
简单!准确度高!异常检测模型PatchCore的吸引力
三个要点
✔️ 在MVTec数据集上实现SOTA,这是一个异常检测问题的基准!
✔️通过利用预训练的模型,不需要训练CNN的特征提取部分
✔️ 对从CNN获得的特征进行有效的采样,可以更快地进行推理。
Towards Total Recall in Industrial Anomaly Detection
written by Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Schölkopf, Thomas Brox, Peter Gehler
(Submitted on 15 Jun 2021 (v1), last revised 5 May 2022 (this version, v2))
Comments: Accepted to CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
异常检测问题是指在众多数据中检测出具有不同行为的数据的任务。本文特别讨论了工业图像数据的异常检测问题。
虽然在现实世界中获取正常图像相对容易,但要获取具有各种可能模式的异常图像却很困难。因此,人们提出了各种模型,通过只学习正常图像来识别异常图像。
本文提出了一个名为PatchCore的模型,该模型在基准MVTec数据集[1]上实现了SOTA。PatchCore最重要的特点是,它利用了从预先训练的模型中获得的特征,不需要在图像特征提取方面进行额外的训练。PatchCore最重要的特点是,它利用了从预先训练好的模型中获得的特征,不需要对图像特征提取进行额外的训练。
以下是关于PatchCore的更多信息。
补丁核心
整体模型
首先,介绍了PatchCore的概况。
PatchCore根据内存库中包含的正常图像的特征向量与要判断的图像(测试数据)的特征向量之间的距离计算出异常程度,并确定图像是正常还是异常。 它还可以获得图像中每个像素的异常程度,使其能够检测到异常区域。
下一节简要介绍PatchCore的学习和推理过程。
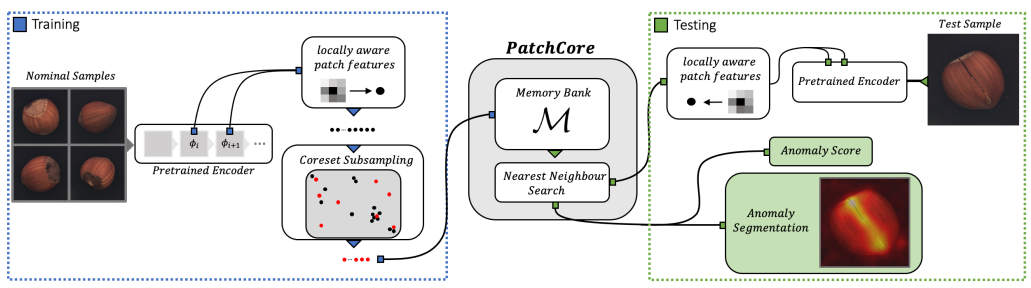
上图的左侧(蓝色虚线框)显示的是学习,右侧(绿色虚线框)显示的是推理流程。
在训练中只使用正常图像。图像通过训练后的CNN模型,以获得每个斑块①的特征向量,然后进行采样,并将选定的特征向量存储在记忆库中②。
因此,推理是通过一个记忆库来进行的,其中正常图像的特征向量已被积累。在推理过程中,图像也通过训练有素的CNN模型,以获得每个补丁的特征向量((i))。然后根据获得的特征向量和记忆库中的特征向量之间的距离计算图像和每个像素的异常情况(③)。
