鸟瞰优化算法,把握趋势吧!
三个要点
✔️ 提出了大规模优化算法的基准之一
✔️ 优化算法取决于问题。
✔️ 使用默认值可能有用
Descending through a Crowded Valley -- Benchmarking Deep Learning Optimizers
written by Robin M. Schmidt, Frank Schneider, Philipp Hennig
(Submitted on 9 Mar 2020)
Comments: Accepted at arXiv
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
Paper Official Code COMM Code
介绍:
我们都知道,优化算法对学习模型的训练时间和准确率起着重要的作用。目前很多人都在尽力通过选择优化算法和调整其超参数来尽可能地提高学习模型的精度。但是,优化算法的选择或超参数的调整等分析结果并不明确,多是凭感觉或实践经验来完成。另外,由于优化算法对精度的影响较大,所以对优化算法的研究也在逐年增加。图1是优化算法的论文和年度趋势,可以肯定的是,优化算法的论文数量和年度趋势基本是增加的,因为从2019年到2020年,数量似乎在减少,只是因为收集期还在2020年。
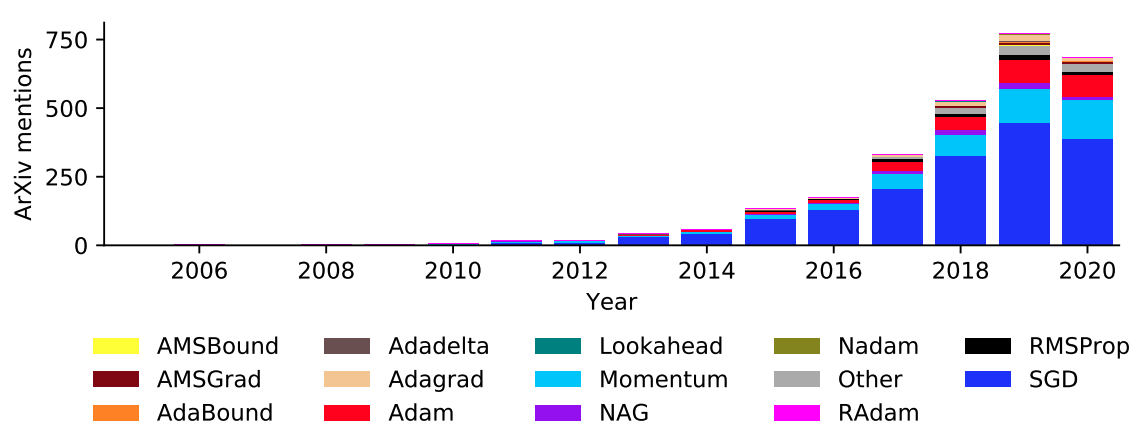
图1.优化算法的论文和年度趋势。
在大多数优化算法的拟制研究中,研究者自己的优化算法占主导地位的情况也很常见。你知道目前有多少种优化算法吗?介绍了作者优化算法的调查表1。这仍未涵盖所有内容。表2还总结了优化算法的参数表。
表1:优化算法的类型。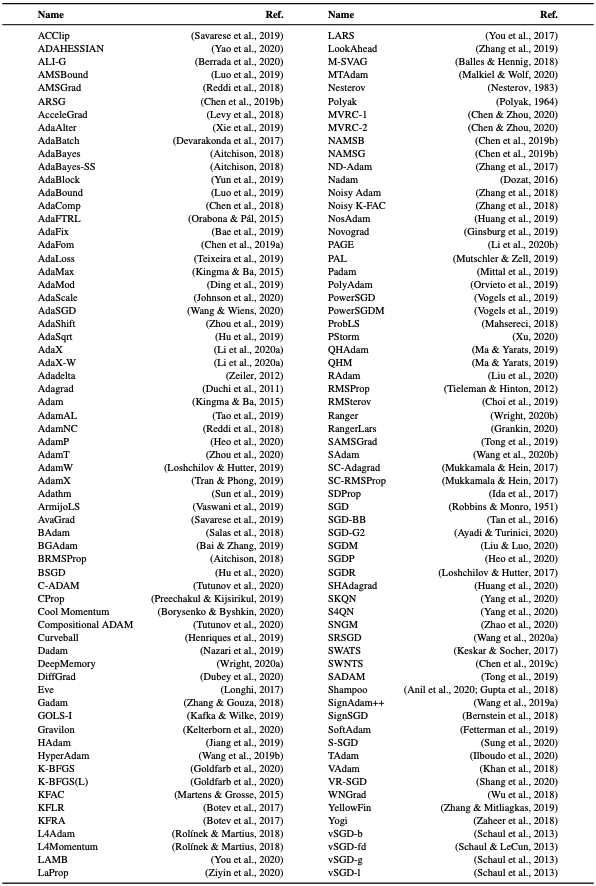
