
突破计算时间和内存的限制!
三个要点
✔️ Local-Sensitive-Hashing 允许计算所需元素之间的 Attention
✔️ 可逆层节省了激活,这与层数成正比增加。内存减少
✔️ 变压器计算量从 $O(L^2)$ 减少到 $O(L\log L)$。
Reformer: The Efficient Transformer
written by Nikita Kitaev, Łukasz Kaiser, Anselm Levskaya
(Submitted on 13 Jan 2020 (v1), last revised 18 Feb 2020 (this version, v2))
Comments: ICLR 2020
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
自变压器发布以来,许多巨大的模型已经发布,它们在各种任务中展示了高性能,如 BERT(在变压器的编码器部分使用注意层堆叠多达 24 层)和 GPT-2(在解码器部分堆叠多达 48 层)。然而,由于它们体积庞大,不适合用于计算。然而,由于它们的体积太大,计算成本也会迅速增加,因此目前正在积极研究如何从不同的方向提高模型的效率,而不是简单地增加层数来提高性能。在这一背景下,Reformer 是提高变压器效率的尝试之一。
Transformer 的自我关注计算复杂度为 $O(n^2)$,当插入长句时内存使用量会迅速增加,Reformer 尝试通过设计关注方向来解决这一问题。
变形金刚有哪些问题?
变换器的计算复杂度随输入序列的增加而呈二次曲线增加。这导致计算时间和内存占用非常长。
计算量增加的主要原因是缩放点积自注意力,它是 Transformer 的一个关键组件。首先,Scaled Dot-Product Self-Attention 使用查询和键值对计算 Attention。换句话说,缩放点积自关注计算公式使用查询、键和值($Q, K, V$)来计算
$$Attention(Q, K, V) = softmax(\frac{QK^T}{sqrt{d_k}}V)$$.
查询用 $d_k$ 表示,其中 $d_k$ 是查询的深度。($d_k$ 表示查询深度和值(Q,V),其中查询深度和值(Q,V)的乘积是文档长度($n$)的平方)。因此,在输入 2046 个标记的情况下,用于计算注意力的矩阵大小为 2024*2024,这意味着在计算注意力时需要处理一个包含约 410 万个元素的矩阵。
Reformer 采用了两种架构--局部敏感哈希算法和可逆残差层。本地灵敏哈希算法和可逆残差层可以用较少的内存处理较长的输入序列。
