RRL:利用ImageNet提高强化学习的样本效率
三个要点
✔️ 通过使用在ImageNet上预训练的ResNet来提高Visual RL的采样效率
✔️ 与其他方法相比,复杂任务的性能更高
✔️ Visual RL应该在更多的真实世界任务上进行基准测试。
RRL: Resnet as representation for Reinforcement Learning
written by Rutav Shah, Vikash Kumar
(Submitted on 7 Jul 2021 (v1), last revised 9 Jul 2021 (this version, v2))
Comments: Accepted by ICML 2021.
Subjects: Robotics (cs.RO)
code:
简介
在这篇文章中,我们介绍了被ICML2021接受的论文RRL:Resnet作为强化学习的代表。近年来,强化学习(RL)在机器人上的应用受到了广泛关注,但由于样本的低效率,使用图像作为输入学习RL代理变得非常困难。然而,在考虑现实世界的应用时,很难从机器人关节的角度获得物体的坐标等信息,也很难从附属于机器人的摄像机中获得图像信息作为输入。那么,我们如何才能从图像或机器人自身的关节角度等输入中有效地解决任务?
人们提出了各种方法来解决这个问题,如监督学习或无监督学习来获得编码器并将其用于强化学习。然而,基本的问题是,为了获得表征,有必要收集特定任务的数据。与此相反。在本文中,我们展示了一种非常简单的方法,即使用ImageNet中的图像数据与ResNet中预训练的编码器,可以有效提高采样效率。
方法
一个好的表达方式首先是什么样子的?有四种主要的思考方式
1.低维的、紧凑的表述
2.包含各种信息的功能,以便具有高度的通用性
3.不容易受到噪音、光线、视点和其他与任务无关的信息的影响
4. 涵盖RL政策所要求的全部分布的有效代表。
为了获得这样的表征,通常需要特定领域的数据,但在本文中,我们已经探讨了如何我们探讨了如何在不使用特定领域数据的情况下获得上述表述。
因此,本文提出了一个非常简单的方法,如下图所示。在这种方法中,我们不在特定领域的数据上训练编码器,而是使用ImageNet,即具有足够广泛分布的真实世界的图像数据,来预先训练编码器,固定编码器的权重,然后使用强化学习来学习措施。现在我们将更详细地解释这种方法。

RRL:Resnet作为RL的代表
在强化学习中,最理想的情况是代理人接收一个低维状态(例如一个物体的坐标),执行一个动作,然后接收下一个状态和奖励。这样做效果很好,特别是在模拟环境中,因为很容易得到低维的状态。然而,在现实世界中,物体的坐标是不可用的,相反,机器人必须从摄像机的图像中学习,如果是机器人,则从其自身关节的角度学习。在这种情况下,从高维图像中有效地学习和使用低维特征非常重要。因此,为了满足上述良好特征表示的标准,本文通过实验表明,ResNet可以用ImageNet进行预训练,其编码器可以用来处理广泛分布的数据。该方法如上图所示,预先训练好的编码器接收输入图像并输出特征,如果机器人有自己的关节角度等信息,它就将关节信息与图像的特征结合起来,作为输入传递给代理。这里,预先学习的编码器的权重是固定的。
实验
在本文中,我们实验了一种叫做DAPG的强化学习算法,众所周知,当输入是低维状态时,该算法可以有效地学习,但当输入是高维数据如图像时,却不能很好地学习。因此,在本研究中,我们通过实验证明了DAPG算法是否能够有效地利用从图像中获得的低维特征表示来学习代理。在这个实验中,我们确认了以下五点
- RRL是否可以通过大规模图像数据预训练的特征从图像中学习复杂的任务?
- RRL的性能与其他最先进的方法相比是否良好?
- 性能是否受预训练模型(ResNet)的选择影响?
- RRL模型的大小是否对性能有明显影响?
- 常用的以图像为输入的连续控制任务是一个有效的基准吗?
在我们的实验中,我们在如下所示的操纵任务中测试了Adroit操纵套件。这些任务很难从状态中学习,而且图像很复杂,所以需要有效的特征表示来成功学习。

