超轻量级CNN语音识别模型!谷歌开发的 "ContextNet "解读
三个要点
✔️ 谷歌提出轻量级CNN语音识别模型
✔️ 用挤压和激发模块考虑全球背景
✔️ 用渐进式下采样减少计算成本
ContextNet: Improving Convolutional Neural Networks for Automatic Speech Recognition with Global Context
written by Wei Han, Zhengdong Zhang, Yu Zhang, Jiahui Yu, Chung-Cheng Chiu, James Qin, Anmol Gulati, Ruoming Pang, Yonghui Wu
(Submitted on 7 May 2020 (v1), last revised 16 May 2020 (this version, v3))
Comments: Submitted to Interspeech 2020
Subjects: Audio and Speech Processing (eess.AS); Computation and Language (cs.CL); Machine Learning (cs.LG); Sound (cs.SD)
code:

本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
人们对建立基于CNN而不是RNN或变形金刚的E2E(端到端)语音识别模型的兴趣越来越大。虽然基于RNN和Transformer的方法在语音识别中往往更准确,但它们往往有大量的参数,在计算能力方面非常昂贵。
另一方面,基于CNN的模型比RNN和变形金刚的参数效率更高,这可能使小公司在实践中更容易产生高质量的语音识别模型。
然而,尽管CNN模型善于通过卷积考虑近距离的特征,但它们不善于考虑远距离的全局背景,甚至SOTA的CNN模型QuartzNet也不如RNN/Transformer模型准确。
在本文中,我们介绍了ContextNet,它通过挤压和激发考虑到了全局背景,并通过渐进式下采样减少了参数。尽管是一个基于CNN的模型,但ContextNet的准确性超过了基于Transformer和LSTM的模型。下图显示了模型大小和准确性(WER)之间的权衡,并显示ContextNet比AuartzNet和基于RNN/Transformer的模型具有最好的权衡性能。
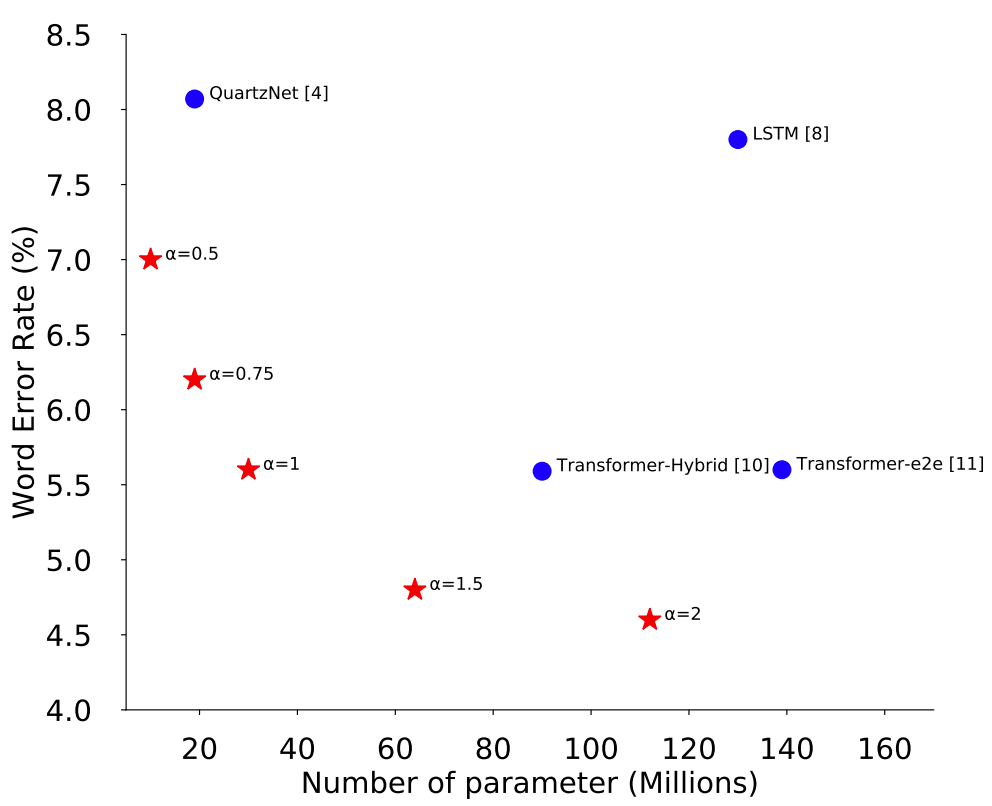
让我们来看看ContextNet模型的细节。
