以实现精确的三维形状测量。LiDAR技术。然而,LiDAR传感器很昂贵,而且不便于携带。
另一方面,诸如行车记录仪之类的摄像头价格低廉,可以接收驾驶场景的视觉线索信息。因此,基于摄像头的研究是以MonoScene作为SSC解决方案之一进行的;MonoScene使用高密度的特征投影将二维图像输入转换为三维。然而,这种投影不可避免地将可见域中的二维特征分配给空或遮挡的体素
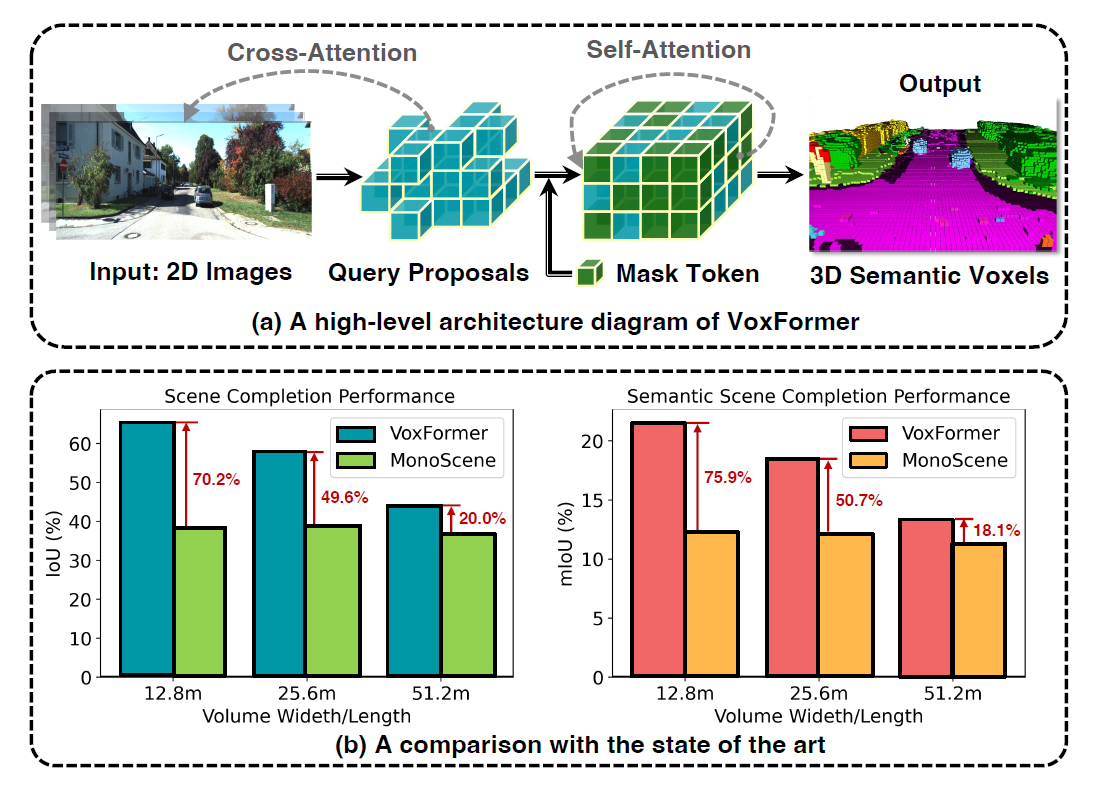 与MonoScene不同,本研究提出的VoxFormer考虑了三维到二维的交叉注意力,以表示稀疏的Query,并实现了以下四点
与MonoScene不同,本研究提出的VoxFormer考虑了三维到二维的交叉注意力,以表示稀疏的Query,并实现了以下四点
- 开发一个新的两阶段框架,将图像转化为全三维体素化语义场景。
- 建立一个网络,提出一个基于二维卷积的新查询,从图像深度产生可靠的查询。
- 类似于掩码自动编码器(MAE)的新转化器,用于全3D场景的表现。
- 使用SemanticKITTI数据集来实现基于摄像头的最先进的SSC方法。
VoxFormer的概述。
VoxFormer由一个独立于类的查询建议(Stage-1)和一个特定于类的语义分割(Stage2)组成;Stage-1提出一个稀疏的占用体素集,Stage-2表示Stage-1建议中的一个场景。