表2.优化算法进度表摘要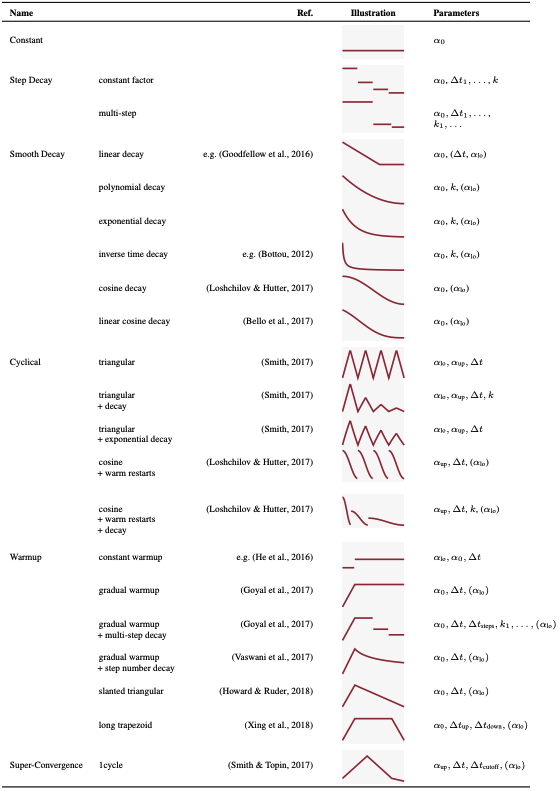
这可能会让一些人感到惊讶,但至少这就是所有的建议。棘手的是,这些比较分析很少。这也是为什么大多数人倾向于使用新元等老字号的原因。为什么我们从来不做比较分析?因为在这些比较分析中需要考虑的项目组合是巨大的。除此之外,由于反复的调整和实验,以及计算资源问题,还需要大量的时间和人力成本。
所以,本文介绍的是一项基础研究,比较优化算法选择和超参数的影响,以了解优化算法的发展趋势。(有一点要说明的是:作者的资源也不是无限的,所以最好只把它当作一个实际的研究范围。另外,这只是一个开始,还不是对整个模型的研究,所以还是很贴心的,但我觉得这只是有利于捕捉趋势,从开销的角度看整个优化算法。)
贡献
- 可以对优化算法进行广泛的总结追赶(表1和表2)。
- 提出了大规模优化算法的基准之一。
- 通过千次的分析和经验实验,优化算法取决于问题所在
- 优化算法的默认参数和调优参数往往没有明显的区别(参见AI-SCHOLAR中的文章《有经验的人擅长参数调整!》。但对于相同参数的默认值的处理有一些建议)。)
- 学习率表比"不调整"表相对更有效,但其有效性因问题不同而有很大差异。
- 从实验中没有发现通用的优化算法,相反,发现针对问题的优化算法是
实验
实验很简单。见图2。
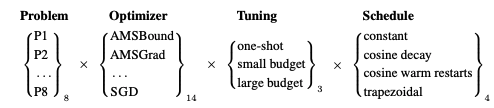
图2. 考虑因素和组合
- 评价8个(P1~P8)问题的优化算法。
- 14种最流行的优化算法
- 相反,三种调式
- 考虑四种学习率表。