模型
端到端网络:CNN-RNN-Transducer
ContextNet网络基于RNN-Transducer框架 (https://arxiv.org/abs/1811.06621 ),由一个 用于输入音频的音频编码器、 一个用于输入标签的标签编码器和 一个结合两者的联合网络组成。ContextNet网络基于RNN-Transducer框架(),由一个用于输入语音的音频编码器、一个用于输入标签的标签编码器和一个结合两者的联合网络组成。在我们的方法中,音频编码器被一个基于CNN的编码器所取代,这是我们建议的一个新点。
编码器设计
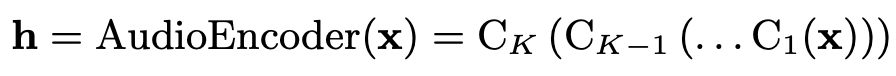
每个Ck(-)是一个卷积块,由几个卷积层组成,之后是批量归一化和激活函数。它还具有挤压和激励以及跳过连接功能。
在对C(-)进行详细描述之前,让我们从C(-)的重要模块开始。
挤压和激发
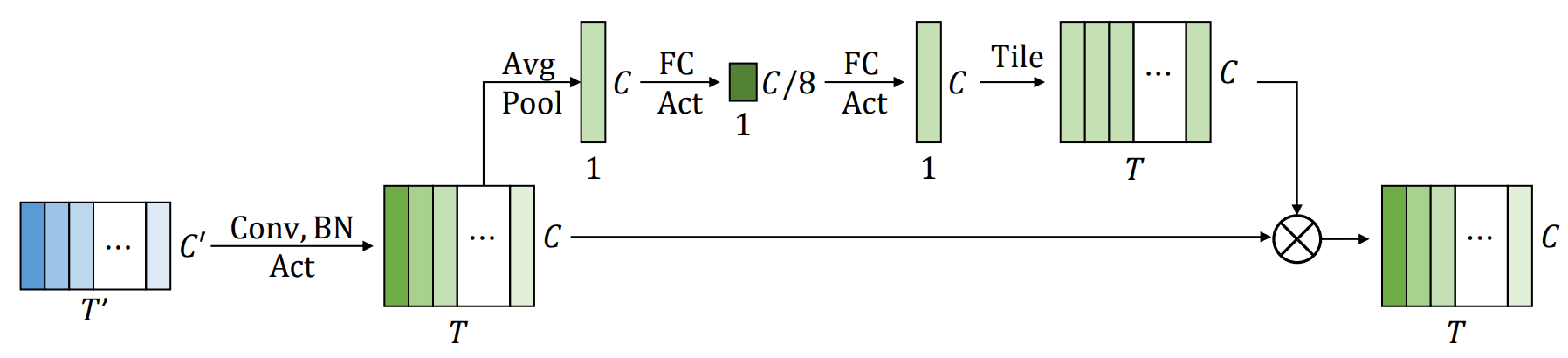
如上图所示,挤压和激发函数SE(-)对输入的x进行全局平均池化,将其转换为全局信道权重θ(x),然后根据该权重对每一帧进行逐元乘法。每一帧的元素明智的乘法。将这一想法适用于一维情况,我们得到以下方程。
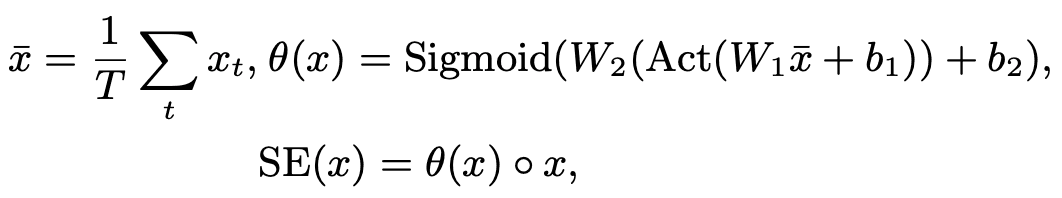
在tensorflow中做这件事的代码如下。它非常简单,你肯定应该尝试在你的模型中实现挤压和激发模块。
x_orig = x
x = tf.reduce_sum(x, axis=1) / tf.expand_dims(tf.cast(x_len, tf.float32), 1) # 平均池化
for i in rage(len(num_units))。
x = tf.nn.swish(fc_layers[i][x]))
x = tf.expand_dims(tf.nn.sigmoid(x), 1)
返回 x * x_orig
深度可分离卷积
为了在不牺牲性能的前提下实现更高的参数效率,我们使用深度可分离卷积,而不是单纯的卷积。conv(-)代表深度可分离卷积。
顺便说一下,深度可分离卷积是MobileNet中使用的一种技术,它以轻量级模型著称,先进行深度卷积(空间方向),然后再进行点卷积(通道方向)。这种技术用于MobileNet,它以其轻量级模型而闻名。
使用Tensorflow进行深度卷积的代码如下所示。
Separable1D(filters, kernel_size, strides, padding) conv = tf.keras.layer.
