什么是自我调节,它解决了语义分割的主要失败?
三个要点
✔️ 解决语义分割中的主要失败问题
✔️ 提出可应用于各种骨干网的自律性损失
✔️ 提高现有方法在弱监督/监督性分割任务上的性能
Self-Regulation for Semantic Segmentation
written by Zhang Dong, Zhang Hanwang, Tang Jinhui, Hua Xiansheng, Sun Qianru
(Submitted on 22 Aug 2021)
Comments: ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
语义分割的研究,即预测图像中每个像素所对应的类别标签,由于深度CNN等进展,已经取得了重大进展。例如,EfficientFCN在PASCAL Context(一项复杂的自然图像分割任务)上取得了约85%的mIOU。
在本文介绍的论文中,我们提出了一种名为自我调节的损失,以解决现有语义分割模型的这一主要故障。
语义分割中的主要失误
原文列举了语义分割失败的两个主要例子。
失败案例1:漏掉一个小物体或物体的一个小部分
例如,下图说明了第一个故障。

该图显示了DeepLab-v2的预测结果。正如你所看到的,DeepLab-v2成功地预测了马的身体,但未能预测到马的腿。
例2:预测一个较大物体的一部分的不同类别标签
第二种失败的情况如下。

这张图错误地将占图像一半左右的一些牛预测为马。
原文中提出的损失函数Self-Regulation,旨在解决这两个主要的失败。
应对失败 1
下图可视化了DeepLab-v2在预测马匹图像的语义分割时的浅层和深层特征。
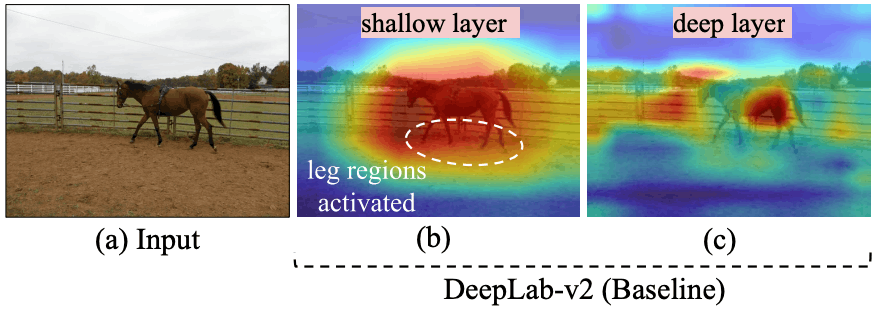
图中显示,在浅层,马的(未成功预测的)腿部也被很好地激活,而在深层,它们受到背景的影响,腿部信息被忽略了。
所提出的方法通过引入蒸馏损失,有效地将信息从浅层转移到深层,浅层的特征图是老师,深层的特征图是学生。
应对失败 2
在前面提到的失败例子2中,一头牛的一部分被错误地预测为马。为了处理这种情况,提议的方法使用了图像级别的分类损失。
例如,如果整个图像的类预测是 "牛",那么在图像中出现一个 "马 "的类,在直觉上是不自然的。
在提出的方法中,为了应对故障情况2,除了使用现有的方法--多出口结构损失(MEA损失)外,我们还引入了蒸馏损失,其中深层分类logit是教师,浅层分类logit是学生。
这些措施在下图中有所说明。
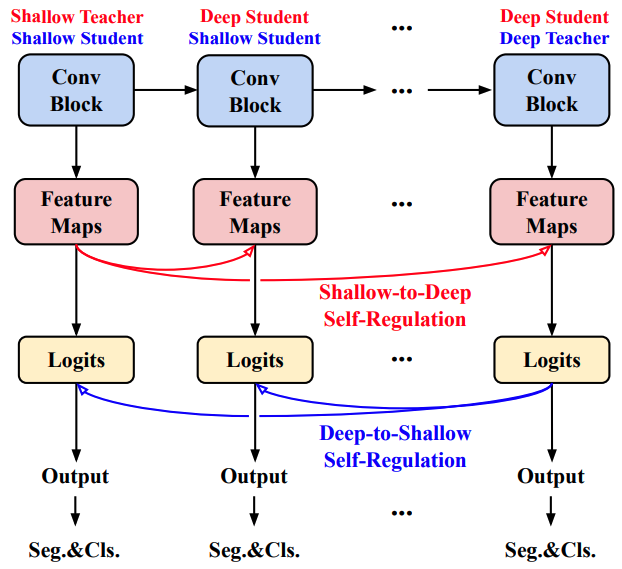
如图所示,浅层在每层的特征图中调整深层(通过蒸馏损失),而深层在分类Logit中调整浅层,从而解决上述问题。
[建议的方法(自律)。
自我调节是为了结合三种类型的损失。让我们依次看一下它们。
损失1:使用特征图的自我调节损失(SR-F
SR-F是一个旨在解决上述失败案例1的损失,旨在鼓励浅层的特征图信息保留在深层。这与上图中的 "沙洛--深层自律 "相对应。
具体来说,对于最浅层(Shallow Teacher)的特征图$T^{[1]}_{\theta}$和第$i$层(Deep Student)的特征图$S^{[1]}_{\phi}$,可以得到SR-F损失$L_{SR-F}$如下
$L_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})=-\frac{1}{M}\sum^M_{j=1} \sigma(t_j)log(\sigma(s_j))$
$L^{\tau}_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})=-\tau^2 \frac{1}{M}\sum^M_{j=1} \sigma(t_j)^{1/\tau}log(\sigma(s_j)^{1/\tau})$
