
VFS:使用价值函数对长距离任务进行有效的重新定位。
三个要点
✔️ 提出一个由低级技能的价值函数组成的表示方法--价值函数空间。
✔️ 与基线方法相比,无模型RL和基于模型的RL的成功率更高。
✔️ 无模型RL实验显示出对未知环境的高泛化性能
Value Function Spaces: Skill-Centric State Abstractions for Long-Horizon Reasoning
written by Dhruv Shah, Peng Xu, Yao Lu, Ted Xiao, Alexander Toshev, Sergey Levine, Brian Ichter
(Submitted on 4 Nov 2021 (v1), last revised 29 Mar 2022 (this version, v2))
Comments: Accepted to ICLR 2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Robotics (cs.RO)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
背景
强化学习(RL)越来越能够学习和解决各种复杂的任务,但它的性能会随着解决一个任务的时间越长而下降(地平线)。在分层强化学习(Hierarchical RL)中,对于具有长视野的任务,具有短视野的技能,称为低级技能(例如,在机器人中抓取和放置物体),被抽象为行动(行动有人努力通过把它作为一个抽象来解决这个问题)。这种层次化的RL也可以改善状态抽象本身。
在本文中,我们认为状态抽象是由低级技能策略在其环境条件下执行技能的能力决定的,我们用RL学习的低级技能策略的价值函数为提出了用作状态抽象的 "价值函数空间"。
在本文中,我们表明,价值函数空间改善了无模型和基于模型的长线任务的性能,同时也改善了零点泛化的性能。与以前的方法相比,性能也被证明是有改进的。
下面几章将介绍详细的方法和实验。
技术
RL中的价值函数可以被认为与负担能力有非常密切的关系,价值函数表示所学技能的可行性。利用这一特性,可以创建一个以技能为中心的环境状态表示,由代表低级技能承受力的技能值函数组成,以执行高级规划。这是对本文主要方法的概述。详细的方法将在本章中解释。
第一个假设是,每个技能都是由稀疏的奖励来训练的,所以每个值的最大值是1。假设半马尔科夫决策过程(SMDP)$M(S, O, R, P, \tau, \gamma)$,并且如果训练了k个技能,使用每个技能的价值函数$V_{o_{i}}$,以技能为中心的表示是一个k维的表示$Z(s_{t}) =[V_{o_{1}}(s_{t}), V_{o_{2}}(s_{t}),..., V_{o_{k}}(s_{t})]$。在本文中,这种表示法被称为价值函数空间(VFS)。
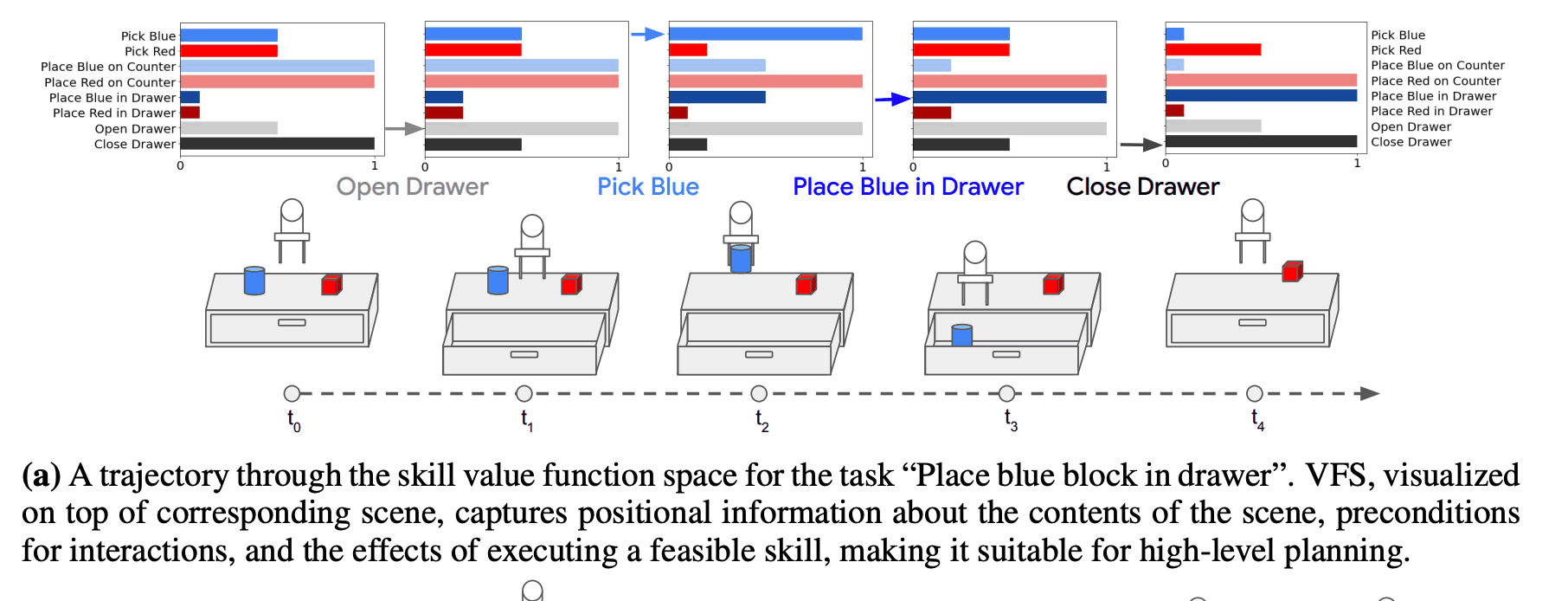