现在我们已经看到了PatchCore的学习和推理的全貌,下面我们进行详细的解释。特别是对上面描述中圈出的三个部分进行解释。
(i) 局部感知补丁特征。
第一个是局部感知的补丁特征,它从图像中获得一个逐个补丁的特征向量。
PatchCore使用一个CNN模型[2]从图像中获取特征向量,该模型已经在一个名为ImageNet的数据集上训练过。CNN模型的这一部分不会在你想确定正常或不正常的数据集上再次训练。
然后对从训练好的CNN模型得到的特征向量进行自适应平均池化。到此为止的过程可以用数学公式表示如下。
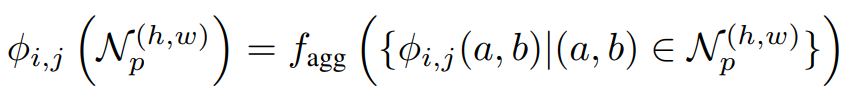
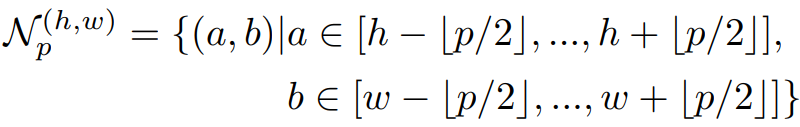
问题是应该使用训练好的CNN模型的哪一层的特征向量。一个可能的候选者是最后一层。
最后一层提供了最聚合的、高抽象度(高水平)的特征向量,在以前的研究中也有几个使用它的例子。然而,本文指出了使用从最后一层获得的特征向量的两个问题。
- 地方特色的丧失。
- 虽然深层的特征向量处于较高的水平,但由于重复卷积和集合,分辨率较低。这意味着局部(精细)特征可能会丢失。
- 在不同的领域(ImageNet分类问题)成为一个有偏见的特征。
- 假设训练过的模型是在一个与推理目标领域不同的任务上训练的,更深的层包含了更多针对该任务的特征。因此,有人认为,使用受不同领域任务影响的最后一层特征向量是不合适的。
因此,本文提出从训练好的模型的中间层获得特征向量,以便在尽可能高的水平上获得特征向量,并且尽量减少先前学习的影响,并通过实验验证了这种方法的有效性。
下图显示了获得特征向量的训练模型的层数(横轴:数字越小,越浅,越深)与异常检测任务的准确性之间的关系(纵轴:越大(向上),准确性越高)。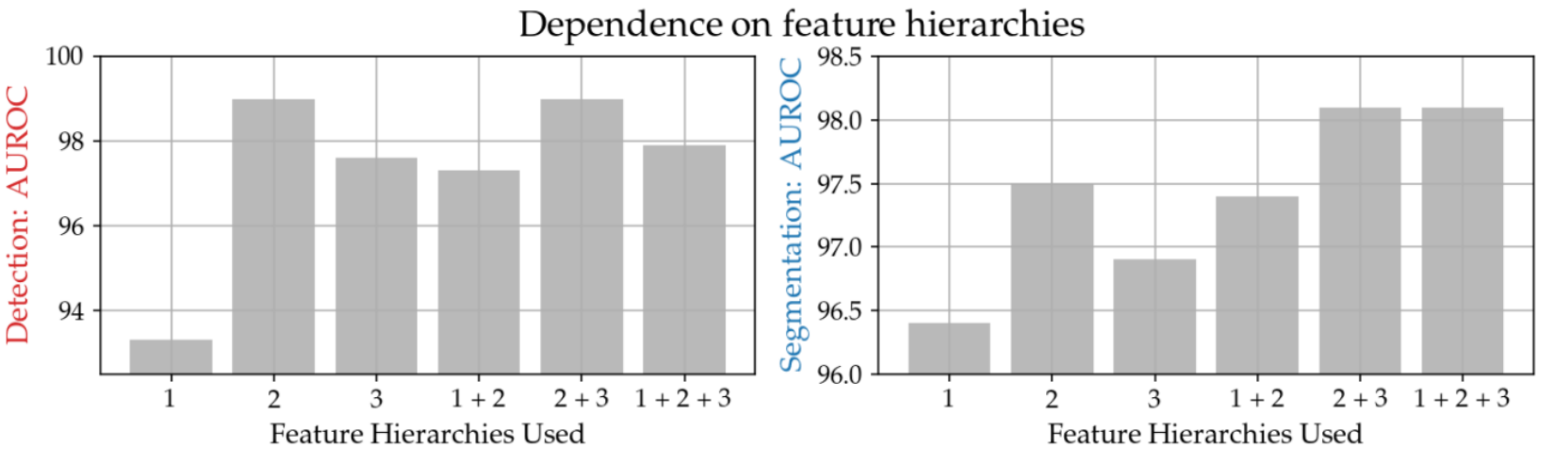
上图显示,对于包含中间层 "2 "的图案,准确率确实很高。这一结果表明,PatchCore从 "2 "和 "3 "层(2+3)获取了特征向量[3]。
(ii) Coreset-reduced patch-feature memory bank
其次是Coreset-reduced patch-feature memory bank,这部分是将(1)中得到的特征向量存储在Memory Bank中。
随着训练数据数量的增加,更多的数据需要存储在记忆库中,这增加了评估测试数据所需的推理时间,并增加了存储的内存容量。
