修剪时不需要一个大模型?自动寻找稀疏网络!
三个要点
✔️ 基于$ l_0$正则化的新近似的新修剪方法
✔️ 比基于启发式的修剪(如幅度和梯度)性能更高
✔️ 当子网络搜索以并行方式进行时,效率尤其高。
Winning the lottery with continuous sparsification
Written by Pedro Savarese, Hugo Silva, Michael Maire
(Submitted on 11 Jan 2021)
Comments: Published as a conference paper at NeurIPS 2020
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:.
首先
修剪是一种用于减少深度神经网络权重的技术,以创建一个轻量级的模型。传统上,分支修剪方法是基于使用网络权重和梯度的启发式方法,但目前还不清楚这些指标是否真正适合作为分支修剪指标。
在本文中,我们提供了使用$ l_0 $正则化作为非启发式方法的最佳分支修剪。我们还提供了一种与彩票假说相结合的具有$ l_0 $正则化的子网络搜索方法。
实验发现,与彩票假说迭代幅度修剪相比,稀疏化的网络很好,在搜索子网络时更准确。
$ l_0 $ 通过正则化进行修剪
一种约束网络权重为零,即稀疏的正则化方法是$ l_0 $正则化。通过在损失函数中加入$ l_0$,可以在网络的训练过程中对网络进行适当的修剪。另外,由于它不是启发式的措施,网络会自动找到要删除的权重。
然而,$L_0$正则化不是可分的。因此。作为一种对策,以前的研究使用了产生0和1的掩码的概率分布。然而,有一个问题是,由于分布的偏差和方差,生成的掩码并不稳定。此外,彩票假说中的子网络搜索方法使用启发式措施来减少网络,但不清楚这些措施是否明确指出要减少的权重。
因此,在本文中,我们回顾了$ l_0 $的公式回顾了正则化公式,提出了一种近似确定性$ l_0$正则化的方法,并将该方法应用于子网络搜索以实现SOTA。
建议的方法(连续稀疏化)
化项的损失最小化问题是$$\min _{w \in \mathbb{R}^{d}} L(f(\cdot ; w))+\lambda \cdot\|w\|_{0}$$
接下来,我们介绍一下掩码$ m in\{0,1\}^{d} $。 $$\min _{w \in \mathbb{R}^{d}, m \in\{0,1\}^{d}} L(f(\cdot ; m \odot w))+\lambda \cdot\|m\|_{1}$$
掩码$ m $是一个布尔值,所以$ |m\|_{0} = |m\|_{1} $。 因此,我们可以将$ l_0 $的规则化改为$ l_1 $的规则化。 因为$m$是一个布尔值,它不能用最陡峭下降法进行微分。 我们首先引入一个Heaviside函数来使惩罚项可微:$$ \min _{w \in \mathbb{R}^{d}, s \in \mathbb{R}_{\neq 0}^{d}} L(f(\cdot ; H(s) \odot w))+\lambda \cdot\|H(s)\|_{1} $$
$s$是要最小化的新变量,如果$s$通过Heaviside函数为正,则掩码为1,如果为负,则掩码为0。 接下来,我们进一步将该表达式转化为可微调。
转化为可微调的表达是$$ L_{\beta}(w, s):=L(f(\cdot ; \sigma(\beta s) \odot w))+\lambda \cdot\|\sigma(\beta s)\|_{1} $$ 我们使用新的sigmoid函数$sigma$ 另外,$\beta\in[1, \infty)$是一个超参数,在训练期间由用户决定。
