
CNN的内核大小是否应该增加?
三个要点
✔️ 拟议的具有31x31大内核的CNN架构
✔️ 成功地用5个准则缩放内核,包括使用深度-明智卷积
✔️ 预训练模型的下游任务转换性能的优异结果
Scaling Up Your Kernels to 31x31: Revisiting Large Kernel Design in CNNs
written by Xiaohan Ding, Xiangyu Zhang, Yizhuang Zhou, Jungong Han, Guiguang Ding, Jian Sun
(Submitted on 1 Jul 2021)
Comments: CVPR2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
在一个典型的卷积神经网络(CNN)中,通过堆叠小核,如3×3,建立起一个大的感受野。
相比之下,视觉变形器(ViT)最近的主要发展--多头自留地(MHSA),只用一个单层就能实现大的感受野。
鉴于这些ViT的成功,问题来了,是否可以用少量的大核来代替现有的CNN政策,即用一个大的感受野和许多小核来使CNN更加接近ViT。
基于这个问题,本文提出了RepLKNet,一个使用31×31内核大小的CNN架构,这比一般的CNN要大。结果显示了出色的性能,包括在ImageNet上达到87.8%的Top-1准确率,以及下游任务性能的显著改善。
应用大果核的准则。
简单地将大型卷积应用于CNN会导致性能和速度的下降。为此,提出了有效利用大内核的五个准则。
准则1:大深度的卷积在实践中可以是有效的。
使用大核在计算上是很昂贵的,因为参数和FLOPs的数量随着核的大小呈四次方增加,但这个缺点可以通过应用深度明智(DW)卷积而得到显著改善。
在提议的方法中,RepLKNet(详情见下文),将内核大小从[3,3,3,3]增加到[31,29,27,23],导致FLOPs增加18.6%,参数数增加10.4%。一个担忧是,DW卷积运算在现代并行计算机(如GPU)上可能变得非常低效。然而,由于内存访问的比例随着内核大小的增加而减少,预计实际延迟的增加不会像FLOPs的增加那样多。
备注。
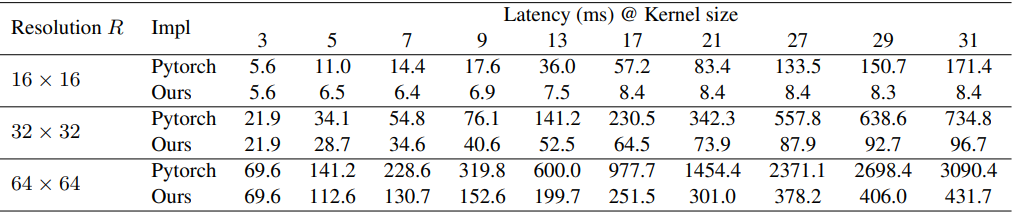
普通的深度学习工具,如Pytorch,不能很好地应对大型DW卷积,所以本文使用了一个改进的实现,如下表所示。
准则2:身份捷径对于具有大内核的网络是至关重要的。
当使用带有DW卷积的MobileNet V2作为基准时,应用3x3或13x13内核的结果如下

如表所示,当有捷径可用时,使用较大的内核可以提高性能,但在不使用捷径时则会降低精度。
准则3:用小内核重新参数化(re-parameterizing())可以改善优化问题。
用9x9和13x13替换MobileNet V2的内核大小,并应用Structual Re-parameterisation()方法进一步提高了性能,如下表所示。
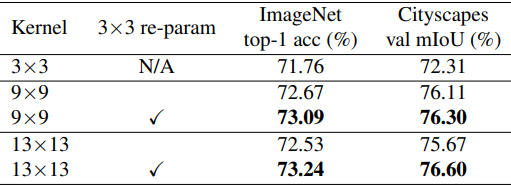