他们将综合使用这些措施。在研究中使用多个评价指标,而不是一个具体的指标,但由于是假设现实世界中的AI工程师,所以在这里只指测试精度(或测试损失)方面的评价。
问题
表3对每项任务进行了总结。
表3.8 问题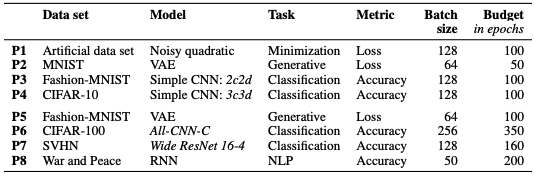
P1~P4题为小数据集,P5~P8为大数据集。模型、任务等如表所示。
优化器
在众多的优化算法中,他们选取了14种常用的优化算法,从意义上讲,这些算法是使用最多的。详见表4。特别是,调谐分布是下一次调谐环节中调整参数的搜索范围。
表4.所选的各优化算法。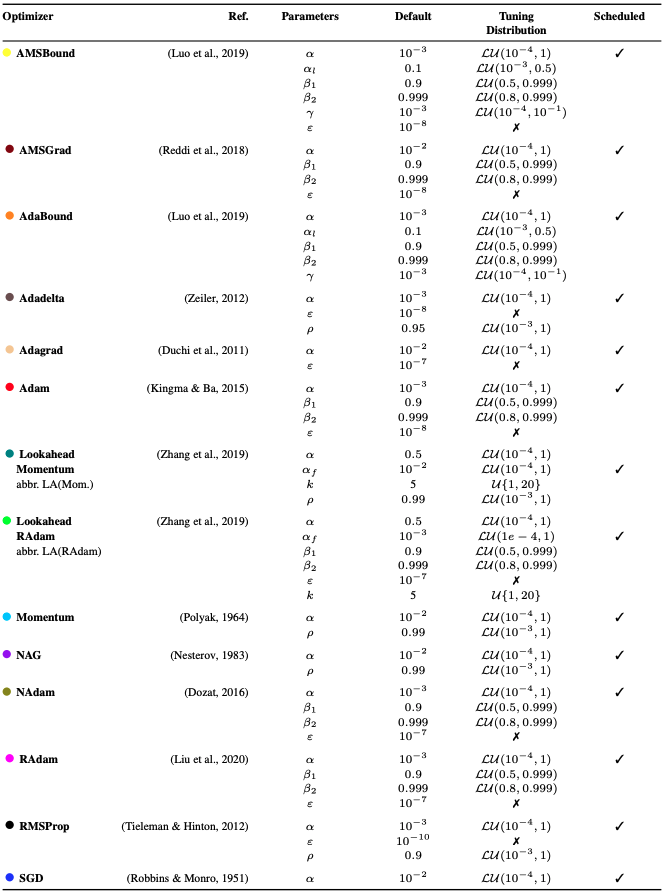
调整
有三种方法可以调理它。
- 采用命题人和研究人员的默认值。默认值请参考上一节的表4。
- 小预算调整(小预算
- 大资源调整(大预算
小预算和大预算
只用一个种子,调谐25次(小预算)和50次(大预算)。之后,由于种子对精度的影响可能会出现偶然性,我们随机设置了10个最佳调整设置的种子值,并通过平均值和标准差进行评估。采用随机搜索的方式进行调整。
计划中的
在学习速率计划方面,设置了四种不同的计划:恒定、余弦衰减、余弦与温态重启和梯形。详细情况可参见表2。
结果
这个问题的实验数量非常多,所以有很多结果。将重点介绍一些最独特的。如果你对其他的结果感兴趣,请看一下原书。我想你会被大量的结果所淹没。
下图3显示了结果。
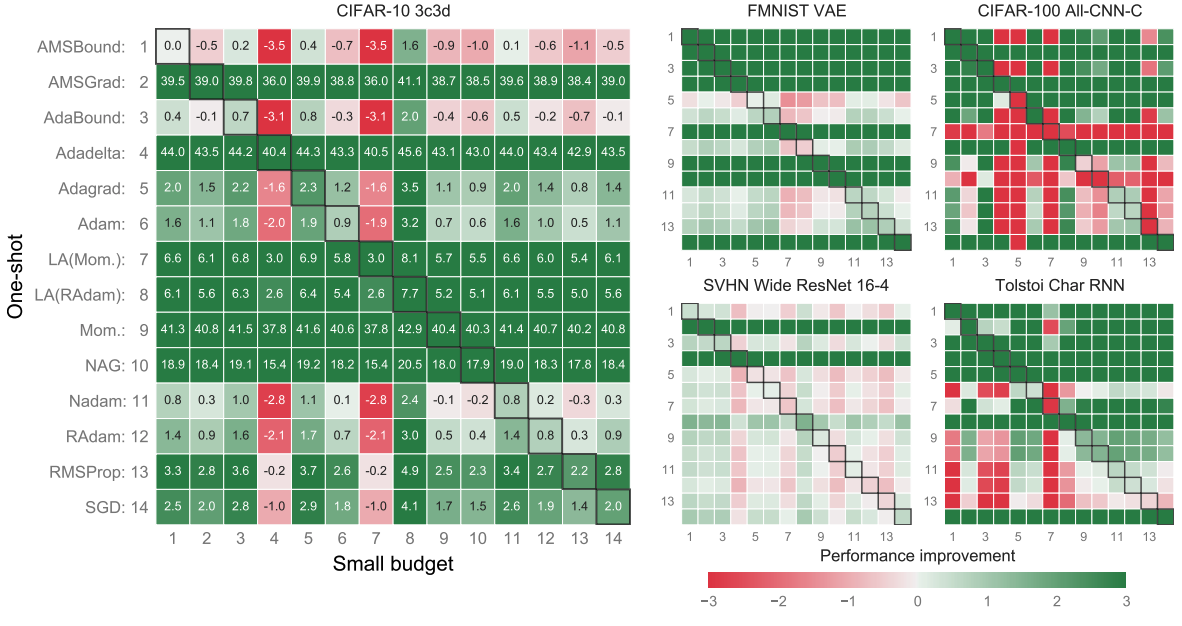 图3.结果(由于调整造成的差异)
图3.结果(由于调整造成的差异)
已改善的用绿色显示,未改善的用红色显示。例如,我们看问题:CIFAR-10,模型:3c3d(最左边)和左下角单元格,可以看到AMSBound(1)(小预算)比SGD(14)(单枪:使用默认值)精确2.5%以上。基本上,垂直看优化算法一栏)。