因此,本文提出使用Coreset Sampling对(i)中得到的特征向量进行采样,并将其存储在Memory Bank中。
采样方法表示如下:其中M是采样前的特征向量集,MC是采样后的特征向量集。
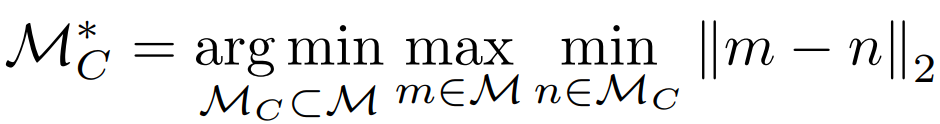
上述公式意味着,进行抽样时,要使预抽样的特征向量(m)和后抽样的特征向量中的最大最小距离最小。
然而,这个优化问题是NP-hard,需要大量的计算时间来获得最优解。因此,在本文中,采用了以下两种创新方法,以更快地获得一个接近最优的解决方案。
- 贪婪法的逼近
- 以前的研究中使用的方法已经被采纳。
- 通过随机投影降低维度。
- 降低特征向量的维度可以降低上述优化问题的计算复杂度,其依据是Johnson-Lindenstrauss补码,即降维可以实现良好的准确性。
本文研究了Coreset Sampling的有效性。
下图将Coreset Sampling应用于虚拟数据,并将结果可视化。
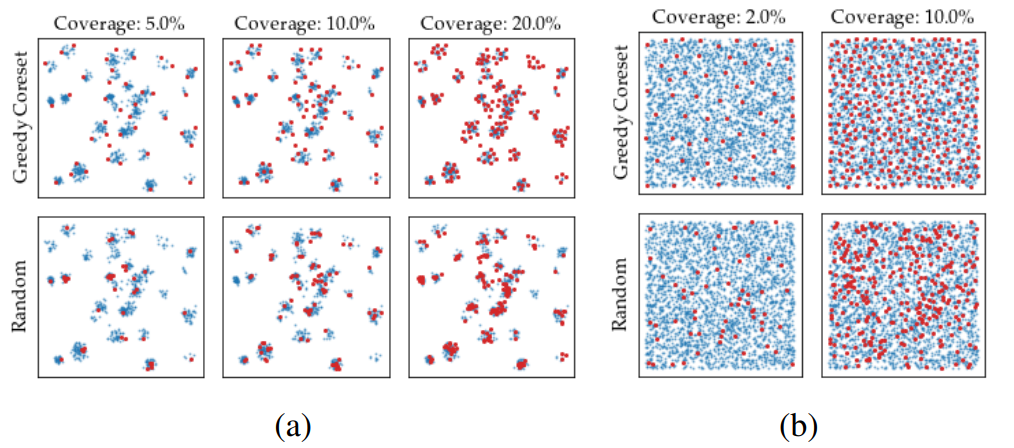
下表比较了随机抽样和Coreset抽样在两个虚拟数据集(a)和(b)上的结果,其中Coverage代表从原始抽样数据中减少的百分比。可以看出,上面的Coreset采样比下面的随机采样更有效率。
下图还显示了每种维度压缩方法在异常检测任务中的还原率(横轴)和准确性(纵轴)之间的关系。
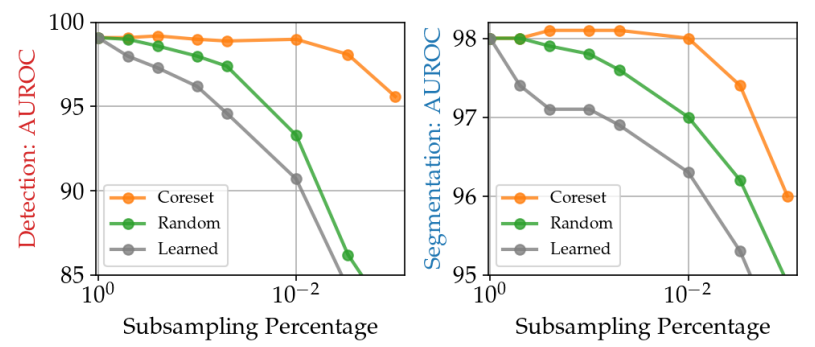
上图显示,在随机的情况下,当减少率达到约10-2时,准确率明显下降,而在Coreset(抽样)的情况下,准确率并没有下降那么多。因此,可以说Coreset Sampling是一种有效的抽样方法,可以减少数据的数量,同时保留异常检测所需的特征。
最后,到目前为止描述的存储库的整个算法显示如下。

(用PatchCore进行异常检测。
第三种是用PatchCore进行异常检测,它使用在(ii)中获得的记忆库来计算要判别的图像(测试数据)的异常程度。
最初,和训练时一样,测试数据图像通过训练好的CNN模型来获得每个补丁的特征向量。
根据以下公式,异常情况(s*)是由每块测试数据的特征向量(mtest)和存储在记忆库中的特征向量(m)计算出来的。
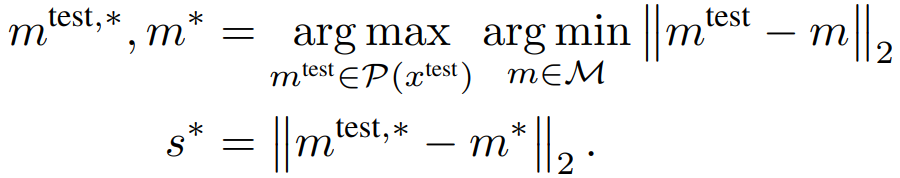
实验
实验装置
本文在三个不同的数据集上测试了所提方法的有效性。
第一个是MVTec数据集。它被广泛用作基准,有15个类别,包括瓶子、电缆和电网。这个数据集是本研究的主要重点。