第一阶段有一个轻量级的基于CNN的查询建议网络,它使用图像深度重建场景形状。然后,它从全视野的预定义可训练的体素查询中提出一个稀疏的体素集。
第二阶段是基于一个新颖的从稀疏到密集的、类似于MAE的架构。它描述了提议的体素,将未提议的体素与可学习的掩码标记联系起来,并通过逐个体素的语义分割表示场景。
建筑
如下图所示,带有TransFormer的SSC从2D图像中学习3D体素特征。
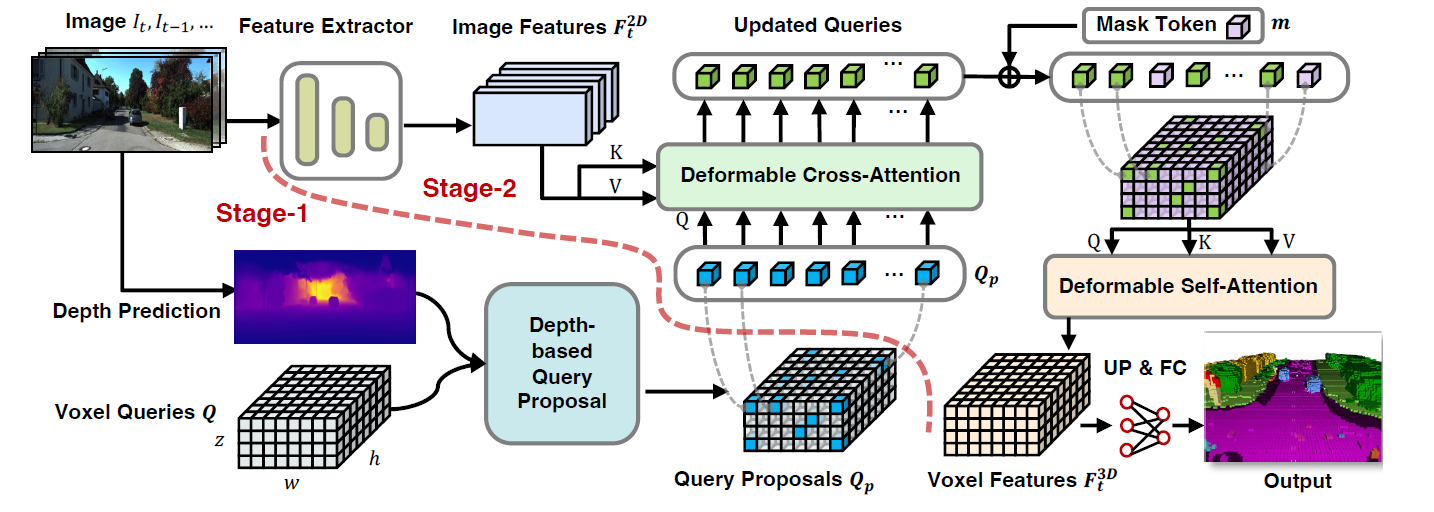
VoxFormer架构从RGB图像中提取二维特征,使用一组稀疏的三维体素查询,对这些二维特征进行索引,并使用相机投影矩阵将三维位置与图像流联系起来。
体素查询是一个可学习参数的三维格子,通过注意机制从图像中查询三维体积的特征。如上图左下角所示,共有Nq个体素查询被预先定义为三维格子状的可学习参数集群。
一些体素查询也被选为图像的重点,而其余的体素则与另一个可训练的参数相关联,以完成三维体素特征。这些参数被称为Mask tokens,它们表示预测的缺失体素的存在。
训练损失
用加权交叉熵损失研究Stage-2。
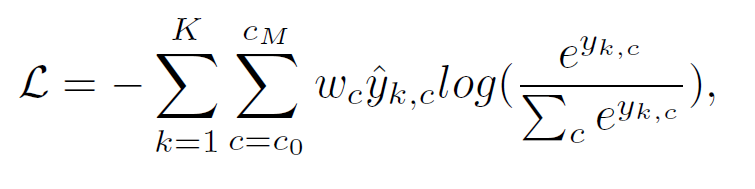
k:体素指数K:体素总数c:类别 指数
第1阶段采用二元交叉熵来预测空间分辨率较低的占用图。
实验
数据集
