
稀疏变换器:解决计算复杂度随输入序列长度增加问题的创新方法。
三个要点
✔️ 通过重现注意力的逐层特征,降低了计算复杂度
✔️ 使用三种注意力:滑动窗口注意力(Sliding Window Attenion)、放大滑动窗口注意力(Dilated Sliding Window Attention)和全局注意力(Global Attention)。通过
✔️降低了 Transformern 的计算复杂度,不仅降低了计算复杂度,还实现了 SOTA。
Generating Long Sequences with Sparse Transformers
written by Rewon Child, Scott Gray, Alec Radford, Ilya Sutskever
(Submitted on 23 Apr 2019)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
稀疏变换器试图通过设计注意力的方向来解决变换器自我关注的计算复杂度为 $O(n^2)$,以及插入长句时内存使用量迅速增加的问题。
变形金刚有哪些问题?
变换器的计算复杂度随输入序列的增加而呈二次曲线增加。这导致计算时间和内存占用非常长。
这是因为 Transformer 的关键组件 Scaled Dot-Product Self-Attention。首先,Scaled Dot-Product Self-Attention 使用查询和键值对来计算注意力。换句话说,缩放点积自关注计算公式使用查询、键和值($Q, K, V$)来计算关注度。
$$Attention(Q, K, V) = softmax(\frac{QK^T}{sqrt{d_k}}V)$$.
查询用 $n$ 表示。查询和值(Q,V)的乘积是文档长度($n$)的平方。因此,在输入 2046 个标记的情况下,注意力计算的矩阵大小为 2024*2024,这意味着在注意力计算中需要处理一个包含约 410 万个元素的矩阵。这是对批处理规模的要求,也是计算密集型的,并对内存容量造成压力。
因此,稀疏变换器(本文的主题)解决了这个变换器问题,即随着输入序列的平方,计算复杂度不断增加。
使用稀疏变换器得出的结果
首先要检查的是使用稀疏变换器后内存使用量减少了多少。具体来说,如下表 1 所示,当时在图像、语言和音频等所有领域都实现了 Sota。此外,还介绍了用于测试的实际环境。
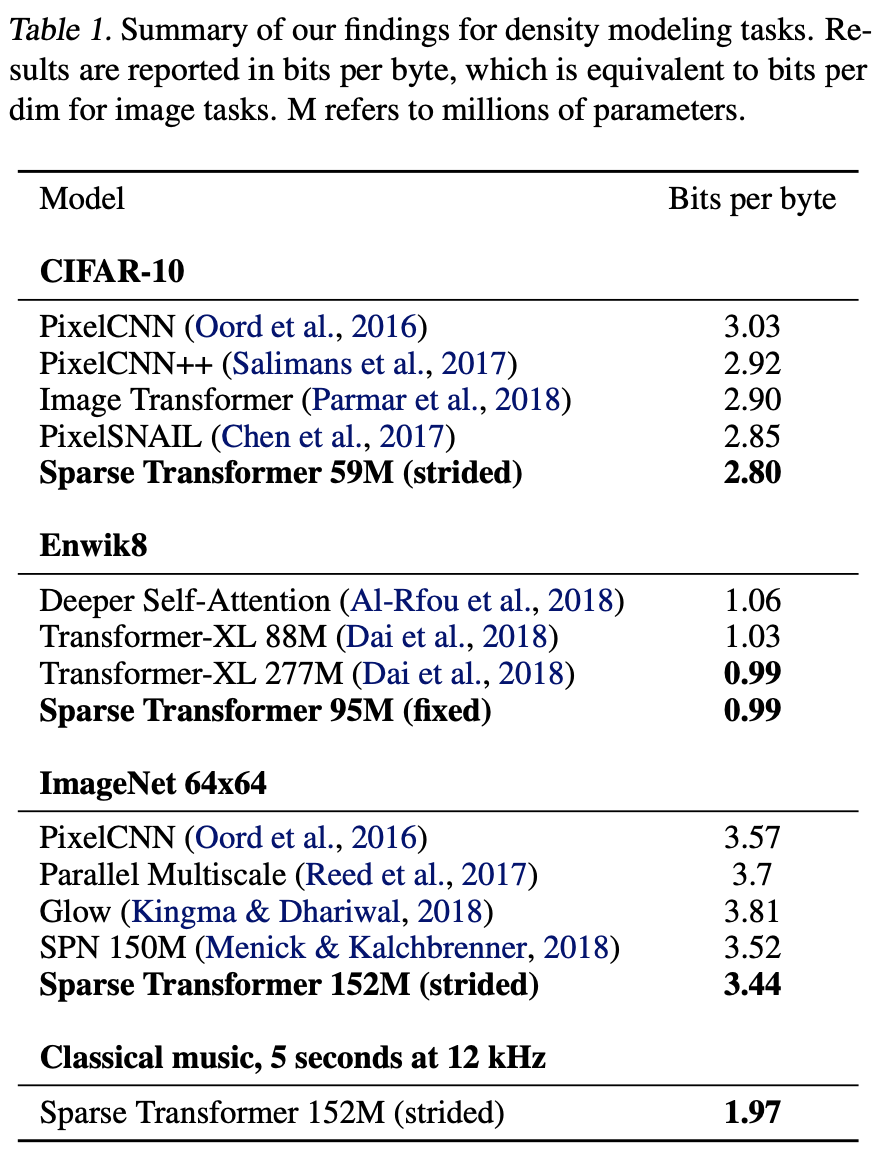
CIFAR-10