该方法如下:并行建立一个大内核层和一个3X3层,在训练后将批量归一化层和3X3内核融合成一个大内核。

因此,重新参数化技术可以提高优化效果。
准则4:大卷积比Imagenet分类精度提高下游任务性能。
在上表中,显示了在ImageNet上预训练的模型在Cityscapes上接受DeepLabv3+()语义分割任务时的表现。通过将内核大小增加到9x9,ImageNet的准确性提高了1.33%,而Cityscapes mIoU提高了3.99%。
(这一趋势也在论文中提出的RepLKNet的实验结果中观察到,这可能是由于更大的内核导致有效感受野和形状偏差的增加。)
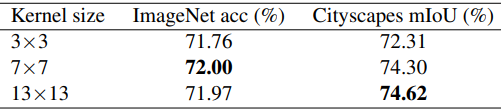
准则5:即使特征图很小(如7x7),大内核(如13x13)也是有效的。
对于MobileNet V2,相对于特征图来说,更大的内核尺寸的结果如下。
基于这五条准则,本文提出了一个名为RepLKNet的CNN架构。
建议的方法:RepLKNet。
RepLKNet是一个具有大内核设计的纯CNN架构,由以下部分组成
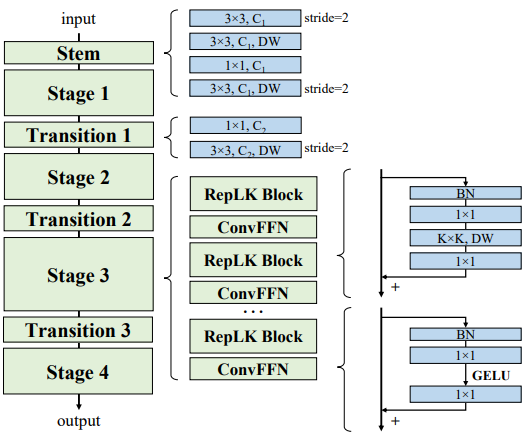
RepLKNet架构由干块、阶段和过渡块组成。
茎部。
干层是第一层,其设计是为了让多个定罪层首先获得详细信息,以便在下游的高密度预测任务中实现高性能。如图所示,各层按以下顺序排列:3x3卷积和2x下采样,然后是DW3x3层、1x1卷积和DW3x3层的下采样。
阶段
第1-4阶段各包含几个RepLK块,并使用捷径和DW的大内核(见准则2,1)。在DWconv前后使用1x1卷积,每个DW层使用5x5内核进行再参数化(见准则3)。
过渡区块
过渡块位于各阶段之间,1x1卷积用于较大的通道,DW3x3卷积用于2倍的下采样。一般来说,RepLKNet有三个架构超参数:RepLK块的数量$B$,通道维度$C$和核大小$K$。因此,RepLKNet的架构由$[B1,B_2,B_3,B_4], [C_1,C_2,C_3,C_4], [K_1,K_2,K_3,K_4]$定义。
实验结果
首先,RepLKNet的超参数被固定为$B=[2, 2, 18, 2], C=[128, 256, 512, 1024]$,并对不同的$K$进行评估。
设RepLKNet-13/25/31,其中内核大小$K$分别为[13,13,13,13],[25,25,25,13]和[31,29,27,13]。我们还构建了一个小内核基线RepLKNet-3/7,其中所有的内核大小为3或7。
当骨干是在ImageNet上训练的模型时,ImageNet中的表现和语义分割任务(ADE20K)的表现如下。
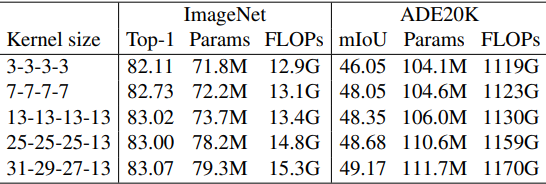
ImageNet的结果显示,将核的大小从3增加到13可以提高准确性,但进一步增加核的大小并不能提高性能。
另一方面,ADE20K的性能增加,表明更大的内核对下游任务很重要。在接下来的实验中,RepLKNe-31B是上述设置中内核大小最大的模型,RepLKNet-31L是$C=[192, 384, 768, 1536]$的模型。
