
使用MA强化学习的自主无人机控制的重新造林方法。
三个要点
✔️ 提出了一种使用强化学习的自主无人机在难以到达的地区重新造林的方法。
✔️ 证明多代理强化学习系统的通信机制能够在只有部分可观察的环境中进行协作。
✔️ 建立一个模拟环境,根据地形和森林信息产生不同难度的场景。
Dynamic Collaborative Multi-Agent Reinforcement Learning Communication for Autonomous Drone Reforestation
written by Philipp Dominic Siedler
(Submitted on 14 Nov 2022)
Comments: Deep Reinforcement Learning Workshop at the 36th Conference on Neural Information Processing Systems (NeurIPS 2022)
Subjects: Artificial Intelligence (cs.AI); Machine Learning (cs.LG); Multiagent Systems (cs.MA); Robotics (cs.RO)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
这些天来,我们经常听到诸如 "数字双胞胎 "和 "从模拟到现实 "的术语。诸如此类的举措越来越多地被用来根据模拟环境的信息在现实世界中移动机器人和无人机。他们还试图通过使用机器学习和强化学习来提高准确性和自动化。
然而,利用人工智能对无人机进行集体控制,在现实世界中这样做会带来一些问题。例如,不可否认的是,无人机有可能控制不当而撞到人。然而,通过使用假设有各种类型事故的模拟环境,可以减少这些事故。另外 ,有利益关系的群体或个人可以被看作是有代理的实体,在现实世界中,他们需要合作以实现更高的目标 。这可以被描述为一个多代理系统,强化学习经常被用于机器人和无人机的集体行为,包括数字双胞胎。

本文描述的研究提出了一种方法,在分散的环境中集体控制自主无人机进行通信,可以在难以到达的地区重新造林。
概述。
其目的是用一个分散的自治系统来重新造林,该系统由各个代理组成,可以在各种情况下做出具体决定。它使用近似策略优化(PPO),一种最先进的强化学习算法,来控制多个代理的集合体,其任务是拾取树种,沿着现有森林的周边找到合适的地点进行重新造林、种植它们。此外,MA集合体可以通过通信手段进行交流。还开发了一个模拟环境来训练和测试不同的学习机制。这个环境可以容纳开放式的学习,生成由于地形的拓扑结构和森林的稀疏性而可能具有挑战性的场景。