首先,CIFAR-10 本身是一幅 32 x 32 像素的彩色图像,因此单幅图像的输入序列长度为 32 x 32 x 3 = 3072 字节。这是用 Strided Sparse Transformers 训练出来的。参数等分别在一个有两个头、128 层和 $d$=256 的半规模前馈网络中进行训练。学习率为 0.00035,退出率为 0.25,直到验证误差停止下降,epochs 数量为 120 epochs。
48 000 个数据样本用于训练,2000 个样本用于验证,以评估模型的性能。结果发表时的 Sota 值为 2.80,超过了 Chen 等人的 2.85。
Enwik8
在 Enwik8 数据集上评估较长序列输入的稀疏变换器 Enwik8 数据集的句子长度为 12,228 个,属于较长序列输入。
训练使用 30 层固定稀疏变换器完成,前 9000 万个词组和最后 1000 万个词组用于验证和测试。学习参数为 8 个头、$d$=512、128 步(辍学率为 0.40)、c=32 和 80 个历元。
结果,达到了 0.99,超过了 Transformer-XL 的 la 1.03(Dai 等人,2018 年),后者是发表时的 Sota,大小也类似。
ImageNet64×64
ImageNet 和 CIFAR-10 来自同一套图像系统,但不同之处在于输入序列的长度:ImageNet 64×64 需要处理的序列长度是 CIFAR-10 的四倍。因此,这是一次测试,看看有跨度的稀疏变换器能否成功保留长期记忆。
在 ImageNet 64×64 上进行的实验使用 16 个注意力头和 48 层跨距稀疏变换器进行训练,参数为 $d$=512,总计 15.2 亿个参数。参数似乎已经过验证,跨度为 128,辍学率为 0.01,历时次数为 70 次。
结果表明,与之前的 3.52 位相比,每个维数减少到了 3.44 位(Menick & Kalch- brenner,2018 年)。视觉评估还显示,生成的图像捕捉到了大多数图像的长期结构。
古典音乐
他们在 Dieleman 等人发表的古典音乐数据集(Dieleman et al.,2018)上训练了该模型,以测试 Sparse Transformer 处理超长上下文的能力(比 Enwik8 长五倍以上)。不过,作者也指出,由于无法获得数据集的详细信息,因此无法与现有研究进行比较。
然而,利用 Dieleman 等人发表的古典音乐数据集(Dieleman et al.事实上,可以在以下网站上听到:
https://openai.com/blog/ sparse-transformer
稀疏变形金刚》有哪些创新?