唰的一声激活功能
Act(-)表示激活函数。我们测试了两个激活函数,ReLU和Swish,发现Swish的表现更好:Swish的导数比ReLU的更平滑,而ReLU在0和1之间是离散的。与ReLU函数相比,Swish函数的导数变化更平稳,因为ReLU函数是在0和1之间离散的,所以训练结果也可能更平稳。


在Tensorflow中,这可以通过以下方式实现。
X = tf.nn.swish(x)
卷积块
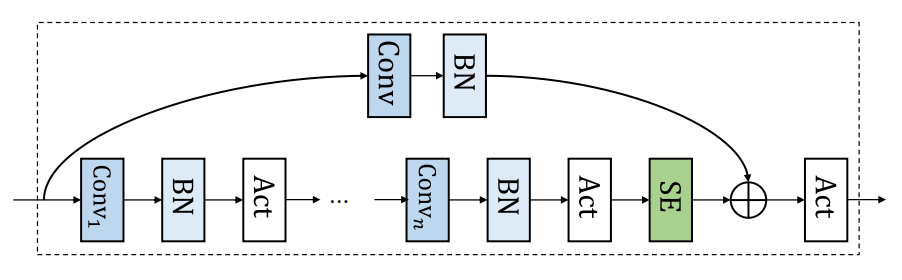
上述的各个模块可以如上图所示进行组合。而这里是C(-)在第一个方程式中的表示。


其中f^m是叠加的m层f(-),P(-)代表对残差的点状投影。这一部分的代码如下。
for conv_layer in conv_layers:
x = conv_layer(x)
x = se_layer(x)
x = x + residual(x_orig)
x = tf.nn.swish(x)
渐进式下采样
为了进一步降低计算成本,我们采用渐进式降采样。具体来说,我们通过逐步增加卷积层的步长进行实验,观察参数数量和性能之间的权衡。因此,当对ContextNet进行8倍的下采样时,可以获得最佳的权衡结果。
ContextNet的配置细节
ContextNet由23个卷积块组成(C0,...,C22),除C0和C22外,其他都有5个卷积层。下图是对架构细节的总结。