使用变形器的结果
我们在两个数据集(imagenet64 和 enwik8-64k)上对 Reformer 的性能进行了比较实验。实验的层数设置为 3,单词嵌入和隐藏的维度($d_{model}$)为 1024,中间层的维度数($d_{ff}$)为 4096,头数和批量大小均为 8。
下文图 5 右侧是计算时间图,据称本文提出的 Reformer LSH 注意不会像传统变换器那样增加计算时间,即使文本较长、批次较少也是如此。所提出的 Reformer LSH 注意力是 Reformer 计算时间的图形。
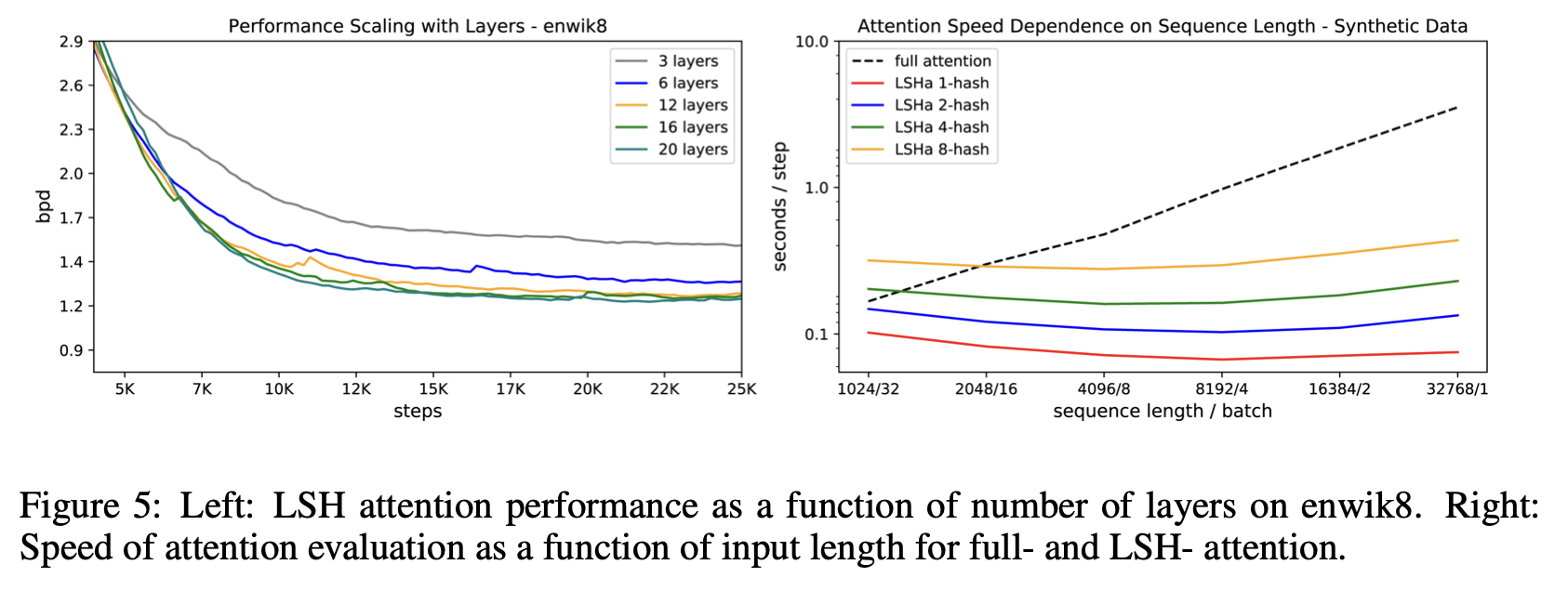
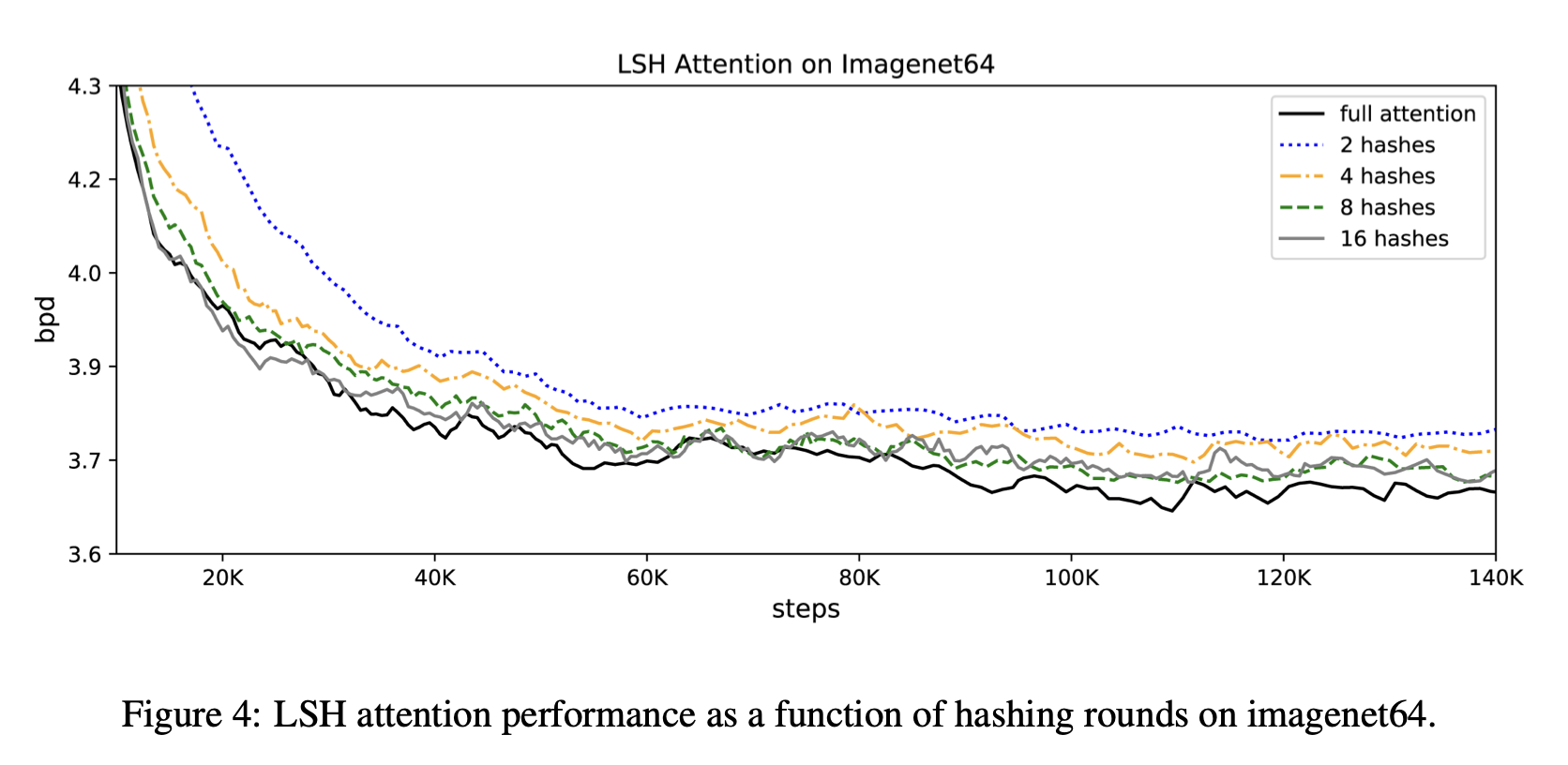
尽管计算时间减少了,但精度与普通变压器几乎相同。更具体地说,论文中的图 4 描述了精确度。从图中可以看出,即使哈希值为 8,其性能也几乎与普通转换器(全神贯注)相同。
下面,我们将看看 Reformer 在减少计算时间和内存使用方面有哪些创新。
改革者的创新
Reformer 采用以下两种架构,大大减少了内存用量
- 本地敏感哈希算法(LSH)
- 可逆残余层
什么是本地敏感散列(LSH)?