下文将介绍稀疏变换器背后的理念及其实际工作原理,目的是让大家直观地了解如何降低计算复杂度。
了解现有的关注点
在考虑 "稀疏变换器 "时,了解现有 "注意力 "的方向非常重要。作者还逐层展示了现有注意力的方向。具体来说,下图 2 显示了 CIFAR-10 在 128 层网络上的训练结果。

因此
在(a)所示的网络初始层中,可以看到 ATTENTION(注意力)被导向了紧接着的信息,即用白色标出的信息。
在(b)所示的第 19 层和第 20 层中,注意力被引导到行方向和列方向。这可以看作是对带宽类特征的有效学习。
(c)显示的是注意力分散在整个图像中。
(d) 第 64 至 128 层显示出稀疏性,不清楚注意力的方向。
Sparse Transformers(稀疏变换器)试图在这些现有 Attention 功能的基础上设计出更高效的 Attention。
在稀疏变换器中设计注意力
稀疏变换器中的注意力使用上述(b)和(c)中的注意力特征。
根据论文中的图表,以 6 x 6 的图像为例进行说明。
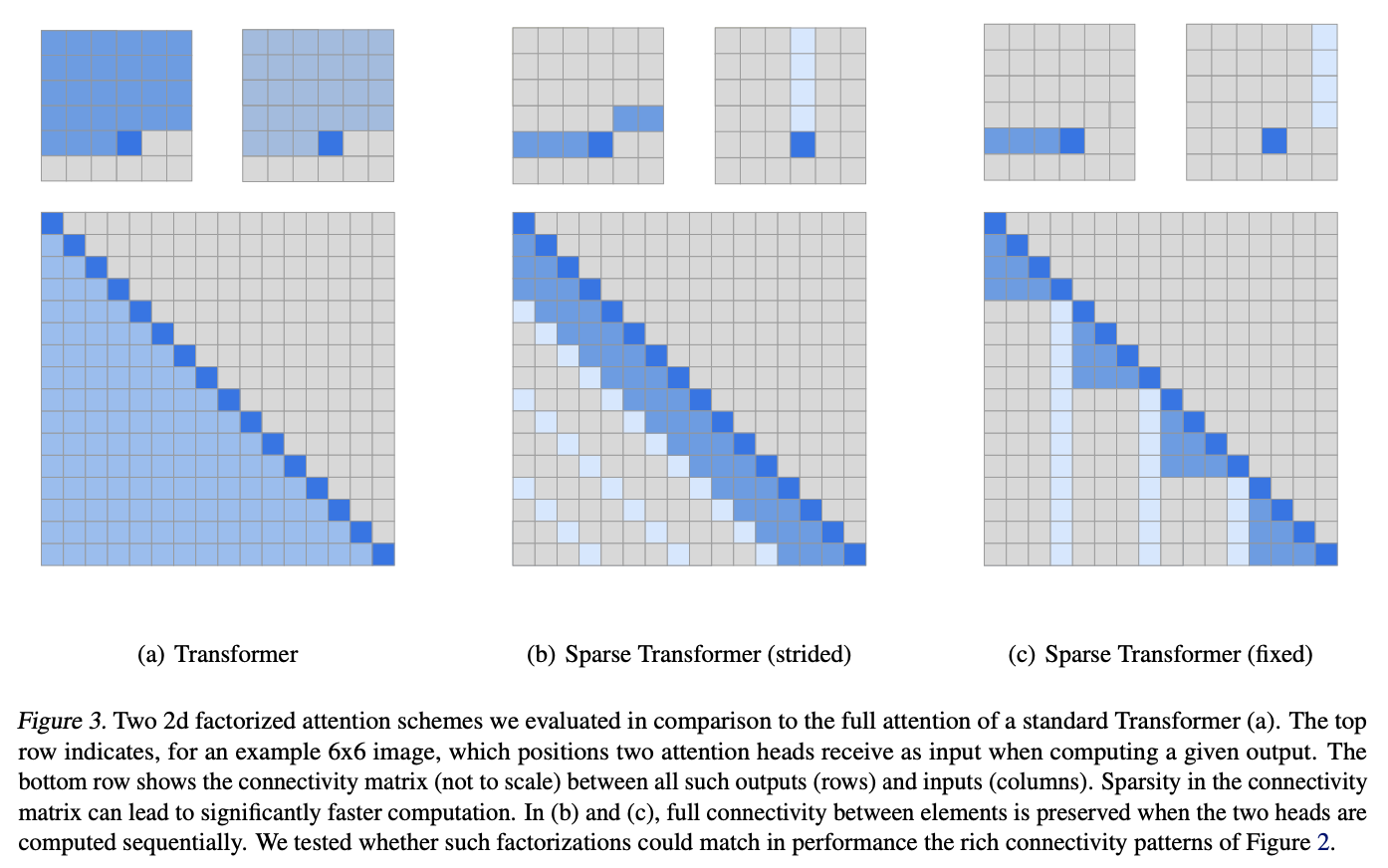
(a) 变压器(全神贯注)
图 3(a)中的注意力是正常变换器使用的注意力,它将注意力引向自身前方的所有位置。因此,计算复杂度为 $O(n^2)$。
(b) 稀疏变换器(阶梯式关注)
图 3(b) 中的 Attention 将头部分为两部分。蓝色部分的注意力并不集中在自己位置之前的所有元素上,而只集中在最后三个元素上。浅蓝色部分的注意力则集中在每三个元素上。
简而言之,蓝色引导水平方向的注意,而浅蓝色引导垂直方向的注意。这再现了上一幅图中状态(b)的注意力模式。
