「ZERO-OFFLOAD」を使用して、10倍の大きさのモデルをGPUで学習することが可能に!
3 main points.
✔️ 1台のGPUで大規模モデル(10倍)を学習できるハイブリッドGPU+CPUの新システム
✔️ 128+ GPUsへの高い拡張性を持ち、モデル並列化との統合が可能
✔️ 6倍速の高速CPUAdam optimizer!
ZeRO-Offload: Democratizing Billion-Scale Model Training
written by Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, Yuxiong He
(Submitted on 18 Jan 2021)
Comments: Accepted to arXiv.
Subjects: Distributed, Parallel, and Cluster Computing (cs.DC); Machine Learning (cs.LG)



はじめに
ディープニューラルネットワーク(DNN)モデルの登場以来、DNNモデルの規模は急速に拡大し、最近のGPT-3モデルでは1,750億個という驚異的な数のパラメータを持つようになりました。またこのような規模の拡大が、GPT-3のような大きなモデルが高性能である理由の一つとなっています。しかし、これらのネットワークを学習するのは難しく、費用もかかります。10Bのパラメータを持つモデルを適切に訓練するには、約5~10万ドルもするNVIDIA V100が16台必要になります。このため、多くの研究者やデータサイエンティストにとって、このようなモデルの学習は費用面からも行うことができません。そのため、安価で効果的にDNNを訓練できるようにすることは、私たちが克服すべき課題となることは皆さんもわかると思います。
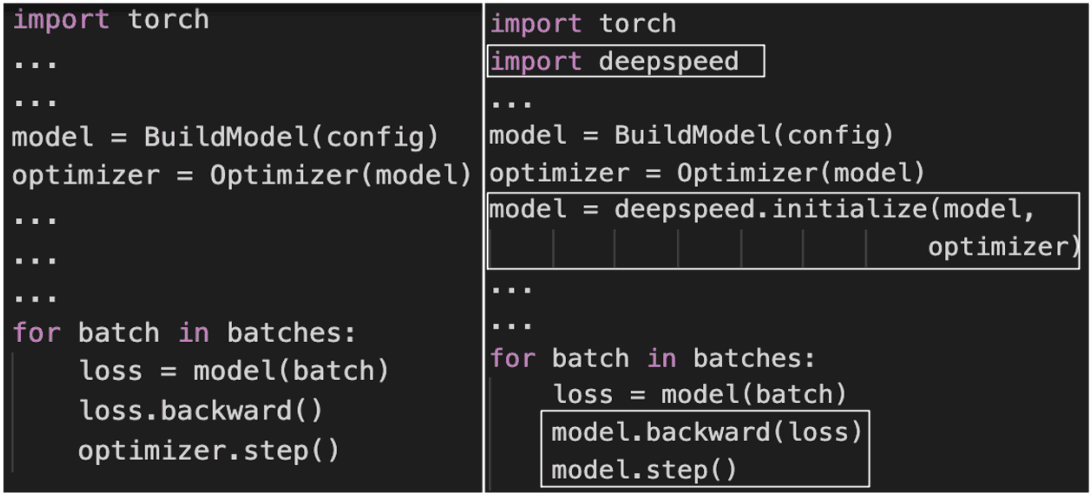 ZeRO-Offloadを統合するための PyTorch コードの変更点
ZeRO-Offloadを統合するための PyTorch コードの変更点
本稿では、オープンソースのDeepSpeed PyTorchライブラリの一部として、効率的でスケーラブルで使いやすいシステム「ZeRO-Offload」を紹介します。わずか数行のコードで、GPU上で最大10倍のモデルをトレーニングすることができます。また、スケーラビリティも高く、最大128GPUまでほぼリニアな高速化を実現しています。さらに、モデル並列化と組み合わせて、より大きなモデルを学習することができます。
重要なコンセプト
これまでにも、GPU上でメモリ容量以上の大規模なモデルを学習できるようにするための大きな取り組みが行われてきました。そのためにはモデルの状態(パラメータ・勾配・オプティマイザの状態)と残差の状態(活性化・一時的なバッファ・使用不能なメモリ)をメモリへの出入りで調整する必要があります。これらの取り組みは以下のように分類できます。
大規模モデル学習のスケールアップ