结果
下图显示了RRL与其他基线,如FERM、DAPG和NPG(自然政策梯度)的比较。从下图可以看出,NPG即使只用状态也经常学习失败,说明任务本身是比较困难的,而DAPG在只用状态而不用图像进行训练时,成功地解决了任务,这可以看作是一个神谕基线。这可以被看作是一个神谕基线。RRL虽然是在图像上训练的,但它能很好地解决所有的任务,对于某些任务,其结果几乎与有状态输入的DAPG相同。最后,尽管有些任务被成功解决,但结果的巨大差异表明学习是非常不稳定的。FERM与RRL的不同之处在于,它使用来自任务的数据而不是ImageNet的数据来学习编码器,因此它学习的是特定任务的特征。

视觉干扰的影响
下面中间和右边的图表显示了改变灯光或物体(视觉干扰物)的颜色对RRL和FERM表现的影响。从下面的结果可以看出,RRL对视觉干扰物的敏感性比FERM低。这是因为RRL的编码器是从广泛分布的大规模图像数据中训练出来的,所以编码器本身对视觉干扰物相对不敏感,因此学到的策略对视觉干扰物也不太敏感。另一方面,FERM使用在特定任务数据(固定的光线条件和物体颜色)上训练的编码器,因此对视觉干扰物更加敏感,导致性能明显下降。

特征表示的影响
问题是,选择ResNet模型是否首先只能偶然学习有效的特征。为了解决这个问题,我们比较了使用ResNet的RRL与使用ShuffleNet、分层VAE(VDVAE)和MobileNet的RRL的性能。VAE的性能稍低,但基本上与其他模型相同。

下图显示了使用VAE的编码器(VAE)在特定任务数据上训练的RRL和基于Resnet在广泛分布的数据上训练的RRL之间的比较。从下图来看,使用Resnet的性能更高。也可以说,在分布广泛的大数据上训练的编码器比在特定任务数据上训练的非常脆的编码器更有效。

不同投入对绩效的影响
我们调查了RRL的性能如何因输入和噪声的类型而变化。在下图中,我们比较了没有来自传感器的机器人关节信息的RRL(视觉)、在关节信息中加入噪音的RRL(噪音)以及同时拥有图像和关节数据的RRL(视觉+传感器)。从下图中可以看出,性能略有下降,但结果表明,RRL对噪声具有很强的适应性,仅在图像上就表现得相当好。

RRL措施的规模和奖励功能对绩效的影响
那么,如果奖励函数是稀疏的或密集的,是否会影响结果?下面的左图显示了奖励函数是稀疏的时候和密集的时候的结果。这显示了使用RRL的优势,因为它可以使用稀疏的奖励函数来解决,而不是定义密集奖励所需的特定领域知识。下面右边显示了不同规模的策略网络的比较,也显示了良好和稳定的结果,没有任何明显的性能差异。