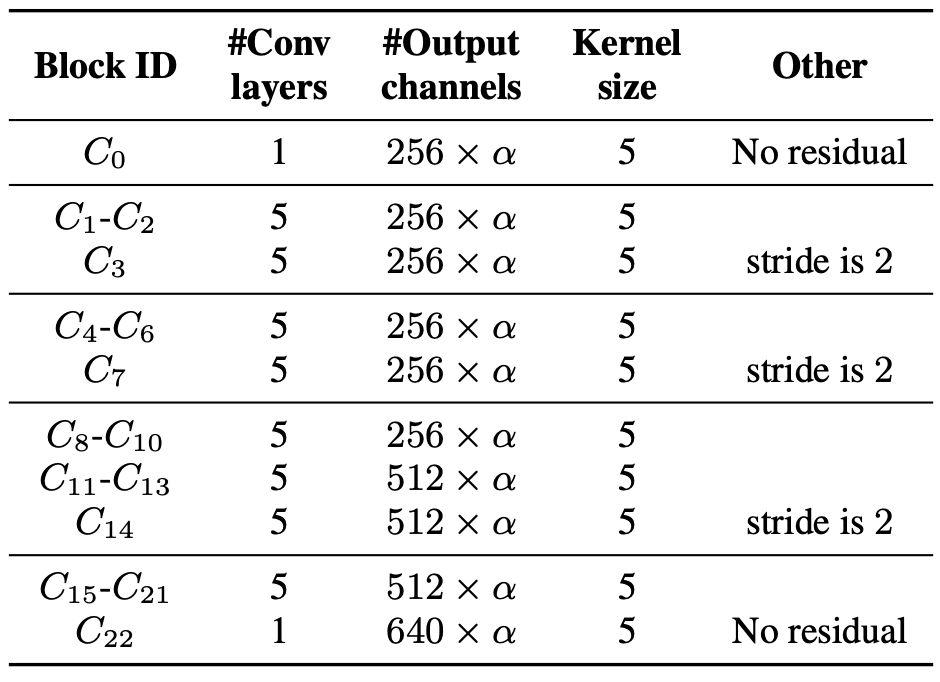
这里,全局参数α控制着模型的缩放,增加到α>1将增加卷积通道的数量。
实验结果
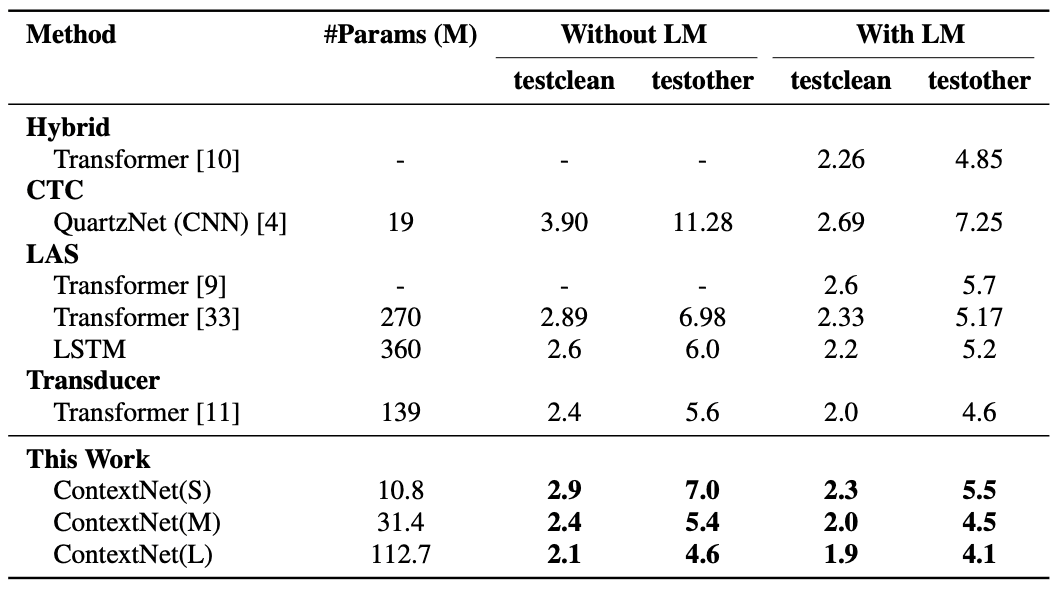
上图显示了在Librispeech数据集上测试时的误码率值。同样来自上图。我们可以看到,无论是有还是没有语言模型(LM),ContextNet的表现都超过了其他模型。
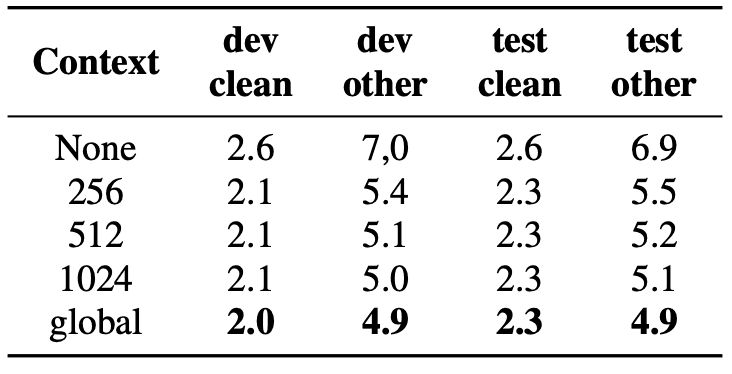
在下图中,你也可以看到,挤压和激发模块通过考虑全局背景,大大改善了性能。
最后
在这篇文章中,我们介绍了ContextNet,一个基于CNN的端到端语音识别模型。虽然现在普遍使用变压器,但其计算成本非常高,这使得个人和小公司难以负担。另一方面,如本文所示,基于CNN的变压器可以以相对较低的成本实现,那么为什么不使用挤压-激励和渐进式降采样等技术呢?



与本文相关的类别






![[wav2vec 2.0] Facebo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2020/Facebook_AIが公開_wav2vec_2.0_3-min-520x300.png)