メモリの必要性を満たすために、複数のGPU間でモデルを分割することを指します。モデル並列化とパイプライン並列化は、モデルを垂直方向と水平方向にそれぞれ分割する技術です。最近のZeROは、すべてのモデルの状態をすべてのGPUで複製する必要をなくし、代わりに通信集合体を使って学習中に必要な情報を収集することで、モデル並列化をより効率的にしています。
大規模モデル学習のスケールアウト
これは、より大きなモデルサイズを学習するために単一のGPUを使用することを指します。これには大きく分けて3つの方法があります。
- 低精度または混合精度の数値を使用する方法
- チェックポイントから再計算してメモリと計算をトレードする方法
- CPUのメモリを使用する方法です。
ZeRO-Offload は 3 番目の方法に基づいています。
ZeRO-Offloadの特徴
ここでは、ZeRO-Offloadの特徴とその機能の仕組みについて説明します。
独自の最適オフロード戦略
ZeRO-Offloadは、モデル状態の一部をCPUにオフロードすることで学習メモリを拡張します(残留状態は処理しません)。その際の課題は、CPU の計算速度の低下と GPU-CPU通信のオーバーヘッドです。これらの課題を克服するために、Zero-Offloadは以下のようなグラフとして学習をモデル化し、GPUとCPUに分割します。Zero-Offloadは、次のような制約の下で、与えられたCPU-GPUペアに対して最適解を達成することができます。CPUがボトルネックにならないようにCPUの負荷をGPUよりもはるかに小さくし、CPUとGPUの通信量を減らしてメモリの節約を最大化しています。
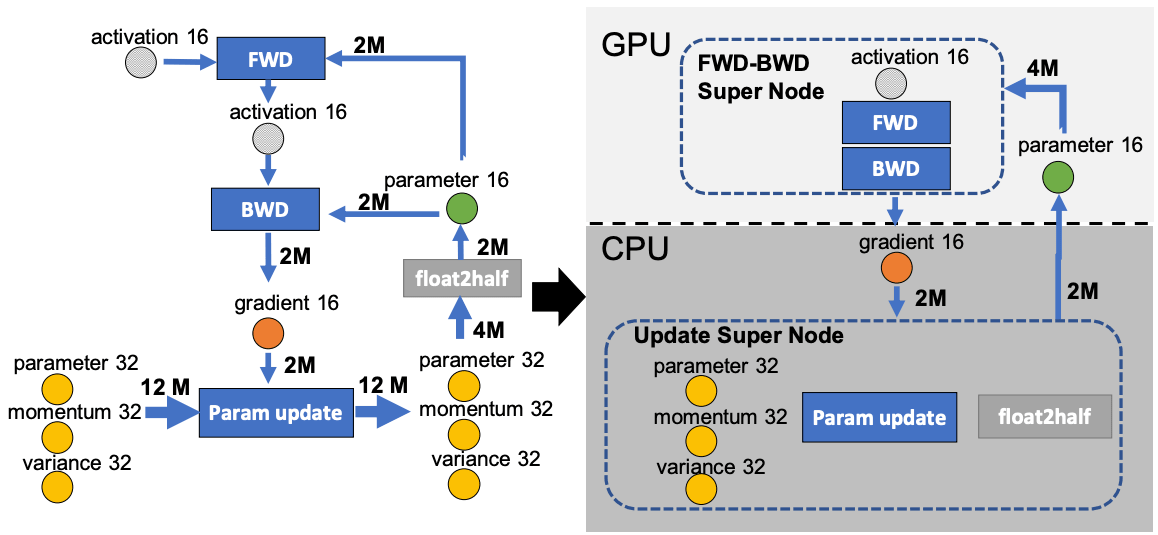 forward passeとbackward passeは時間的複雑度O(model_sizeexBatch_size)を持ち、FWD-BWD supernodeと呼ばれるGPUで実行されます。CPUがボトルネックにならないように、GPUよりもCPUの計算負荷を低くしたいので、時間的複雑度O(model_size)の重み更新やノルム計算をCPU上で行い、更新supernodeと呼んでいます。
forward passeとbackward passeは時間的複雑度O(model_sizeexBatch_size)を持ち、FWD-BWD supernodeと呼ばれるGPUで実行されます。CPUがボトルネックにならないように、GPUよりもCPUの計算負荷を低くしたいので、時間的複雑度O(model_size)の重み更新やノルム計算をCPU上で行い、更新supernodeと呼んでいます。
fp16のパラメータをGPUに格納し、fp16の勾配、fp32の運動量、分散、パラメータをCPUに格納します。これにより、4ノードシステムとなります。FWD-BWD supernode、Update supernode、gradient16(g16)、parameter16(p16) nodeである。