下图说明了办公桌重新排列任务中的状态抽象。首先,一个观察,如图像,被抽象成一个由八个技能组成的八维价值函数元组。这种表示法也持有关于位置的信息,例如,如果一个抽屉被关闭,相应技能的值为1,因为任务已经完成。除此之外,还有互动的前提条件(例如,"挑选 "技能的高值意味着两个积木已经准备好被吊起),以及执行可行技能的效果(例如,"打开抽屉 "技能的值为$t_{1}$,如在${}$执行时其价值增加,可以认为非常适用于高层规划,因为VFS包含系统价值的信息。
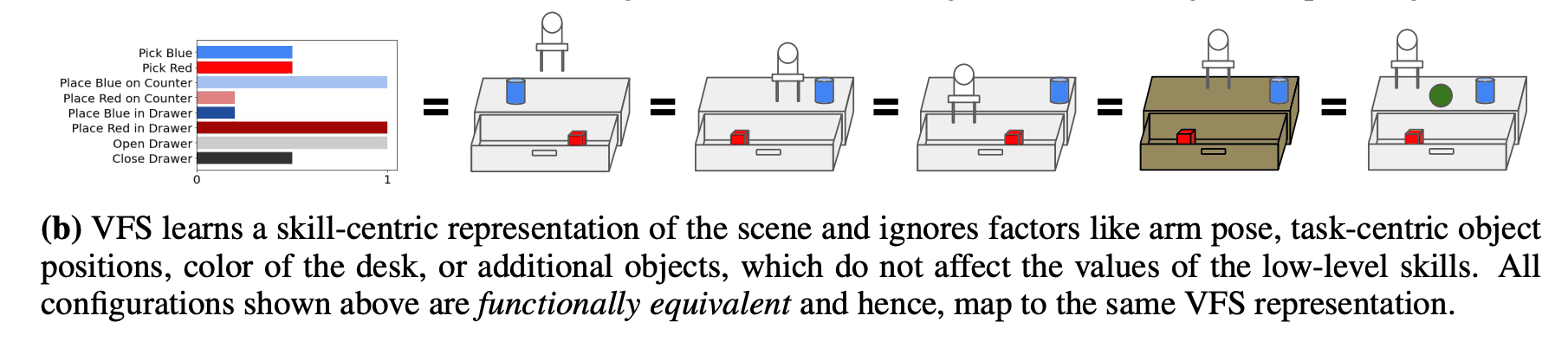
VFS的特点还在于其以技能为中心的表征,这使得它在假设的环境中对背景干扰物和任务无关的信息具有鲁棒性。因此,VFS被认为是能够适应未知环境的,本文也对其有效性进行了评估。下图显示了一个办公桌重排任务的例子,它在图像信息方面也是不同的,但从VFS的角度来看,它代表了类似的情况,这些情况可以被认为是 "功能上的等同"。这意味着,无论红色立方体在抽屉里的什么位置,蓝色立方体在桌子上的什么位置,从技能角度来看,它们都处于相同的状态。
在这项研究中,VFS在无模式和基于模型的RL中都得到了评估。下面几章分别展示了VFS如何在无模型和基于模型的RL中使用,并介绍了实验的结果。
无模型的RL+VFS
无模型的RL使用分层RL进行评估,其中VFS被用作高层策略的观察,而各自的预训练技能被用作低层策略t。实验比较了长线任务的表现。