在进入详细的方法之前,作为先验知识,对本研究中使用的PPO和图形神经网络进行了简单的描述。
近端政策优化(PPO)
PPO算法的定义主要有两个方面。
- PPO通过估计置信区来执行最大和最安全的梯度上升学习步骤。
- 优势估计某一特定状态下的行为与平均行为相比要好多少。
优势也可以被描述为Q函数和价值函数之间的差异。
图形神经网络 (GNN)
GNN的基本功能是对图、节点和边进行分类。节点和边的特征和存在可以通过相邻的节点和现有的边来预测。
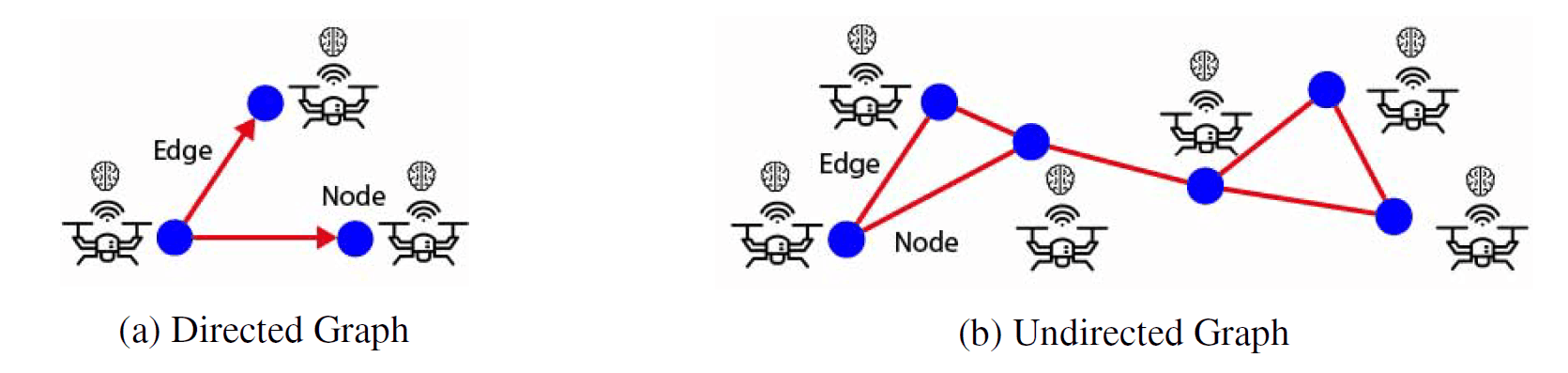 一个由顶点(蓝点)和边(红线)组成的图。
一个由顶点(蓝点)和边(红线)组成的图。
图是一种基于节点或顶点和边的数据结构(见上文),其中节点和边对象可以容纳任意数量的任何类型的特征。一个边代表两个节点之间的关系,一个节点可以与其他节点有无限数量的关系边。此外,使用节点和边缘特征以及图的拓扑结构作为输入,可以实现对整个图的分类。
方法
这些方法大致分为无人机模拟环境、代理设置和无人机之间的通信。
仿真环境

一个多代理(MA)基线和多代理通信设置(MAC)模拟以及在Unity中开发的3D重新造林环境被用于在线培训。在这个环境中,代理人通过从无人机站取回树种、寻找种植树种的最佳地点、丢弃树种、为电池充电和返回无人机站取回下一个树种来解决问题。
所有环境情景的变化都包括以下内容
- 使用八度空间、持久性和基于裂隙的噪音,程序性地生成地形。
- 安排在固定高度区域的树木(森林),与随机噪声地图相结合,只显示肥沃的土地(这里是绿草)。
- 人类的用户界面可以显示出最佳和最有价值的重新造林区域
- 仅在人类用户界面上显示的高度热图。
- 定义最近的邻居的网络,只在人类用户界面上以青色动态显示。
代理人设置
以下项目是作为代理设置的一部分提供的。
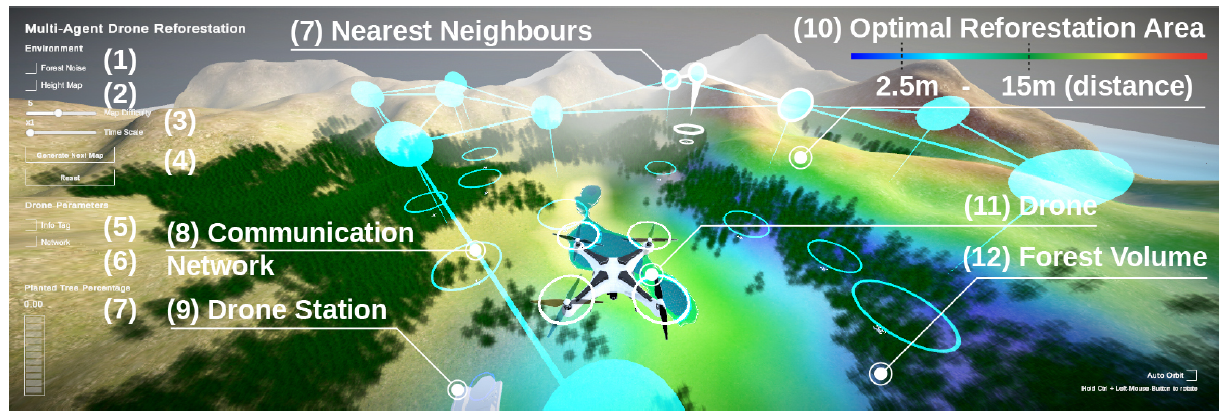
目标:每个代理人学会引导无人机到无人机站,在那里自动提供服务,捡拾树种并给电池充电。然后,他们操纵无人机找到放下树种的最佳地点并返回无人机站,同时检查电池电量。
奖励功能: 特工的奖励功能由几个部分组成。如果你没有持有种子,你的奖励会随着你接近无人机站而增加,无论距离远近,累积起来总共有+20。此外,根据树种掉落的位置,可获得+0~+30的奖励。
矢量观测: 所有的矢量观测都被规范化。最终矢量观测的空间大小为30,由两个堆叠的15个描述的观测值组成。
视觉观察: 视觉观察是由安装在每架无人机上的视野为120-256个单元的朝下相机拍摄的16x16灰度网格,每个单元的浮动值在[0-1]范围内。这导致总的观测空间大小为286。
