
模型轻量化技术!轻量级和高性能的语音情感识别模型LightSER-NET!
三个要点
✔️ 语音情感识别模型LightSER-NET被ICASSP2022接受
✔️ 使用三个平行CNN的简单结构成功减重
✔️ 实现类似SOTA的性能,同时减轻重量
Light-SERNet: A lightweight fully convolutional neural network for speech emotion recognition
written by Arya Aftab, Alireza Morsali, Shahrokh Ghaemmaghami, Benoit Champagne
(Submitted on 7 Oct 2021)
Comments: ICASSP 2022
Subjects: Audio and Speech Processing (eess.AS); Signal Processing (eess.SP)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
直接从语音信号中检测人类情绪(如喜悦、悲伤或惊讶)的技术在人机交互中发挥着重要作用。现有的研究和许多深度学习模型一样,需要大量的计算成本,因此很难真正将它们整合到系统中并在应用中使用它们。
因此,在本研究中,使用了三个具有不同过滤器大小的并行CNN,以同时实现高性能和单独的CNN结构的模型亮度。
三个并行的CNN分别负责三种类型的特征提取:频率、时间序列和频率-时间序列,为语音识别提供有效的高维特征提取。最后,产生的特征图被用于分类,同时实现了模型的轻量化和与SOTA相同的性能。
建筑

整个系统由三个主要部分组成:输入管道、 特征提取块 (Body)和 分类块(Head)。此外,身体部分由平行二维卷积(身体部分I)和局部特征学习块(LFLBs)组成。
输入管线
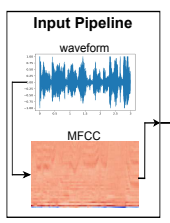
将语音信号在-1和1之间标准化后,计算出MFCC。与一般的处理方法一样,这里的MFCC是用汉明窗函数、快速傅里叶变换、Melfilter bank、反余弦变换等方法得出的。
身体部分 I
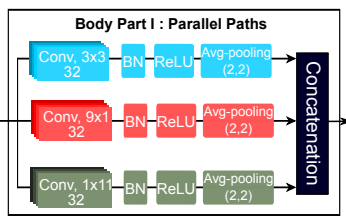
在这一步,平行CNN被应用于MFCC,以提取时间序列和频率方向上的特征的良好平衡。众所周知,拓宽卷积网络的接受域会导致分类性能的提高,本研究中采用了以下创新方法来拓宽接受域。
- 增加网络层
- 使用子采样块,如集合和较大的步幅
- 使用扩张卷积
- 使用深度卷积
此外,对于多维信号,每个维度都可以单独计算感受野。因此,在本研究中,使用9×1、1×11和3×3内核分别在频率、时间序列和频率-时间序列方向提取特征。
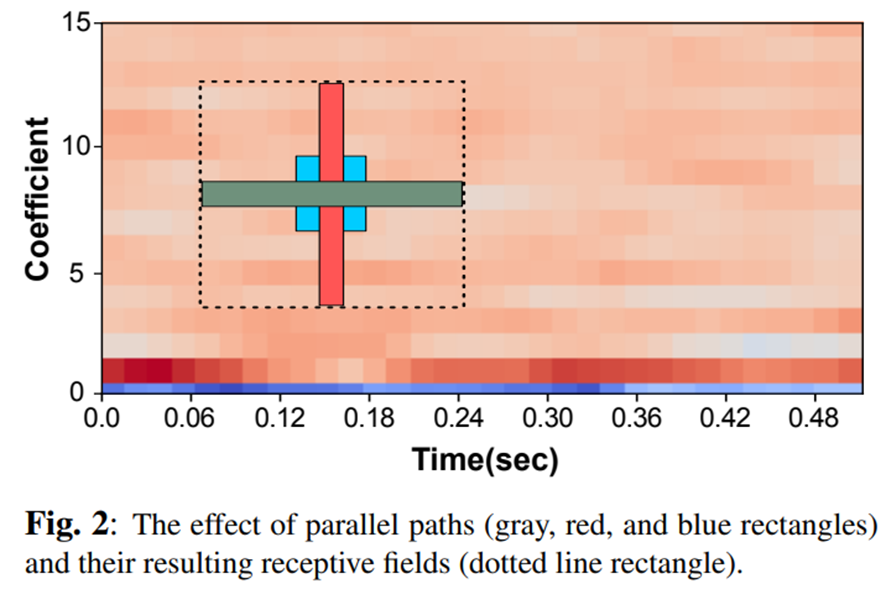
这种只有一条具有相同接收场大小的路径的技术减少了参数的数量和计算成本。下图显示了具有平行CNN的感受场大小。
身体第二部分
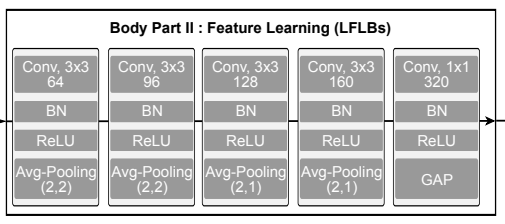
身体第二部分由几个局部特征学习块组成,并适应身体第一部分提取的特征。它由一个卷积层、一个批处理规范化层、一个ReLU和一个macspooling层组成。
全局平均池(GAP)也被用于最后一个区块,允许在不改变结构的情况下对不同长度的数据集进行训练。
头部
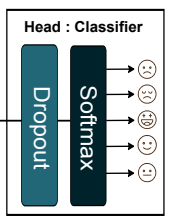
身体部分将非线性输入映射到线性空间,因此在全耦合层中只需要分类。因此,通过一个有规律的剔除层和一个softmax函数来保持低的计算成本。
实验
数据集
IEMOCAP和EMO-DB是常用于语音情感识别的数据集,我们已经用它们进行了实验。IEMOCAP是一个音频和视频的多模态数据集,每个数据集都被贴上了四个标签:快乐、悲伤、愤怒和自然。
EMO-DB也是一个德国的数据集,有十个专门的语音演员,并被贴上了七个标签:愤怒、自然、悲伤、恐惧、厌恶、快乐和无聊。
实验结果
为了处理数据集中各类之间的数据偏差,评估是基于三个指数:未加权的准确性(UA),加权的准确性(WA)和F1分数(F1)。
与其他语音情感识别模型的性能比较如下图所示。可以看出,不仅模型尺寸成功地减少了重量,而且性能也达到了与SOTA相当的水平。
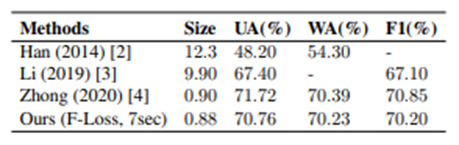
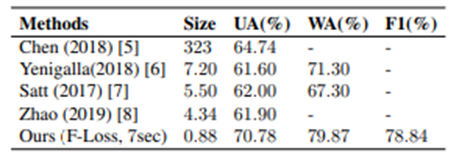
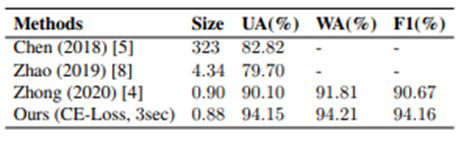
结论
在这项研究中,三个具有不同过滤器大小的并行CNN被用来进行有效和轻量级的特征提取。
在实际将语音识别集成到应用中时,轻量级的模型和快速的响应时间是很重要的,本文的内容可能对那些在接近实际应用的领域从事语音识别的人有帮助。



与本文相关的类别






![[wav2vec 2.0] Facebo](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2020/Facebook_AIが公開_wav2vec_2.0_3-min-520x300.png)