这项研究的理念不是像传统的 Attention 那样计算所有内积并获取与查询接近的密钥,而是找到一种无需计算所有内积就能获取与查询接近的密钥的方法。这就是我们的想法。这是一种称为本地敏感散列(LSH)的技术。
更具体地说,利用一些数学公式,Attention 可以写成下面这样。
$$Attention(Q, K, V) = softmax(\frac{QK^T}{sqrt{d_k}}V)$$.
这意味着,注意力也会被引导到相关性不高的元素上。这项研究的论点是,计算整个查询的效率很低,而实际上只检索相关的部分就足够了。我们的想法是获取与查询相似的元素(键),而无需计算所有元素的 Attention。因此,不需要拥有所有的关键字,只需要拥有与每个关键字 $q_i$ 接近的 $K$ 子集,就能实现 $QK^T$ 的目标。这可以用数学形式表示如下。
$$softmax(\frac{q_i K^T}{sqrt{d_k}}V)$$.
此外,还提出了 LSH 关注作为实现这一目标的机制。
・LSH 请注意
Reformer 使用 LSH 算法对输入进行分类,即给相似的元素赋予相同的哈希值,以提取与查询接近的键值;LSH 算法有多种,但 Reformer 使用的算法是随机投影法。
随机投影会以随机角度旋转分散在二维平面分区中的点,因此距离较近(相似)的点很有可能会靠近在一起,而距离较远(不相似)的点则会被划分到不同的分区中。这样就可以只提取与查询点接近的关键点。
具体来说,在图 1 的上图中,两点相距甚远,在三次旋转中只有一次位于同一区间。相反,在下图中,两点距离较近,因此在三次随机旋转中,它们都在同一小格中。这些区域被称为哈希桶,如果一个向量在三次随机旋转后都在同一个哈希桶中,我们就认为它是同一个哈希值。左侧的注意点是只将注意力引向与查询 $q_i$ 在同一个桶中的键。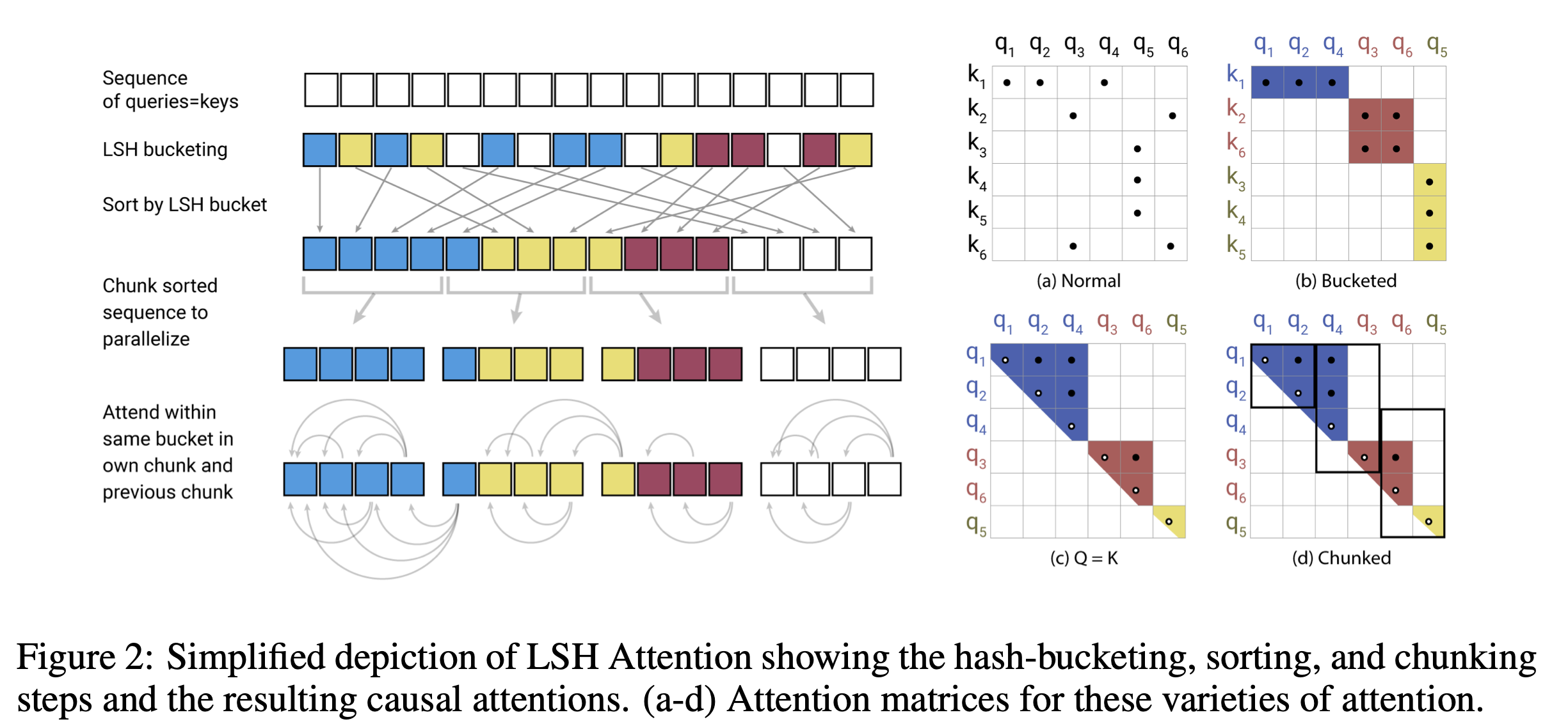
更具体地说,根据图 2 左侧的示意图,Reformer 的行为表明,它将长序列的输入等同于一个查询和一个键。这样做是为了防止在特定散列中出现大量查询和无键的情况。实验证明,查询和密钥的这种等价关系没有问题,如图 3 所示。(见下文。)
接收输入后,LSH 会将其分成若干个桶。对每个 LSH 桶进行排序。接下来,数据被分割成相同长度的块。计算每个数据块和上一个数据块的注意力,以提取感兴趣的关键字。
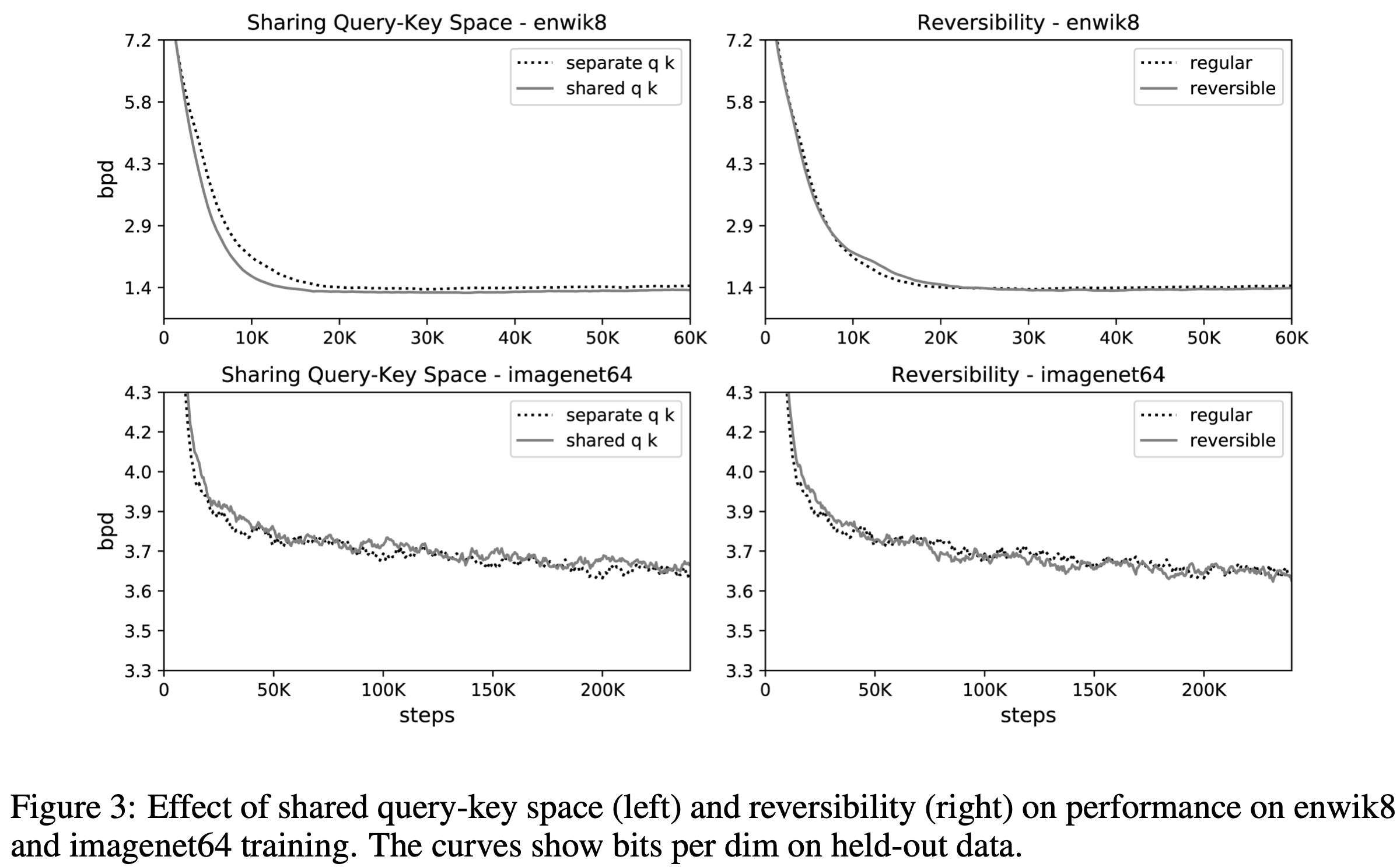
从图 3 左侧可以看出,在 imagenet64 数据集和 Enwiki8 中使用相同的查询和密钥并没有什么缺点。
什么是可逆残余层?
