[wav2vec 2.0] Facebook AI发布了一个新的语音识别框架!自我监督学习实现高准确率,无需正确答案标签!
三个要点
✔️ Facebook AI发布新的语音识别框架wav2vec 2.0。
✔️ 使用少量转录和未标记的语音进行自我监督学习。
✔️ 未标记和标记数据的准确率最高。
wav2vec 2.0: A Framework for Self-Supervised Learning of Speech Representations
written by Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
(Submitted on 20 Jun 2020 (v1), last revised 22 Oct 2020 (this version, v3))
Comments: Accepted at NeurIPS 2020
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG); Sound (cs.SD); Audio and Speech Processing (eess.AS)


介绍
Facebook AI发布了一个新的语音识别框架wav2vec 2.0。编码也是可以使用的,现在就可以供大家使用。本文最大的优点是充分利用了自我监督学习,只用少量的转录和未标记的语音数据就能达到很高的准确性。以往的方法需要数千小时的转录语音才能达到实际的准确性,但在实际中,很多情况下很难获得转录语音。事实上,这种正确的数据在7000多种语言中很难获得。
这就是自我监督学习的作用。自监督学习是一种从正确的标记数据中学习表示方法,并以正确的标记数据对模型进行微调。在本文中,我们用多层CNNs对语音进行编码,以掩盖潜在的表示。潜伏的表征被传达给Transformer网络,以建立一个情境化的表征。然后通过对比学习训练模型,以区分正确和错误的特征。
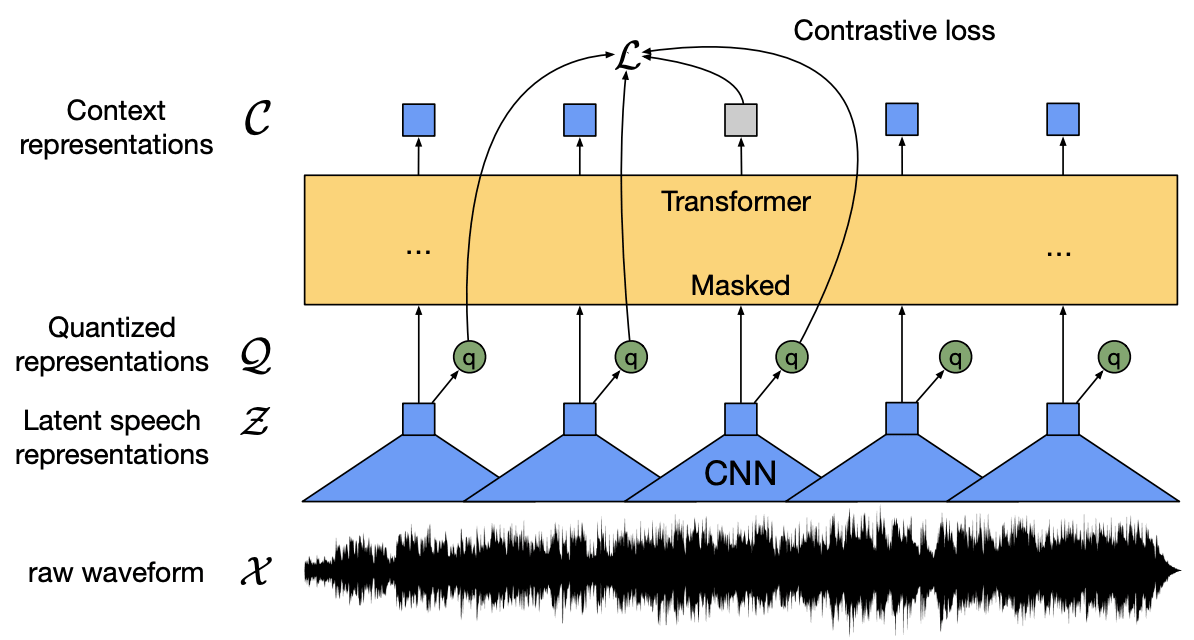
在训练部分,我们通过gumbel softmax来分离语音单元,它代表了对比度训练中的一种潜在表示。我们发现这种对比性学习比没有量化的目标更有效。在用未标记的语音进行预训练后,通过连接主义时间分类(CTC)损失,用标记数据对模型进行微调,并用于语音识别任务。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别