第二个是磁砖缺陷(MTD)数据集。其任务是检测瓷片图像中的裂纹和划痕。
第三个是迷你上海科技园区(mSTC)数据集[4],它由12个不同场景的行人视频组成,任务是检测异常行为,如打架或骑自行车。
估值指数
接收者操作曲线下的面积(AUROC)被用来作为区分正常和异常图像的性能指标。按像素计算的AUROC(pixelwise AUROC)和PRO被用作检测适当异常的性能指标,其中PRO对异常的大小不太敏感。
结果。
我们从MVTec数据集[5]的结果开始。
下表显示了在AUROC中与传统方法的比较结果。

此外,下表显示了按像素计算的AUROC的结果。

对于PatchCore,分别以25%、10%和1%来改变存储库的子采样,结果显示PatchCore对于AUROC和像素AUROC都更准确。还可以看出,当存储库中的子采样百分比降低时,准确度并没有下降很多。
mSTC和MTD的结果显示在下表中。这些数据集的结果也超过了传统方法的准确性。

推理时间
下表显示了每种方法在MVTec数据集上的准确性(AUROC、像素AUROC和PRO)和推理时间。
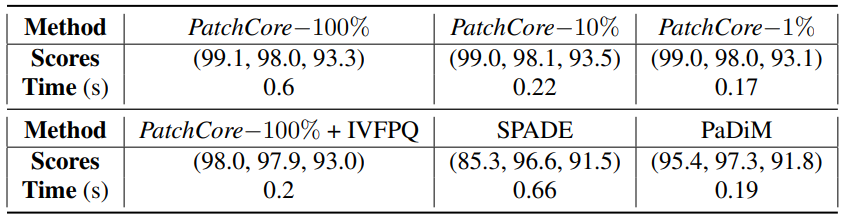
谈到PatchCore的结果,可以看出,推理时间因Coreset Sampling的百分比不同而有很大差异。特别是在1%的情况下,推理时间与100%的推理时间相差不大,这表明在保持比传统方法更高的精度的同时实现了快速推理。
摘要
会上介绍了在MVTec数据集上取得SOTA的PatchCore。
使用预训练模型的主要吸引力在于,特征提取部分(CNN)不需要训练,而且Coreset Sampling可以通过有效的特征采样减少推理时间。
虽然本文关注的是工业图像数据中的异常检测问题,但它可以应用于各种领域。
补充
[1] SOTA是在(图像)AUROC中实现的,它是区分正常和异常图像的准确性。
[2] 在ImageNet预训练的模型中,本文采用了ResNet50和WideResnet-50。
[3] 当使用两层时,获得的特征向量的维数(分辨率)是不同的。因此,对低分辨率的特征向量采用双线性插值,以统一维数。
[4] 原始STC数据集的视频帧每五帧进行一次子采样。
[5] 显示了15个类别的平均值的结果。



与本文相关的类别

![[PETRv2] 仅使用摄像机图像估算物](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/petrv2-520x300.png)