同时,$C=[256, 512, 1024, 2048]$,RepLK块的DW卷积层通道被设置为RepLKNet-XL的1.5倍输入。
ImageNet分类性能
然后将ImageNet的分类性能与Swin进行了比较,后者具有类似的整体架构。
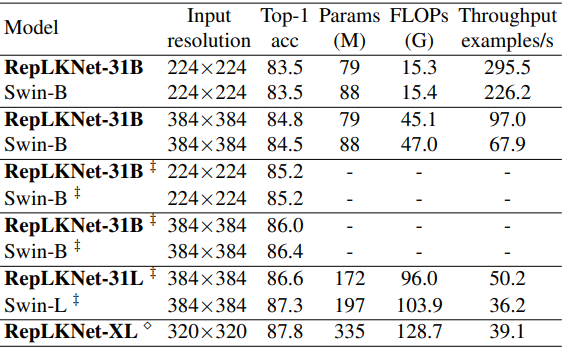
‡标记表示在ImageNet-22K上进行预训练,然后在ImageNet-1K上进行微调的情况,而未标记的情况是只在ImageNet-1K上训练。
总的来说,结果显示RepLKNet在准确性和效率方面显示出良好的权衡,尽管大核不像以前那样适合于ImageNet分类。特别是,在ImageNet-1K上训练的RepLKNet-31B显示出良好的性能,达到84.8%的准确率,高于Swin-B,并且运行速度快43%。
语义分割性能
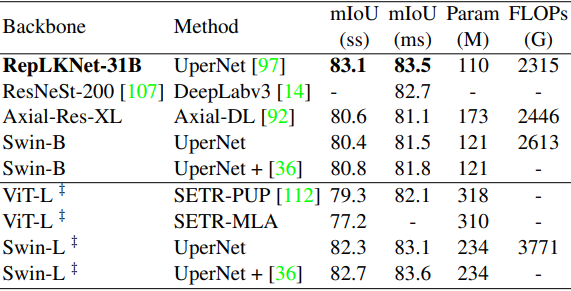
接下来,使用预先训练的模型作为骨干的Cityscapes和ADE20K的结果分别显示如下。
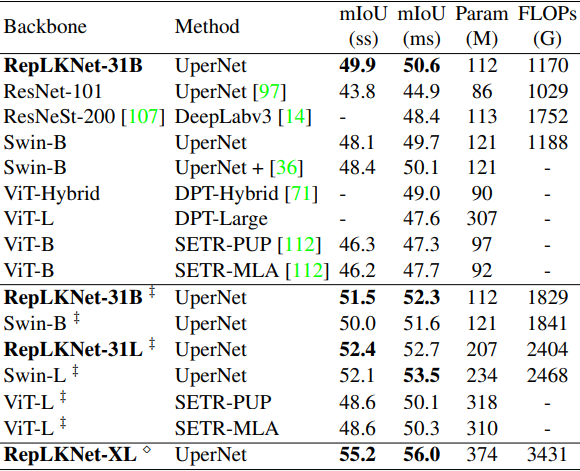
‡标记表示在ImageNet-22K上进行了预训练,未标记的表示在ImageNet-1K上进行了预训练。
总的来说,RepLKNet-31B显示了非常好的结果,超过了现有方法。特别是,它在Cityscapes上的表现非常好,甚至超过了Swin-L,后者是在ImageNet22K上预先训练的。
物体检测性能
那么,物体检测任务的结果如下
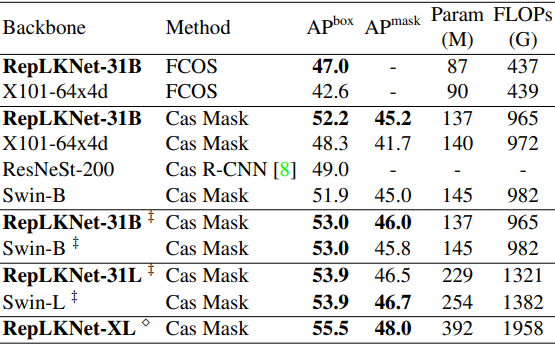
总的来说,结果表明,所提出的方法只是简单地替换了骨干,并且可以用更少的参数和FLOPs来表现,甚至比现有的方法更好,证明了所提出的方法的高下游任务性能。
为什么大的内核是有效的?
关于使用大内核的有效性,该文件指出
- 1)具有大内核的CNN比具有小内核的CNN具有更大的ERF(有效接收场)。
根据ERF(有效感受场)()理论,ERF与$O(K\sqrt(L))$成正比(其中$K$是内核大小,$L$是层数),内核的大小导致有效感受场的大小。
此外,由于更深的层数会导致更难的优化,因此可以用大的内核来获得大的ERF,而层数更少,更容易优化。事实上,ERF的可视化显示在下图中。
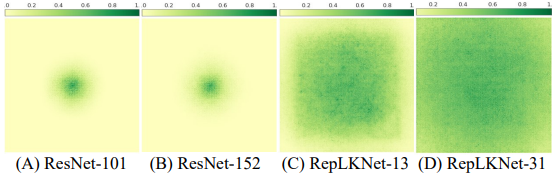
- 2)大内核模型具有与人类相似的形状偏差。
- 3)大内核设计是一个通用的设计元素,可与ConvNeXt一起使用。
- 4) 较大的内核在扩张率较高的情况下表现优于较小的内核。
摘要
在CNN架构的设计中,增加内核大小长期以来一直被忽视。
在本文中,根据五项准则,使用大型卷积核,使性能得到显著提高,特别是在下游任务中。
这项研究的结果对CNN和ViTs都有影响,因为在CNN的设计中,有效感受场值得关注,而大型卷积化能显著减少CNN和ViTs之间的性能差距。



与本文相关的类别