目前主流使用的Visual RL基准的有用性
DMControl环境经常被用作有图像输入的RL的基准(RAD、SAC+AE、CURL、DrQ等)。然而,事实证明,这些方法在DMControld上运行良好,但在Adroit Manipulation基准上表现不佳。例如,使用专家论证和RAD训练的基线FERM是不稳定的,或表现不佳。
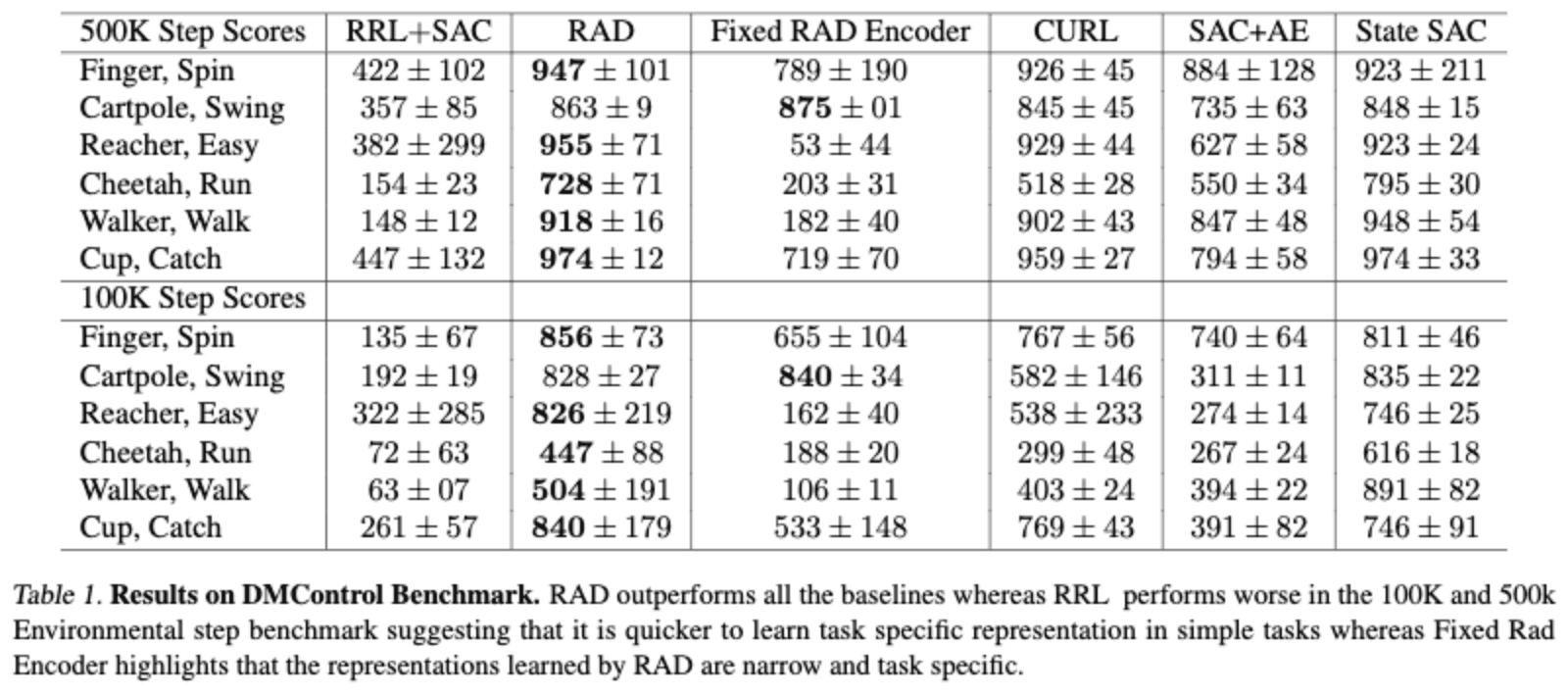
下表显示了在DMControl任务上的表现,在图像信息不太复杂的DMControl任务上,RAD等方法比所提出的RRL表现更好。RRL的低性能可以归因于ImageNet的真实世界图像数据和DMControl图像信息领域之间的巨大差距,我们呼吁建立更接近真实世界图像的基准任务。
如果我们看一下固定RAD编码器,它是使用Cartpole数据在RAD上训练的编码器,而固定RAD编码器是在提供类似图像信息的任务中在RL代理上训练的,我们可以看到这个编码器的性能明显低于RAD。我们可以看到,编码器正在学习特定任务的特征,这显示了编码器的低通用性。当输入的是简单的图像时,这种特定任务的特征表征很容易学习,而当图像变得更加复杂时,它们就变得更加困难。
摘要
在强化学习中,使用图像作为输入时,样本的效率低下是一个重要的问题,我们介绍了一篇论文,表明一个非常简单的方法,使用在ImageNet上预先训练的ResNet特征,可以提高样本效率。然而,如果ImageNet和领域之间有很大的差距,它就没有效果,我们很想知道它的效果如何,特别是在现实世界中的机器人实验。我们还认为,一个涵盖广泛分布的大型数据集,如ImageNet for Robotics,将成为有趣的研究。



与本文相关的类别