通过使用DQN学习Q函数$Q(Z, o)$可以获得高级策略,通过设置$pi_{Q}(Z) = argmax_{o_{i}} Q(Z, o_{o})$可以获得高级策略。在这一训练过程中,从重放缓冲区中抽出一小批VFS $(Z_{t}, o_{t}, r_{t}, Z_{t+1})$,通过优化以下误差函数得到Q函数。
$$L=\mathbb{E} (Q(Z_{t}, o_{t}) - y_{t})^{2}$$
其中$y_{t}=r_{t}+ \gamma max_{o_{t'}}Q(Z_{t+1}, o_{t'})$。然而,本文实际上使用了一种名为DDQN的衍生算法来进一步稳定学习。
为了比较VFS与不同的表征学习方法在长线任务方面的表现,本文在MiniGrid环境中提出了两个任务:一是VFS。
- 多房间: 任务是解决一个由多达10个不同大小的房间组成的迷宫,以达到一个目标。
- KeyCorridor: 一个任务,代理人必须寻找一把钥匙来打开一扇锁着的门,以便在最多七个房间的尽头达到一个目标。
评价是在以下方面进行的。这两项任务都只对达到目标的人给予稀疏的奖励。
GoToObject、PickupObject、DropObject和UnlockDoor被作为这些任务的低级技能。
以下技术被用作基线方法。
- 原始观察
- 自动编码器(AE)
- 对比性预测编码(CPC)
- 在线变异自动编码器
- 对比性无监督表征的RL(CURL)。
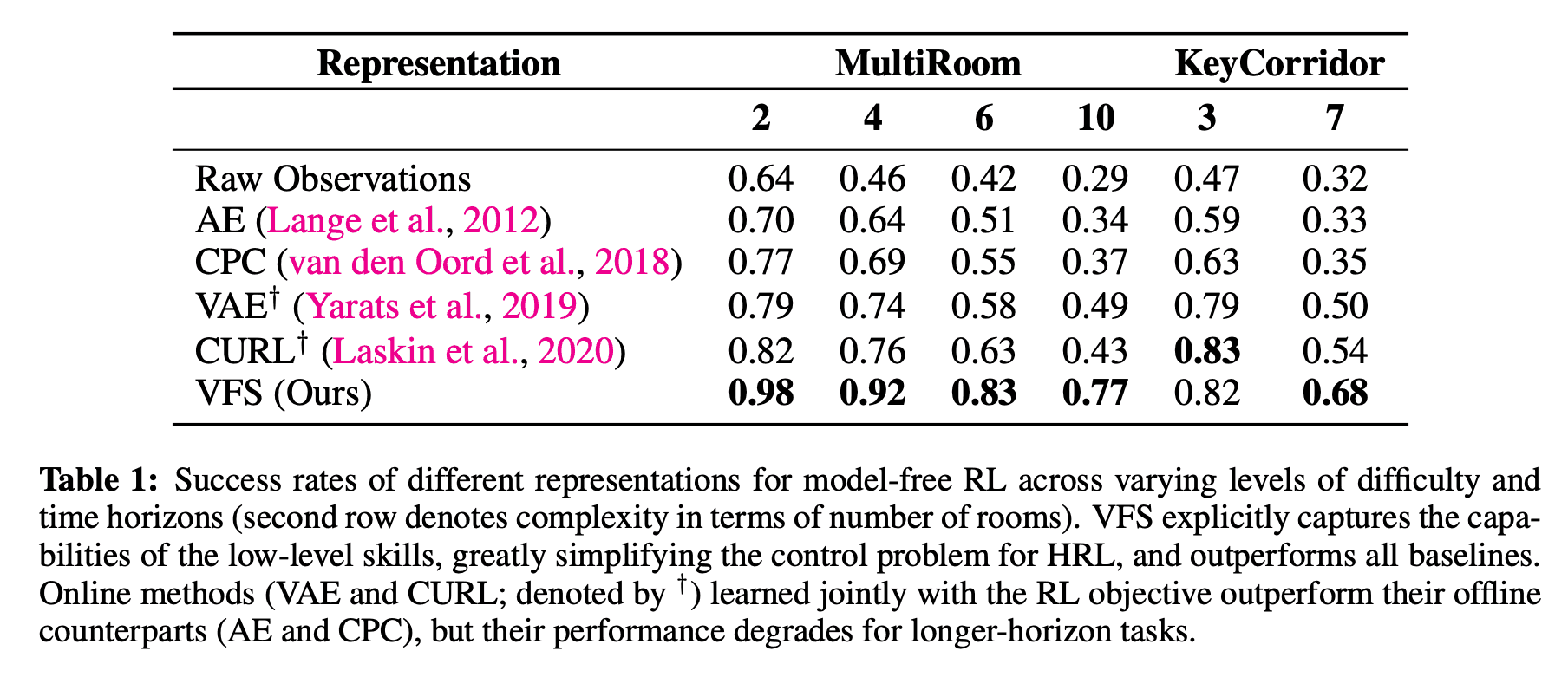
