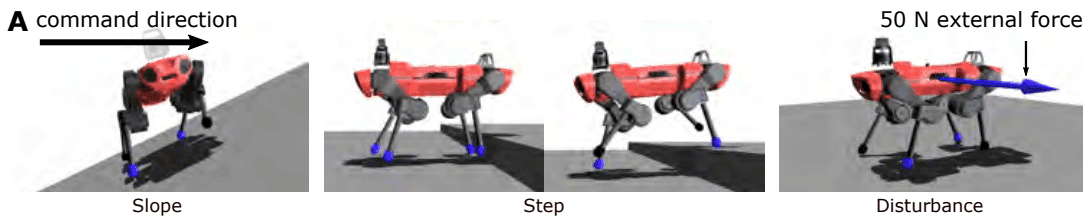
一个四足机器人控制器,可以成功地在不同的环境中行走!
三个要点
✔️ 在包括雪原和森林在内的各种环境中稳定行走
✔️ 有教师和学生策略的两阶段策略学习
✔️ 课程学习,自动调整地形的难度
Learning Quadrupedal Locomotion over Challenging Terrain
written by Joonho Lee, Jemin Hwangbo, Lorenz Wellhausen, Vladlen Koltun, Marco Hutter
(Submitted on 21 Oct 2020)
Comments: Published on arxiv.
Subjects: Robotics (cs.RO); Machine Learning (cs.LG); Systems and Control (eess.SY)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
很明显,四足机器人在各种环境(包括未知环境)下的行走动作的获取将导致机器人应用领域的扩大。然而,迄今为止提出的行走控制控制器存在着需要人为调整和易受未知环境影响等问题,它们还没有达到可以实际应用的水平。此外,基于RL的控制器只能应用于相对简单的环境,如实验室或平坦的地形。
本文提出了一种控制器,它可以在不同的环境中实现稳定的行走,如雪地、森林、楼梯和溪流,而不需要单独调谐。
研究发现,所提出的控制器具有足够的鲁棒性,可以在完全没有学习过的脆性或湿滑的地形上行走,而且与以前的方法相比,它显示出非常好的稳定性。现在,和原来的论文一样,我们将依次看一下性能和方法。

业绩
我们将看一下几个不同的环境。为了进行比较,我们根据环境的不同,采用了当时最先进的基线方法。
自然环境

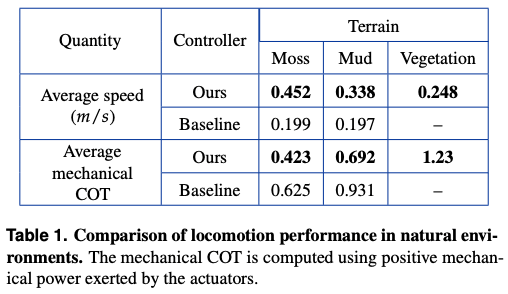
我们在潮湿的苔藓、泥土和杂草这三种不同的环境中对所提出的方法与传统方法进行了比较,重点是平均速度和运动效率。结果表明,所提出的方法在所有六个组合中都优于传统方法。此外,应该指出的是,拟议的方法能够甩掉杂草并自行行走,而传统方法由于其腿被杂草缠住而无法做到这一点。
此外,虽然没有直接考虑到数据,但提议的方法在测量过程中没有一次跌倒,而传统方法则有很多次,所以我们可以认为提议的方法甚至比实际值更好。
DARPA地下挑战赛

DARPA地下挑战赛城市巡回赛是一项旨在开发能够在地下环境(如隧道)中执行任务的机器人技术的比赛。
带有拟议中的控制器的ANYmal-B成功地完成了四项挑战,包括从一个陡峭的楼梯上下降,并继续运行了60分钟,没有一次跌倒。
室内
最后,我们想看一下室内的一个实验。
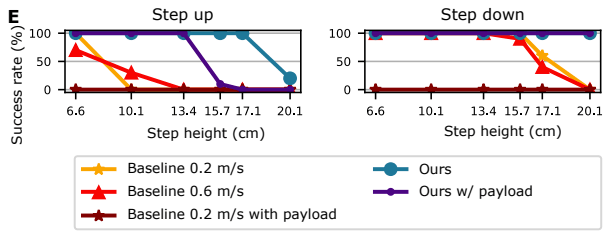
在最初的论文中,在一些设置和标准下进行了比较,但我们想强调与台阶的上升和下降有关的部分。