$L_{SR-F}=\sum^N_{i=2} L^{\tau}_{ce}(T^{[1]}_{\theta},S^{[1]}_{\phi})$
对于$L_{ce}$,$t_j$是对应于特征图$T^{[1]}_{\theta}$的第j$像素的向量,$s_j$是对应于特征图$S^{[1]}_{phi}$的第j$像素的向量,$sigma$是每道softmax归一化,$M$是特征图的宽度x高度。
SR-F损失利用了温度比例,这在知识蒸馏中是常用的,其中$tau$是一个温度参数。
损失2:使用分类Logit的自我调节损失(SR-L
SR-L是一种旨在解决上述故障2的损失,通过鼓励浅层捕获深层的分类逻辑信息,从而提高对背景噪声的鲁棒性。这对应于上图中从深到浅的自我调节。
具体来说,对于最深层(Deep Teacher)的分类Logit $T^{[N]}_{theta}$和浅层(Shallow Student)的特征图$\{S^{[k]}_{\phi}\}^{N-1}\}^{N-1}_{k=1}$,SR-L损失$L_{SR-F}$可以得到如下结果。
$L_{SR-L}=\sum^{N-1}_{k=1} L^{\tau}_{ce}(T^{[N]}_{theta},S^{[k]}_{\phi})$
除了这两种自律性损失外,我们还使用了MEA损失(这不是本文的主题,将不详细讨论)。总的来说,损失函数如下
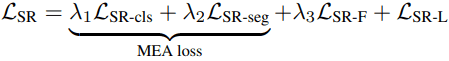
$lambda_1,\lambda_2,\lambda_3$将是表示每个损失的权重的超参数。
实验结果
在我们的实验中,我们在两个任务上评估了Self-Regulation:有监督的语义分割(FSSS)和无监督的语义分割(WSSS)。
WSSS使用两个基准,PASCAL VOC 2012(PC)和MS-COCO 2014(MC)。
FSSS使用两个基准,即Cityscapes(CS)和PASCAL Context(PAC)。
每个损失的消融研究
拟议方法中包括的三种损失(SR-F、SR-L和MEA)的消融实验结果如下
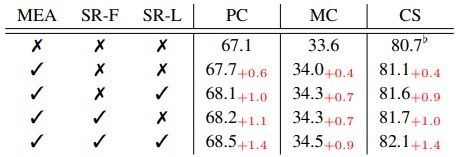
引入SR损失后,表现出持续的改善。
建议的方法对WSSS/FSSS的影响
在WSSS的基线模型中引入建议的方法的结果如下表所示。
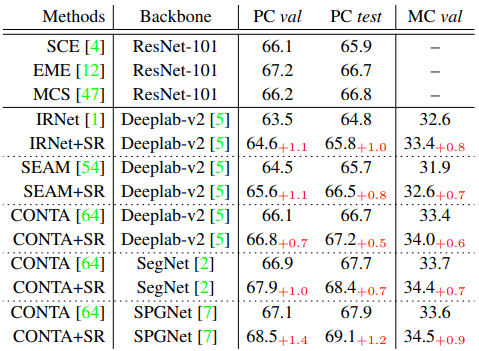
FSSS的内容如下
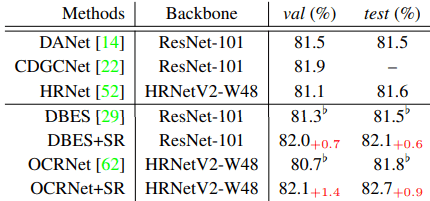
表中的数字指的是mIOU(%)。
对于WSSS/FSSS任务,在基线模型(基线名称+SR)中引入所提出的方法,持续改善了性能。
所提方法的计算成本
下面是一个例子,说明在现有的语义分割模型中引入拟议的SR方法会增加计算成本。
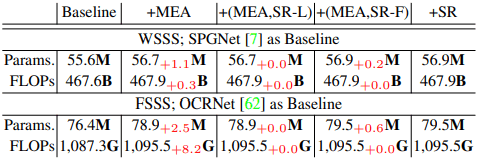
对于WSSS和FSSS,发现由于引入所提出的方法而增加的计算成本(模型参数数量和FLOPs)非常小。
摘要
在这篇文章中,我们介绍了自我调节,这是一种旨在解决语义分割中两种主要失败类型的损失。自我调节是指从浅层到深层或从深层到浅层的蒸馏损失,有效调整浅层和深层之间的特征图分类逻辑。所提出的方法被证明能够持续改善弱监督和监督的语义分割模型的性能。
该方法既通用又高效,计算成本低,能够在各种现有模型中实施。



与本文相关的类别

![[任何分割] 零镜头分割模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/segment_anything-520x300.png)



![[PiCIE] 用于无监督语义分割的像素](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2021/picie-520x300.png)