下表显示了实验的结果。首先,当从原始观测中学习高级策略时,尽管当房间数量为2个时,成功率为64^%$,但随着房间数量的增加,成功率明显下降,特别是当10个房间的成功率为显示成功率低至29^%$。AE和CPC的性能也显示出比原始观测值情况下的成功率有所提高,但仍然显示出较低的成功率,因为该表示法是独立于高层策略目标函数而训练的。在VAE和CURL的情况下,与AE和CPC相比,成功率有所提高,因为它们是与高层策略的目标函数同时训练的,但成功率较低,可能是因为学到的表征对任务的直接影响较小相比之下,VFS在大多数任务中的表现优于基线方法,这是由于它能够通过清楚地捕捉执行低级政策技能的能力,最大限度地提高表示对任务的直接影响。这被认为是因为他们有能力这样做。
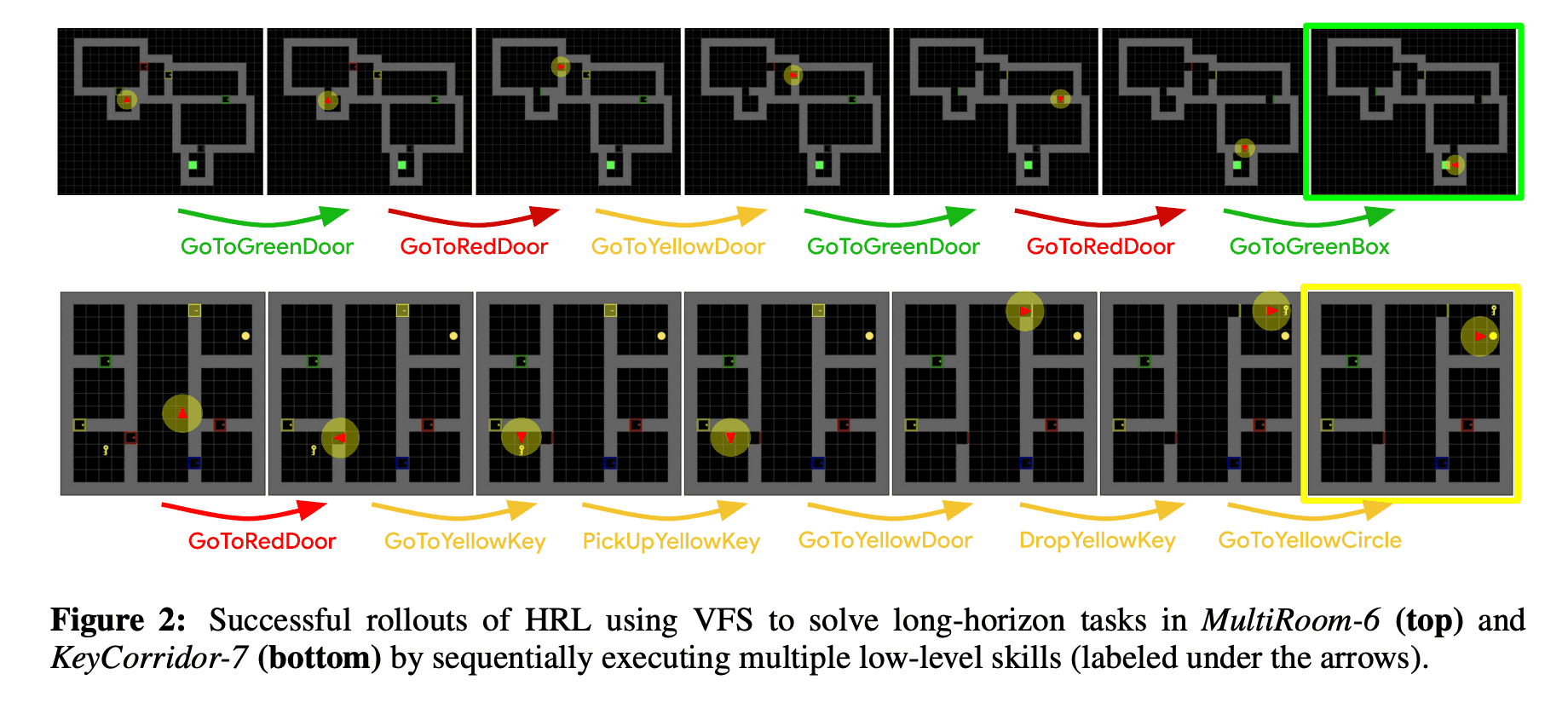
下图显示了使用VFS成功解决一项任务的轨迹。
对未知环境的概括性能。
本章的最后部分评估了VFS对未知环境的有效性。在这个实验中,在KeyCorridor中学到的策略在MultiRoom中执行,如下图左图所示,并对成功率进行了评估。结果总结在下图右侧的表格中,显示基线方法AP和CPC在MR4中的成功率为47%$,而MR10的成功率更低,约为20%$。 VAE和CURL的成功率更低,这可能是由于RL政策和这被认为是由于表示法是同时学习的,并且过度适应KeyCorridor的环境。与此相反,VFS成功地进行了零点泛化,并显示出比其他方法更高的成功率:MR4为87^%$,MR10为67^%$。这些成功率接近于在MultiRoom环境中与训练过的基线HRL-目标相比的性能。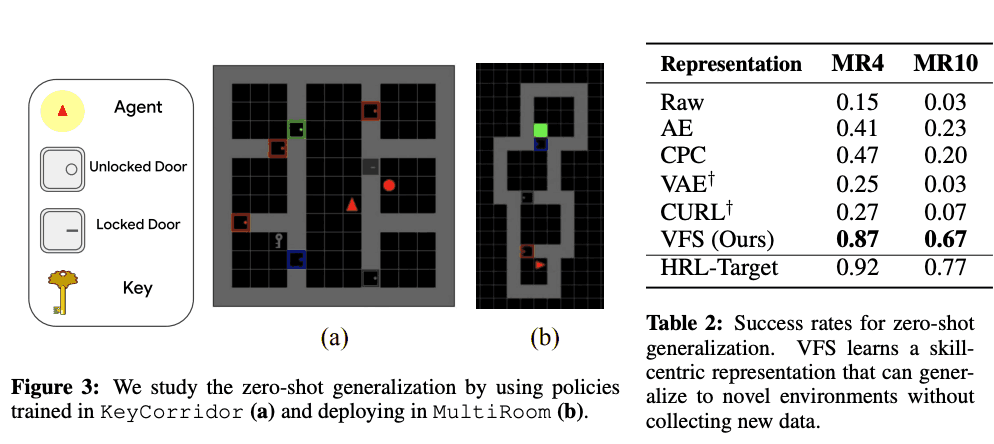