VoxFormer使用SemanticKITTI进行验证,这是一个LiDAR序列数据集 SemanticKITTI对 "KITTI Odometry Benchmark "的每个LiDAR扫描都进行了语义注释,该基准由22个户外驾驶场景组成。SemanticKITTI为 "KITTI Odometry Benchmark "的每个LiDAR扫描提供语义注释,该基准由22个户外驾驶场景组成。
安装
第1阶段。
MobileStereoNet被用来直接估计深度。 深度,像MobileStereoNet一样,可以只从立体图像生成低成本的伪激光雷达点云。
第2阶段。
cam2的RGB图像被裁剪成1220 x 370,使用ResNet50提取图像特征,第三阶段的特征使用FPN捕获,以生成输入图像大小的1/16的特征图。 还有两种类型的VoxFormer:VoxFormer-S和VoxFormer-T,前者只将当前图像作为输入,后者则将当前和之前的四幅图像作为输入。
评价
为了评估场景完成的质量,不管分配的语义标签是什么,我们采用了IoU(intersection over union)。作为一个基线,我们将最新的SSC与VoxFormer和公共资源在以下三点进行比较
- MonoScene,一种基于摄像头的SSC方法,基于2D到3D的特征投影。
- 基于LiDAR的SSC方法,包括JS3CNet、LMSCNet和SSCNet,以及
- RGB干扰基线LMSCNet和SSCNet以立体深度(MobileStereoNet)生成的伪激光雷达点云作为输入。
结果。
本文涵盖了与基于相机和基于LiDAR的方法进行比较的结果。