Reformer 的另一个重要理念是可循环残差层,通过消除存储中间计算状态的需要,可显著减少 Attention 的计算量。具体来说,通常需要存储激活函数的激活后值才能执行反向传播,但模型越大,如 BERT 和 GPT 系列,隐层维度和层数就越大,需要存储的内存也就越多。因此,为了减少内存使用量,我们尝试使用一个子层,根据上游层激活后激活函数的值计算下游激活函数的值。
具体来说,上述残差连接用 $y = x + F(x)$ 表示。ResNet 最早采用这种架构,是为了通过增加深度学习的层数,避免输入信息无法反映到输出中(信息丢失)的问题。在 ResNet 中采用时,该系统通过在特定层中直接向输出层添加数据,成功地积累了更高效的学习。
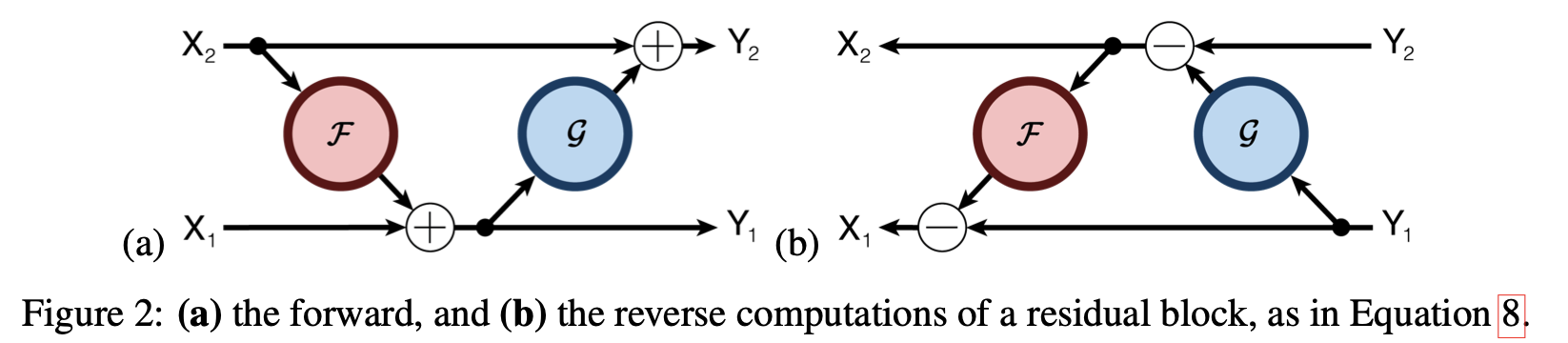
对 ResNet 架构的进一步改进是可逆残差网络。这种网络能够通过将输入分成两个系统,从下游结果逆向计算到上游结果。
RevNet 计算 1.
首先,输入和输出被分解成两个系统 $(X_1,X_2)$,并输入到两个层(F,G)。计算出的结果如下:$(X_1, X_2)$ 为输入,$(X_1, X_2)$ 为输出。
$$y_1 = x_1 + f(x_2)$$
$$y_2 = x_2 + g(x_1)$$
RevNet 计算 2.
RevNet 的最终输出是 $Y_1$ 和 $Y_2$ 的连接。
RevNet 中的反向传播
RevNet 中的反向传播可以可逆地计算,具体表现如下
$$x_1 = y_1 - f(x_2)$$
$$x_2 = y_2 - g(x_1)$$
虽然到此为止,RevNet 乍一看似乎使模型变得复杂,但这种架构无需像过去那样,在训练过程中存储用于反向传播输出结果的计算中间状态。这是因为反向传播所需的前一个激活函数的值 $X_1、X_2$ 会分别计算出来。
这样可以避免存储通常需要存储的所有后激活函数值,从而节省内存。下图是《可逆残差网络:无需存储激活函数的反向传播》中的可逆残差网络示意图。
可逆残差网络:不存储激活的反向传播。
可逆残差网络(RevNet)的思想被应用到变压器中,成为一种改革器,因为变压器的基本结构是注意和前馈的重复。在变压器中,$F, G$ 是注意和前馈(Attention and FeedForward),如下所示。
$$Y_1 = X_1 + Attention(X_2)$$
$$Y_2 = X_2 + FeedForward(X_1)$$
此外,在返回节目分页期间
$$X_1 = Y_1 - Attention(X_2)$$
$$X_2 = Y_2 - FeedForward(X_1)$$
来找出前一层激活后的激活函数值。
实验表明,引入这种计算方法对精确度没有影响。(图 3 右侧)
摘要
介绍了 Reformer(可逆变换器),这是一种降低自然语言处理中变换器计算复杂性的尝试。这样就可以用更少的计算资源训练出更高精度的模型。
还有其他一些试图降低变压器计算复杂度的模型,如 Longformer,如果你感兴趣,可以研究一下。



与本文相关的类别


![[MusicLM]谷歌开发的文本到音乐生](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/musiclm-520x300.png)