下图显示了所提方法的成功率与步骤的宽度。从这个数字可以看出,即使强加了一个重量(10公斤),所提出的方法也能应付大范围的步骤,而传统的方法即使没有强加重量,成功的范围也很窄,强加了一个重量,成功率就更低。
这个结果显示了所提方法的稳定性是多么好。
方法
现在我们已经看到了所提方法的巨大性能,让我们仔细看看控制器是如何创建的。
主要有三点需要考虑。我们将详细解释每一项。
- 两阶段策略学习,教师策略使用特权信息,学生策略只使用独特的接受性信息
- 自动调整地形难度的课程学习
- 由运动的产生和跟踪组成的两阶段控制结构
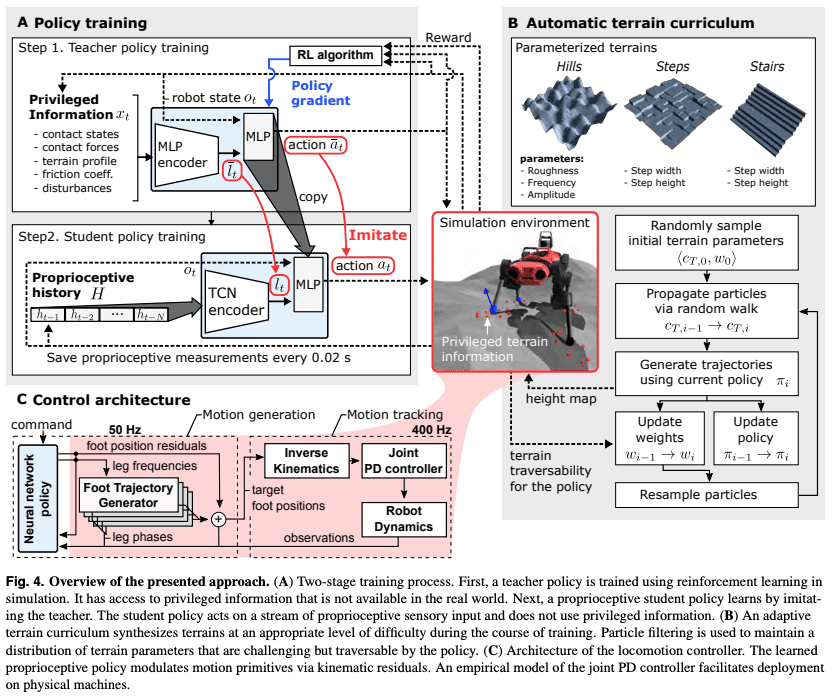
教师使用特权信息的策略和固有的接受策略学习的两个层次:教师使用特权信息的策略和学生只使用信息的策略
我想从一些术语开始说起。
特权信息是对行走有用但在现实世界中难以获得的信息,如施加在每条腿上的力或摩擦系数。这些数值在模拟器中可供参考。
其次,本体感觉信息是一组可以获得的关于自我的高度精确的数值,如每个关节的位置和速度。
这种方法的要点是,通过提供丰富的信息,训练教师在没有特权信息的真实环境中行走,然后训练学生只用内在的接受信息来行走。
让我们仔细看一下具体的过程。
第一步是培训监督战略。使用通常的RL框架,假设一旦纳入特权信息,环境是完全可观察的。
使用特权信息xt和机器人的状态ot作为输入,用TRPO训练机器人输出适当的行动at。奖励是根据机器人接近目标的速度而给予的。
在这一节中,你不仅要学习行动,还要学习lt,即特权信息的潜在表示法。本章开头介绍的图A(左上角)应有助于你理解这一点,必要时你可以参考它。
然后我们继续学习学生的措施。学生的衡量标准是使用一连串的内在接受信息,ht,定义为机器人状态ot的一个子集,其中H={ht-1,...,ht-N-1}。,ht-N-1}作为网络的输入。其中N是一个超参数,表示要考虑多远的时间。
采用TCN作为网络结构,损失函数定义如下
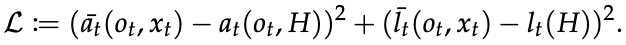
其中条形(̄)表示该值是教师测量的输出值。
从这个等式可以看出,学生措施学习模仿教师措施给出的行动和特权信息的潜在表征。
网络结构是时间卷积网络(TCN),它可以在CNN的框架内处理时间序列数据。RNN和GRU是时间序列数据最常见的网络结构,但我们选择TCN的原因是TCN比GRU有更好的学习效率,而且它可以透明地控制长数据。
自动调整地形难度的课程学习
代理人主要在三种地形(山丘、台阶和楼梯)上学习,但为了使学习过程更加有效,地形的难度可以自动调整。在本节中,我们将看到这是如何做到的。
地形的难度由矢量Ct表示。不谈细节,地形是用这个Ct作为输入生成的。例如,Ct包含关于台阶高度的信息,在上图中,你可以看到不同参数下的地形变化。
这种方法的要点是通过使用粒子过滤器来接近Ct的理想分布。