更直接的说,Adadelta(4)(小预算)纵向看(红色),不如大多数优化算法的默认使用。不过,似乎比一拍即合的7、8、9、10更准确。所以在水平基础上,红色意味着更好的精度,所以可以看到AMSBound(1)(One-shot:默认使用)比大多数调优算法更准确。
问题标准的结果如图4所示。
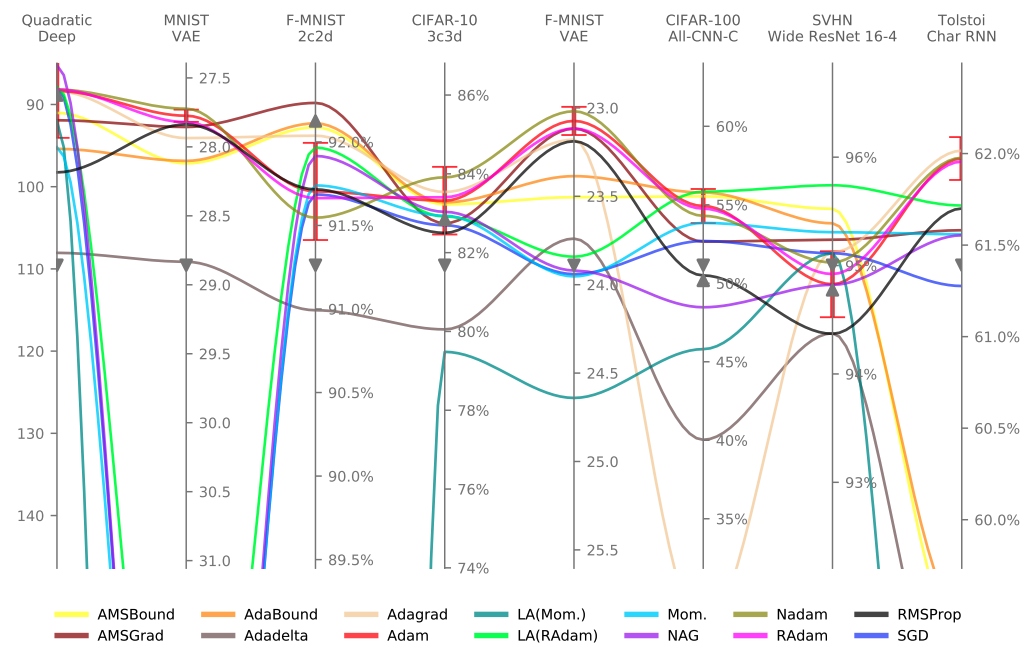
图4. 结果(按问题分列的差异)
它高度依赖于任务,因为在性能上有很大的差异。这说明,有一种优化算法。
摘要
此项审查尚未充分探讨。
- 不同复杂程度和规模的模型是否会产生相同的结果?
- 这种优化算法的趋势可能会根据模型的变化而变化。
- 通过解决DEEPOBS,其结果可能会更加通用,其中包括广泛的深度学习测试问题以及评估优化算法的标准化程序。
- 这可能会根据框架的不同而改变。
- 这种考虑有可能不能通用于像GAN或强化学习这样需要大量资源的东西。
- 参数搜索方法的不同也是需要考虑的项目。
- 重现性 稳定性
这方面还有很多工作要做。不过,这项研究的结果很有可能为这些实用的社会工程师提供一个有用的初探。另外,这项研究可能会提供一个机会,提出新的算法以及使用这些算法的新方法。
如果你要做调整,包括优化算法。
- 选择一次要考虑的优化算法←这一点很重要,因为任务和优化算法之间存在依赖性(但没有明确的选择方法)。
- 基本上是一个通用的,使用默认值
- 改变学习率计划表←小心出现问题,严重影响准确率。
从这次的讨论中只能看出这一点。但建议使用默认值或常用的相对来说。虽说不是那么简单,但比较所有的默认值,总比比拼微调更有利于重现性。



与本文相关的类别