连续动作:每个代理有三个连续动作,数值范围从-1到1。连续动作控制无人机的运动。动作0控制前进和后退,动作1控制旋转和左/右,动作2控制无人机的上下移动。无人机还以每个时间步长为1米的速度移动。
离散行动:离散行动的空间大小为2,可以描述为两个数值为[0,1]的树。离散动作0以数值1丢弃树的种子,而动作1以数值1存储在内存中的位置。如果数值为0,这两个动作都不做。
多Agent通信
这种学习机制允许代理接收图形结构的数据。当无人机相互之间在200米范围内时,可以交换信息。此外,总共可以收到三条消息,对应于多代理通信配置(MAC)中的三个附近实体。如果附近只有两架无人机,则分别只发送和接收两条消息。发送和接收信息没有任何成本,也不会获得负面或正面的奖励。

实验
在实验中,四个不同的设置被训练。
 实验环境
实验环境
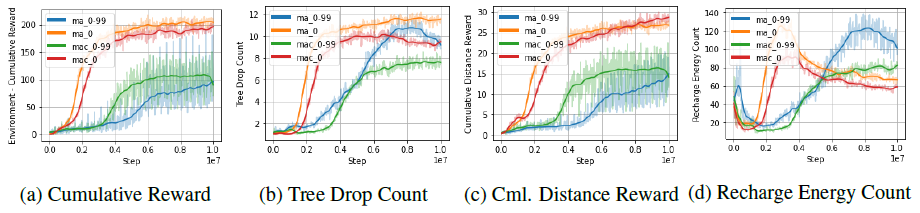 训练图
训练图
没有通信能力的多Agent设置为基线;实验1和实验2在没有通信能力的情况下进行训练;实验1在随机种子为0的地形场景中进行训练,而实验2在具有随机种子的一系列地形场景中进行,随机种子从0到99。 实验还将在具有通信能力的多Agent环境中进行。实验3和实验4将被训练为具有通信能力。实验3是一个随机种子为0的地形场景,实验4是一个随机种子为在一系列随机种子范围为0到99的地形场景中训练。 然后,所有的实验都在随机种子为111的未见过的地形场景中测试。
结果。
结果显示,多Agent的通信超过了没有通信的多Agent的基线设置。
 实验结果
实验结果
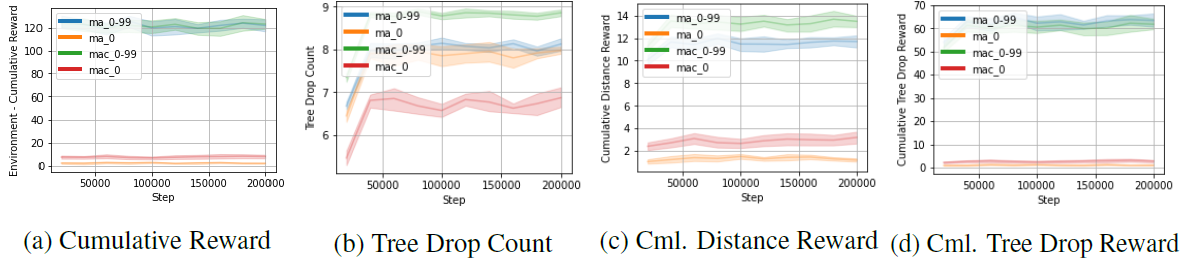 测试图
测试图
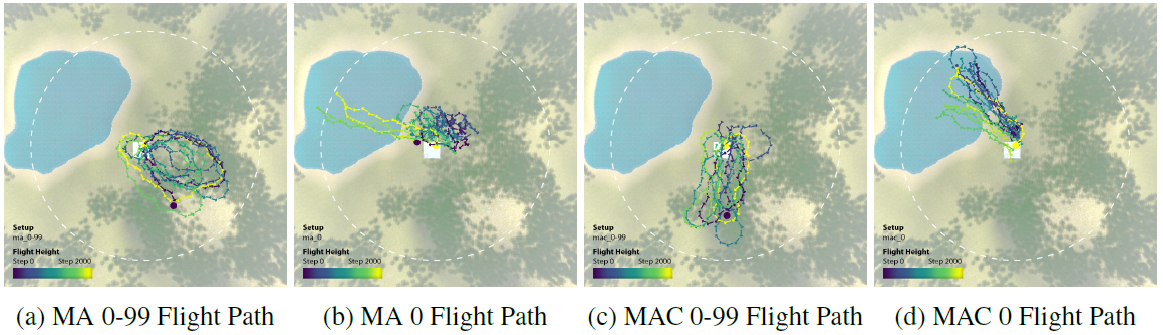
在具有0-99的随机种子的地形场景中训练的MA 0-99集在累积奖励方面表现非常好。与在单一地形场景中训练的代理相比,在多个场景中训练的代理表现得更好,差距很大。此外,据观察,由于通信的原因,MAC 0-99集实现了最高数量的树木掉落,并走得最远的探索(见下文)。
摘要
这项研究探索了一种自主无人机重新造林的方法,该方法使用了带有图形神经网络(GNN)通信层的多代理强化学习(MARL)。结果显示,该系统能够应对未知的地形,而且通信能力提高了多代理人群的性能。此外,模拟环境和真实世界之间仍有许多差距。
如果未来与这种数字双胞胎有关的研究取得进展,可以预计虚拟环境的应用范围将扩大,如元空间。如果能够建立一种机制,利用虚拟环境的优势,将其纳入现实,这将导致新的技术发展。



与本文相关的类别





