
一种通过向法律硕士提供提示来提高推理能力的方法已经出现!
三个要点
✔️ 提出了渐进式提示法(PHP),这是一种遵循人类思维过程并使用先前答案作为提示的提示方法
✔️ 使用各种数据集和提示语进行的比较实验证明了其有效性
✔️ 模型和提示语研究发现,PHP 的性能越强大就越好
Progressive-Hint Prompting Improves Reasoning in Large Language Models
written by Chuanyang Zheng, Zhengying Liu, Enze Xie, Zhenguo Li, Yu Li
(Submitted on 19 Apr 2023 (v1), last revised 10 Aug 2023 (this version, v5))
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
虽然大规模语言模型(LLM)在各种自然语言处理任务中表现出了不俗的性能,但其推理能力在很大程度上取决于提示语的设计。
最近研究中出现的思维链(CoT)和自我一致性作为提高这些推理能力的重要方法,引起了人们的关注,但这些方法还不能充分利用 LLM 生成的答案。
另一方面,现有的研究还没有研究过使用 LLM 输出来迭代提高推理能力的方法是否有效,这与人类的思维过程是一样的。
本文提出了一种新的提示方法--渐进提示法(Progressive-Hint Prompting,PHP),它遵循人类的思维过程,利用过去的答案作为提示,并在重新评估问题后得出正确答案。本文将介绍如何通过使用各种 LLM 进行综合实验来证明其有效性。
渐进式提示(PHP)
人类思维过程的特点之一是,不仅能对答案进行一次思考,还能重新检查自己的回答。
本文提出了一种新的提示方法--渐进式提示(PHP),它通过依次使用语言模型中以前的应答来模拟这一过程。
PHP是一种提示技术,它使用先前生成的答案作为提示,实现用户与 LLM 之间的自动多重交互,一步步引导用户找到正确答案。
PHP 框架概览如下图所示。(紫色方框 = LLM 输入,黄色方框 = LLM 输出)
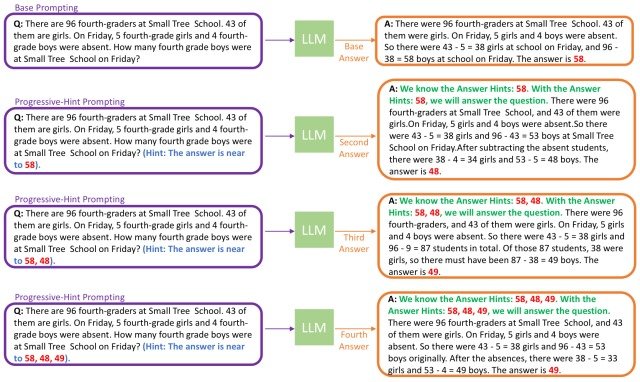
PHP 框架的结构是对生成的答案和组合进行双重检查,分为两个阶段。
在第一阶段(基本提示),当前问题和一个基本提示(如 CoT)被传递给 LLM,以生成一个基本答案。
在第二阶段(渐进式提示),答案通过 PHP-CoT 生成(如下所述),同时考虑到给出的提示(图中红色部分)。
然后,模型根据提示重复生成答案,当提示和模型生成的答案一致时,交换结束。(每次出现不匹配时,答案都会添加到提示中)。
本文提出的针对给定 CoT 提示生成 PHP-CoT 提示的过程如下所示。(蓝色:CoT 提示与 PHP-CoT 提示的区别,红色:设计提示中的提示)。