实验还表明,这种注意力对于具有周期性趋势的数据(如图像和音频)也很有效。
(c) 稀疏变换器(固定注意力)
在图 3(c)中,(b)中的 Strided Attention 使用相对位置来引导 Attention,而(c)中的 Fixed Attention 则添加了绝对位置元素来确定引导 Attention 的位置。蓝色表示 Attention 的位置。因此,蓝色显示的元素将注意力引导到自己前面的一些元素上,而浅蓝色显示的元素则将注意力以固定间隔垂直引导到所有元素上。
实验表明,这种 "注意 "对句子等文本信息很有效�
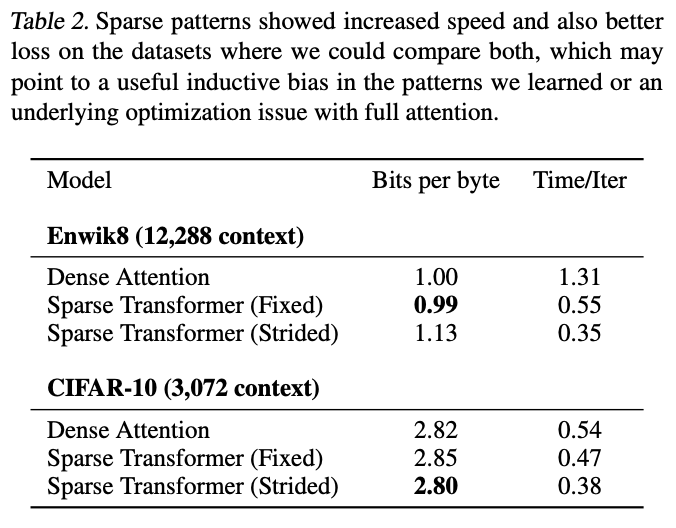
稀疏变换器中的跨步注意力和固定注意力
在图像和文本数据中使用 Strided Attention 和 Fixed Attention 的实验结果。
- Strided Attention 适用于图像数据集和
- Fixed Attention 适用于文本数据集
研究发现...
摘要
在 "稀疏变换器 "中,我们逐层研究了现有 "注意力 "的行为,并通过两种新引入的架构--"阶梯式注意力 "和 "固定注意力"--重现了我们认为重要的行列方向和全方位观察的行为。Strided Attention 和 Fixed Attention 这两个新引入的架构能够重现这些行为,解决了旧转换器的计算问题,并在发表时获得了多个 Sota。
自稀疏变换器(Sparse Transformers)以来,还有人尝试优化变换器的计算复杂度。如果你愿意,也可以参阅 Longnet 和其他论文。



与本文相关的类别


![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