与基于摄像头的方法比较
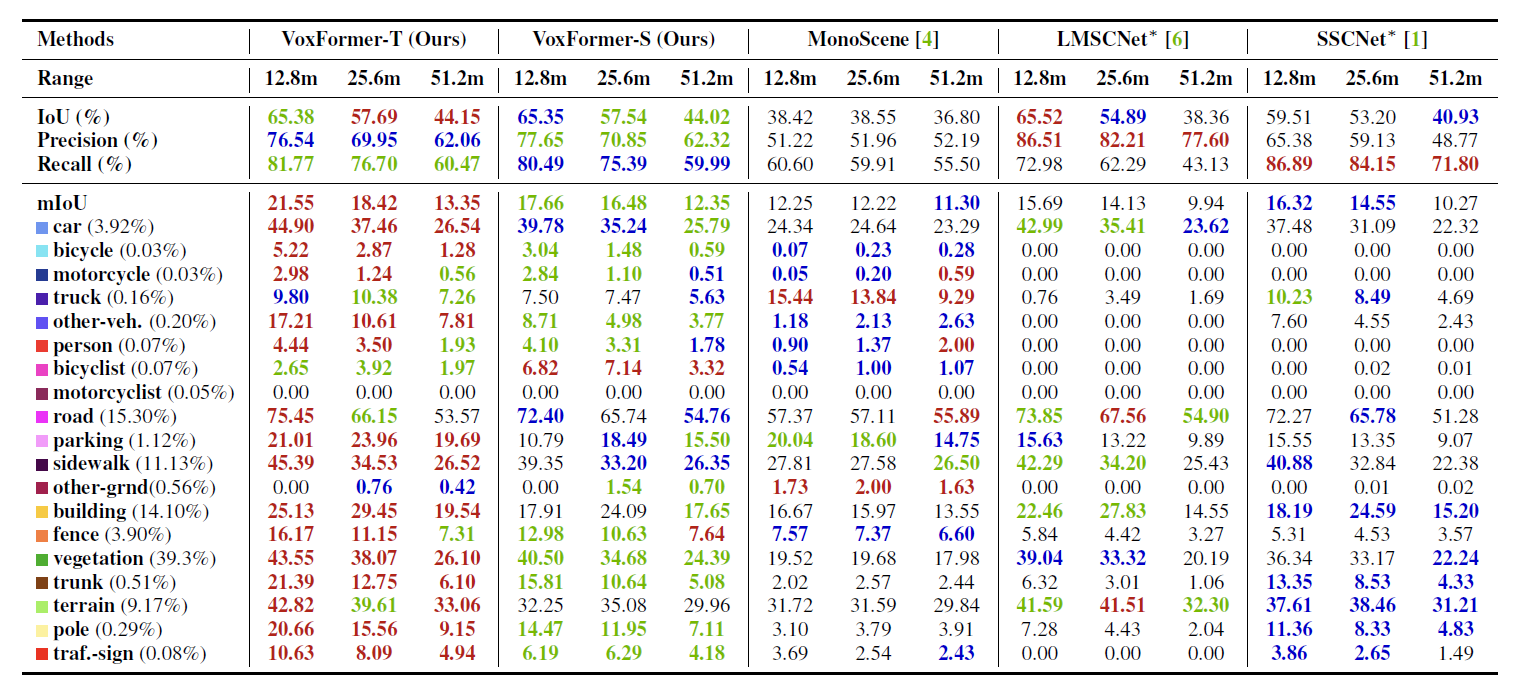 VoxFormer-S在几何互补性方面远远超过了MonoScene,表明阶段1提供了明确的深度估计和校正,在查询处理过程中减少了大量的空白。
VoxFormer-S在几何互补性方面远远超过了MonoScene,表明阶段1提供了明确的深度估计和校正,在查询处理过程中减少了大量的空白。
与基于LiDAR的方法比较
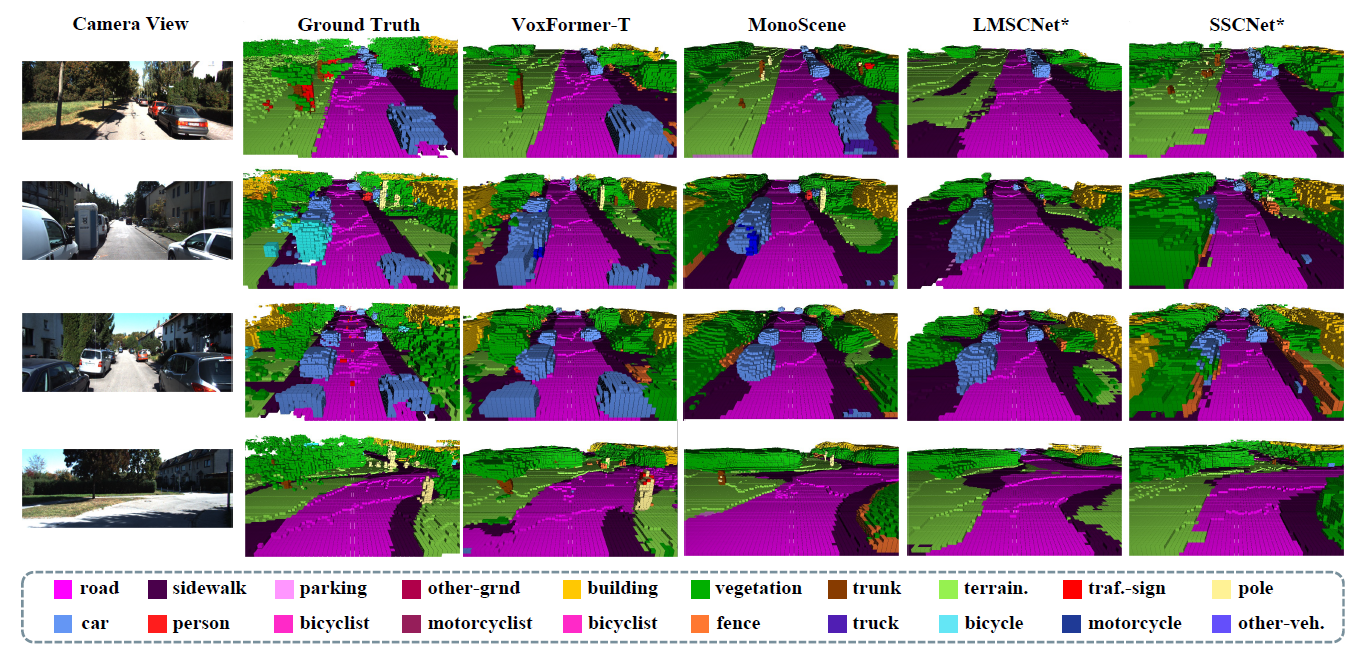
当接近Ego车辆(装有自动驾驶系统的车辆)时,可以直观地看到,基于LiDAR的方法和基于LiDAR的方法之间的性能差异变小。
摘要
对SemanticKITTI数据集的广泛测试表明,VoxFormer在几何完成和语义分割方面取得了最先进的性能。重要的是,在对安全至关重要的短距离领域,它比其他解决方案有明显的改进。此外,VoxFormer不需要昂贵的相机来推断,一个廉价的相机就足够了,因此不仅考虑了技术的进步,也考虑了现实世界实施的成本问题。
在未来,研究更精确的SSC解决方案,不需要昂贵的相机和传感器,如VoxFormer,将扩大自动驾驶技术的可能性。



与本文相关的类别
![[PETRv2] 仅使用摄像机图像估算物](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/petrv2-520x300.png)