这一过程由两句话结构组成:在问题部分用一个短语表示答案的接近程度,在答案部分用一个短语复述提示。
根据 CoT 提示创建 PHP-CoT 提示时,首先在第一个问题后添加"答案接近 A"短语。(其中 A 代表一个可能的答案)。
接下来,潜在答案的开头句应为"我们知道答案提示:A。通过答案提示:A,我们将回答问题"。通过添加 "通过答案提示:A,我们将回答问题 "这句话,为 LLM 提供答案提示。
提示应针对各种情况,本提示的设计考虑了以下两种情况
- 如果线索与正确答案相同:即使线索正确,也允许模型推导出正确答案。
- 当线索与正确答案不一致时:使模型能够从错误答案中推导出正确答案。
这种设计使 PHP 能够遵循人类的思维过程,将以前的答案作为线索,并在得出正确答案之前重新评估问题。
实验
本文使用七个数据集(AddSub、MultiArith、SingleEQ、SVAMP、GSM8K、AQuA 和 MATH)和四个模型(text-davince-002、text-davince-003、GPT-3.5-Turbo 和 GPT-4)对 PHP 的推理能力进行了评估。5-Turbo 和 GPT-4)进行了综合比较实验。
此外,还使用了三种提示--标准提示(普通提示)、CoT 和复杂 CoT(强调提示复杂性并选择最复杂问题和答案的 CoT)--来比较它们的表现。
实验结果如下图所示。
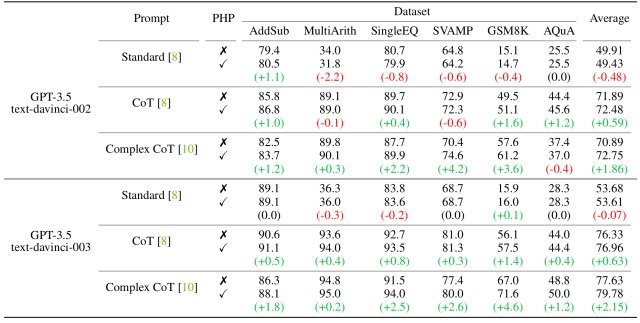
值得注意的是,模型和提示功能越强大,PHP 的性能就越好。
关于模型,在使用 CoT Prompt 验证时,text-davince-002 在添加提示后出现了一些性能下降,而用 text-davince-003 代替后,性能得到了持续和显著的提高。
同样,在 AQuA 数据集上使用 PHP-Complex CoT 时,text-davince-002 的性能损失为 0.4%,而 text-davince-003 的性能提高了 1.2%。
结果表明,PHP 在应用于强模型时最为有效。
在提示方面,标准的 "标准提示 "在加入 PHP 后略有改进,而 "CoT 提示 "和 "复杂 CoT 提示 "的性能则有显著提高。
此外,与其他两个提示相比,功能最强大的提示--复杂 CoT 提示的性能提升最为显著。
结果表明,好的提示能提高 PHP 的有效性。
论文还分析了每种模式和提示的交互次数(即代理人在得到明确答案之前需要参考法律硕士的次数)的变化。
下图显示了结果。
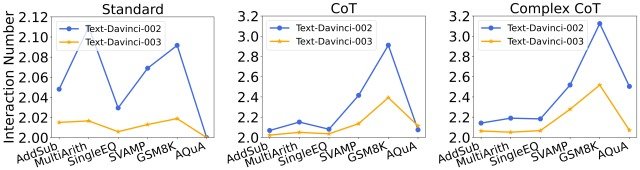
结果表明
- 在同样的提示下,文本-davince-003 中的互动次数低于文本-davince-002 中的互动次数
- 这是因为文本-davince-003 的准确性提高了基本答案和后续答案正确的概率,减少了获得最终正确答案所需的交互次数。
- 如果使用相同的模型,互动编号会随着提示功能的增强而增加
- 这是因为提示越强,法律硕士的推理能力就越强,他们就越能利用提示摆脱错误答案的困扰,而他们需要更多的互动次数才能得出最终的正确答案。
这项分析表明,更强的模型会减少互动次数,而更强的提示会增加互动次数。
摘要
它是如何做到的?在这篇文章中,我们提出了一种新的提示方法--渐进提示法(Progressive-Hint Prompting,PHP),它遵循人的思维过程,利用以前的答案作为提示,并在重新评估问题后得出正确答案,并通过使用各种 LLM 的综合实验证明了它的有效性。对论文进行了描述。
实验证明了 PHP 在各种数据集上的有效性,并证实通过使用更强大的模型和提示,其性能还能进一步提高。
另一方面,目前的 PHP 与 Chain-of-Thought 等其他技术一样,都是由人工创建的,这就导致其实施效率低下。
作者指出,未来的研究旨在设计和提高自动渐进式提示的实施效率,以解决这一问题,因此我们期待着进一步的进展。
本文中介绍的 PHP 框架和实验结果的详细信息,请参阅本文,供有兴趣者参考。



与本文相关的类别



![[情感提示] 情感提示输入可提高 LLM](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/emotionprompt-520x300.png)