基于模型的RL+VFS
本章介绍了一个基于模型的RL的应用,它使用VFS作为规划的状态(VFS-MB)。本文中的一步预测法$Z_{t+1}= hat{f}(Z_{t}, o_{t})$是用监督学习法训练的。然后,为了解决任务,利用任务目标的表示方法$Z_{g}$和成本函数$epsilon$计算出最佳技能序列$(o_{t}, ..., o_{t}, o_{t}, o_{t}, o_{t}, o_{t})。,o_{t+H-1})$使用$Z_{g}$,任务的目标表示,以及成本函数$epsilon$,解决以下优化问题。
$$(o_{t}, ...,o_{t+H-1})= argmin_{o_{t}, ...。,o_{t+H-1}}\epsilon(hat{Z}_{t+H}, Z_{g}) : hat{Z_{t} = Z_{t}, hat{Z}_{t'+1} = hat{f}(hat{Z}_{t'}, o_{t'}) $$
然后,为了进行规划,本文采用基于抽样的方法解决了上述优化问题。具体来说,随机射击被用来随机生成k个候选期权序列$(o_{t}, o_{t+1},...)生成相应的$Z$序列,并使用学习到的$hat{f}$来预测。然后,它在k个候选者中选择最接近目标的一个,并使用模型预测控制执行该政策。在这种情况下,只有生成序列的第一个技能$O_{T}$被执行。下图是这些的概览图。
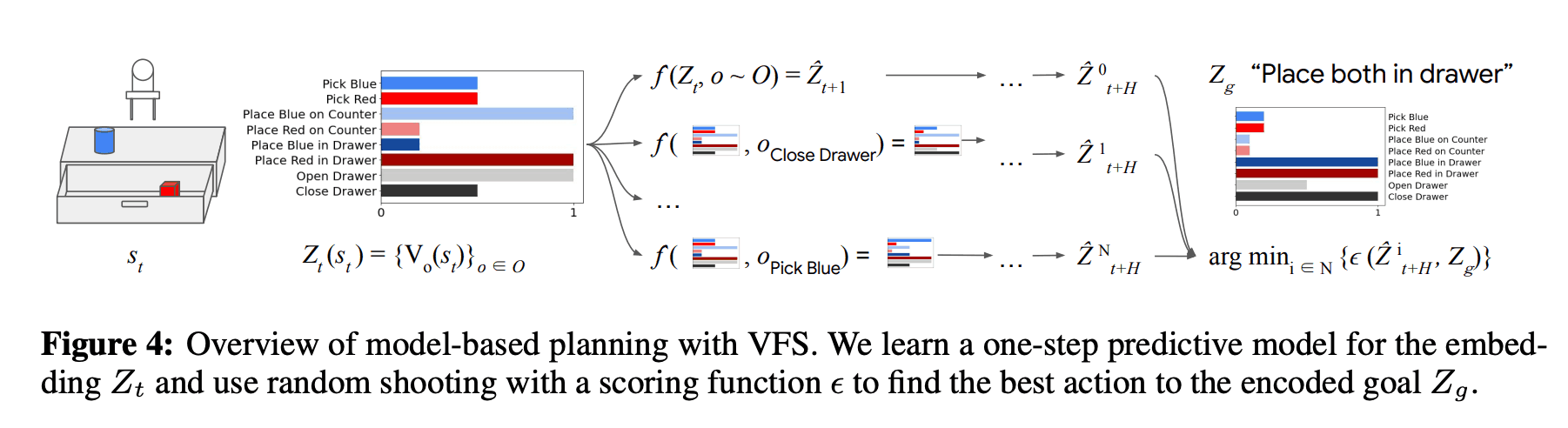