为了思考理想的Ct,我们定义了一些变量。
最初,我们引入以下数值作为衡量代理人在某些措施和地形下的可穿越性。
这里v是一个变量,表示代理人是否在行走,如果速度高于某个值,则设置为1,否则为0。ξ代表由措施产生的轨迹。
接下来,我们将在某些措施下表达Ct的良好性,如下所示。
从公式中可以看出,我们将Ct的良好性定义为行走能力在0.5和0.9之间的概率。
现在我们对目前的地形参数有了一个量化的概念,我们将研究一种算法来对Ct进行取样,这将使我们得到一个大的Td。
为了做到这一点,我们使用了一种叫做SIR粒子过滤器的技术。
本文没有解释粒子过滤器的细节,但它是一种通过粒子密度来近似概率分布的方法。这种方法也用于机器人自我定位,网络上有很多相关信息,所以也请参考。
让我们简单看一下流程。首先,我们准备N个粒子对Ct和相应的权重w。Nparticle是一个超参数,代表近似中使用的粒子数,在本文中为10。
- 然后使用Ct和训练中的措施生成轨迹,并计算Td。
- 权重被更新以对应于获得的Td的比率。
- 对Ct重新取样,并根据系统模型进行转换。
- 回到1。
该算法被称为
这个程序允许根据代理人的能力,生成适当难度的地形。
由运动的产生和跟踪组成的两阶段控制结构
控制架构可分为两个主要部分。控制结构可以分为两个主要部分:运动发生器和运动跟踪器。
行动生成部分根据RL代理提议的行动,输出目标脚趾位置。
我们来看看具体的计算过程。建议的行动在是一个16维的向量,对应于一条腿的部分有4维。它包括一个频率fi(1维)和每个维度的校正值Δrfi,T(3维)。其中i∈{1,2,3,4},对应于每个腿。使用这些值,可以构建目标脚趾位置,如下所示
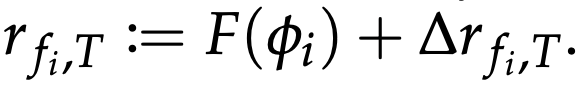
请注意,F是一个函数,它给出了取决于相位的脚步轨迹,是一个从[0, 2π]到R3的映射。Φi取决于频率fi和时间t,是一个代表每个脚的相位的变量。
这使我们有了目标的脚趾位置。在下一节中,我们将简要地看一下我们如何能够实现这一目标。
在运动跟踪部分,关于运动发生器输出的脚趾位置的逆运动学问题被分析解决,以计算出给出脚趾位置的关节角度。之后,在每个关节上使用PD控制器来实现目标关节角度。
未来的研究方向
作者指出了拟议方法的两个未来发展。
首先,人们假设,尽管他们只能获得与小跑步态(马的小跑式步态)相似的步态模式,但通过设计新的训练方法,他们也许能够获得自然界中的各种步态。
接下来,我们讨论使用外部感知。所提出的方法在不使用外部传感器(如LiDAR或深度传感器)的情况下实现了稳定行走。然而,通过有效地纳入这些传感器,所提出的方法可以获得更多的现实世界的行为,如看到障碍物并绕过它们。
摘要
我们已经研究了控制器的性能和用于实现在未知环境中稳定行走的方法。
正如最后简单提到的那样,外部传感器的使用有望带来越来越多的优秀四足机器人。这是一个我们非常期待未来发展的领域。



与本文相关的类别