当$Beta$接近于$infty$时,$\lim _{\beta \rightarrow \infty} \sigma(\beta s)=H(s)$就成立了。 另一方面,当$beta=1$时,$sigma(\beta s)=sigma(s)$成立。 因此,以下公式成立。
$$ \min _{w \in \mathbb{R}^{d} \atop s \in \mathbb{R}_{\neq 0}^{d}} \lim _{\beta \rightarrow \infty} L_{\beta}(w, s)=\min _{w \in \mathbb{R}^{d} \atop s \in \mathbb{R}_{\neq 0}^{d}} L(f(\cdot ; H(s) \odot w))+\lambda \cdot\|H(s)\|_{1} $$
$beta$是一个超参数,控制着计算的难度。 通过在训练过程中逐渐增加$\beta$,人们可能成功地逼近难以解决的问题(从数字连接中得出)。
实验结果
在本文中,我们主要比较了基于抽签假说的子网络生成与传统剪枝的性能。首先,在生成子网络的能力方面,所提出的方法与迭代幅度修剪(一种基于幅度的修剪)进行了比较。
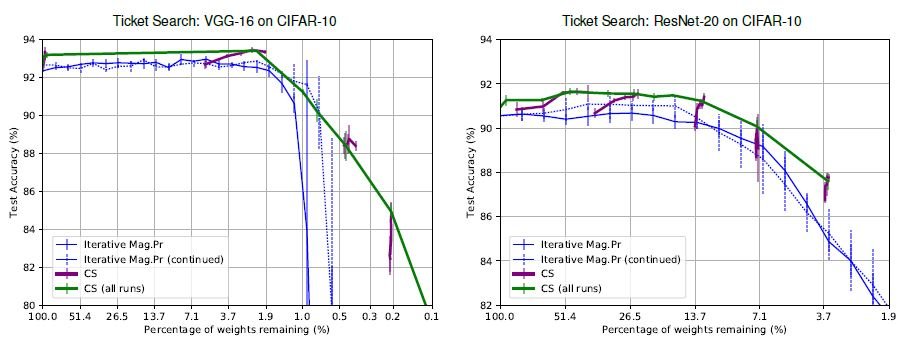
在CIFAR-10上训练的VGG-16和ResNet-20上探索了子网络,所提出的方法(CS)在这两种情况下都占优势。
迭代Mag.Pr是一种基于规模的子网络搜索方法,用于通常的抽签假设。通常情况下,当分支修剪分多轮进行时,在一轮中学习的权重被重置为初始权重,但迭代Mag.Pr(续),在这里我们没有让思想重置,即使是在轮回切换的时候。
CS是提出的方法,CS(所有运行)是总结每个实验的结果并连接每个点的结果。值得注意的是,即使在增加分支修剪率的情况下,所提出的方法的准确性也不会降低。我认为当树枝修剪到极限时,这种效果是有效的。
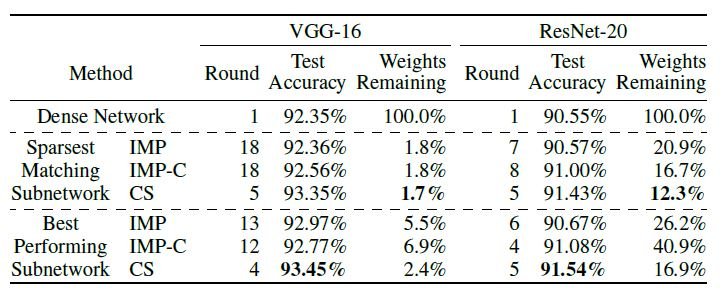
在保持与基线网络相同性能的情况下,在最稀疏网络的比较中,所提出的方法能够找到更多的稀疏子网络,对于VGG-16和ResNet-20,分别为1.7%和12.3%。
在比较性能最好的子网络时,我们还VGG-16为93.45%,ResNet-20为91.54%,我们发现高度准确的网络。此外,尽管有良好的准确性,但我们实现了较高的分支修剪率。与IMP相比,训练所需的子弹数量要少得多。因此,有可能快速找到子网络。接下来是传统的启发式修剪方法和建议的方法的比较结果。
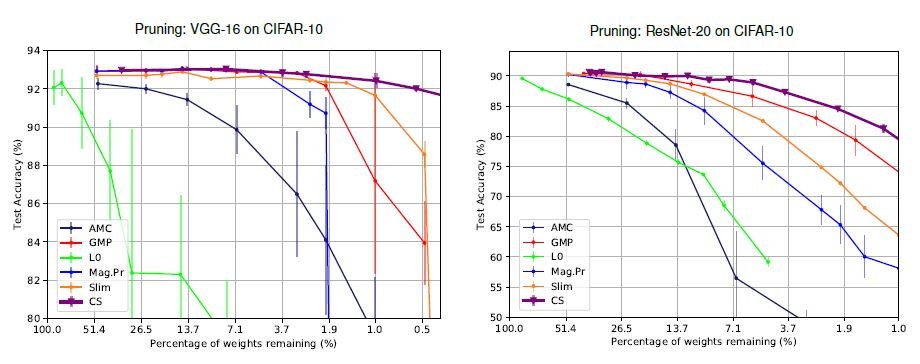
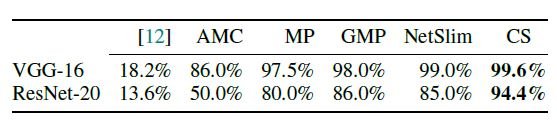
与传统的启发式方法不同,没有突然的与传统的启发式方法不同,准确度没有突然下降,而且与传统的启发式方法不同,准确度没有突然下降,而且准确度保持在一个较高的水平。此外,传统的L0正则化方法是不稳定的,在VGG-16和ResNet-20中都给出了最差的结果。
摘要
本文提出了一种新的$ l_0 $正则化近似方法,并将其应用于子网络搜索,以处理传统的$ l_0 $正则化修剪不稳定,子网络搜索方法只是启发式的,其有效性无法评价的问题。我们在子网络搜索和修剪方面都实现了SOTA。
所提出的方法优于其他方法,因为即使修剪率很高,它也能保持准确性。此外,如果有并行计算,拟议的方法可以比其他方法更快地找到子网络。
特别值得注意的是,所提出的方法在较少的回合中找到了稀疏和高度精确的网络。在传统的剪枝法中,很难直接创建小模型,所以一般都是从大模型中创建小模型。然而,所提出的方法在原始网络的学习过程中及早发现了好的子网络。这与我认为这提出了一个关于传统的训练后修剪的问题。
正如本文提到的,转移学习和修剪的结合也是一个有趣的话题,因为已经证明子网络可以在类似和不同的任务之间转移。



与本文相关的类别