评价
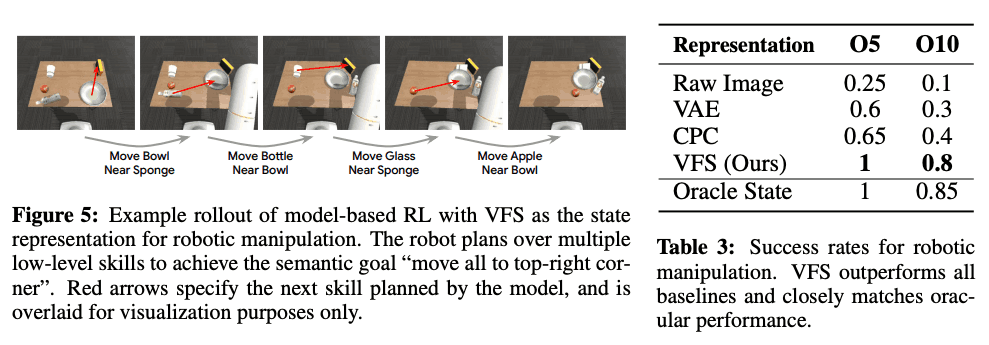
在本文中,我们对8DoF机器人在物体重排任务中的评估如下:与无模型RL实验一样,我们假设低级策略已经事先学习,在这个实验中,我们使用 "MoveANearB "任务。提供了一种技能,即把物体A移到物体B附近的技能。在这个实验中,有10个物体和9个物体目的地,所以总共使用了90个技能。此外,只给出下图所示的图像信息,作为政策的观察。
使用VAE和CPC作为基线方法,每种方法被评估了20次,成功率总结在下图的右侧。如下表所示,VFS比其他方法有更高的成功率,这表明它能够提供一个有效的表示,包括场景的信息和技能负担。研究还发现,当使用低维状态作为输入而不是接收图像信息作为输入时,它的成功率与神谕基线相似。
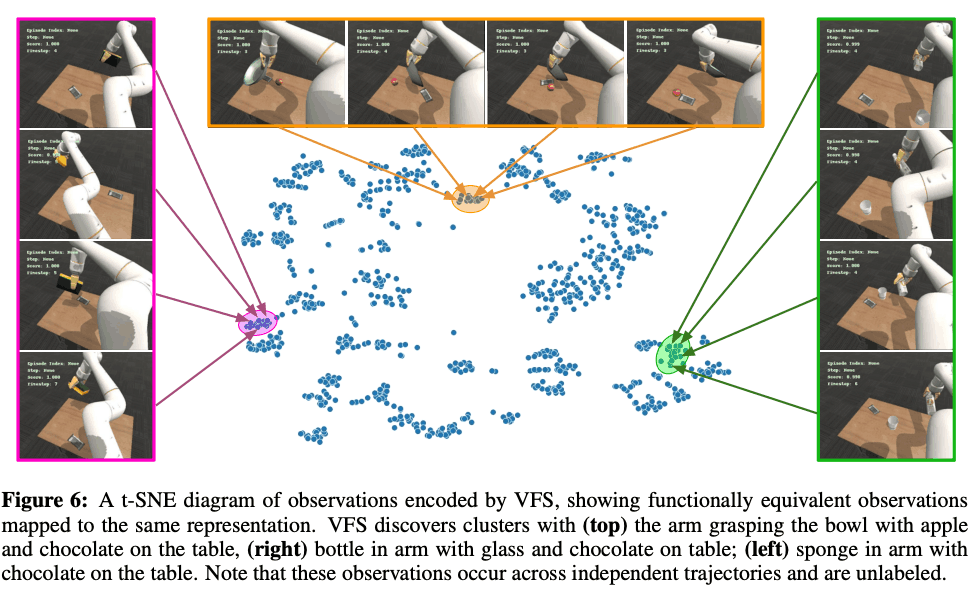
最后,为了找出VFS所捕获的元素,我们用t-SNE将其可视化,如下图所示。下图中不同颜色的范围代表机器人手臂抓取的不同物体,巧克力在桌子上。这些表明VFS正在成功地抓取关于该对象的信息。
摘要
本文介绍了一种非常简单的方法,通过使用低级技能的价值函数作为代表,可以提高长线任务的成功率和对未知环境的概括性能。一个可能的未来方向是将无监督的技能发现作为使用VFS概念的无监督表征学习方法。"长线任务是由于它是日常生活中常见的任务,由于其重要性,预计未来会有越来越多的关于长线任务的论文发表。



与本文相关的类别