Single-GPU Scheduling
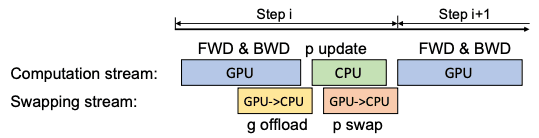 forward passの後に損失計算、backward passが行われ、これらはCPUとの通信を必要としません。計算されたgradientsはすぐにCPUに転送されるため、GPUに保存するためのメモリをあまり必要としません。勾配の転送とバックプロパゲーションをオーバーラップさせることができるため、通信コストをさらに削減することもできます。CPU上のパラメータに対してFP32の重み更新を行った後、FP16のGPUパラメータにコピーして処理を繰り返す。
forward passの後に損失計算、backward passが行われ、これらはCPUとの通信を必要としません。計算されたgradientsはすぐにCPUに転送されるため、GPUに保存するためのメモリをあまり必要としません。勾配の転送とバックプロパゲーションをオーバーラップさせることができるため、通信コストをさらに削減することもできます。CPU上のパラメータに対してFP32の重み更新を行った後、FP16のGPUパラメータにコピーして処理を繰り返す。
Multi-GPU Scheduling
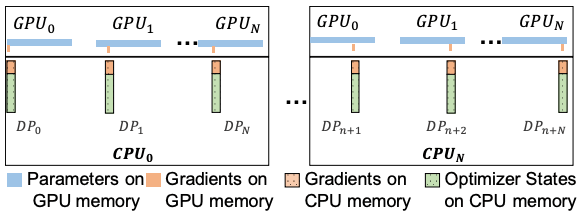 ZeRO-Offloadは、ZeROと連携して複数のGPUに対応できるようにしています。具体的には、GPU間で勾配とオプティマイザの状態を分割するZeRO-2を使用しています。各GPUはパラメータのコピーを保持しますが、パラメータの一部を更新する必要があります。そのため、パラメータのその部分の勾配とオプティマイザの状態のみを保持します。Forward passの後、各GPUは指定されたパラメータをミニバッチで更新します(各GPUは異なるミニバッチを取得します)。そして全GPUからの更新されたパラメータは、all-gather通信の集合体を用いて収集され、結合され、再分配されます。
ZeRO-Offloadは、ZeROと連携して複数のGPUに対応できるようにしています。具体的には、GPU間で勾配とオプティマイザの状態を分割するZeRO-2を使用しています。各GPUはパラメータのコピーを保持しますが、パラメータの一部を更新する必要があります。そのため、パラメータのその部分の勾配とオプティマイザの状態のみを保持します。Forward passの後、各GPUは指定されたパラメータをミニバッチで更新します(各GPUは異なるミニバッチを取得します)。そして全GPUからの更新されたパラメータは、all-gather通信の集合体を用いて収集され、結合され、再分配されます。
最適化されたCPU実行
また、CPUでのデータ処理の並列化による高速なCPU Adamオプティマイザを紹介します。最適化されたAdamは、ハードウェア並列化にSIMDベクトル命令、命令レベルの並列化にLoop unrolling、複数のコアやスレッドを活用するためのOMPマルチスレッドを使用しています。
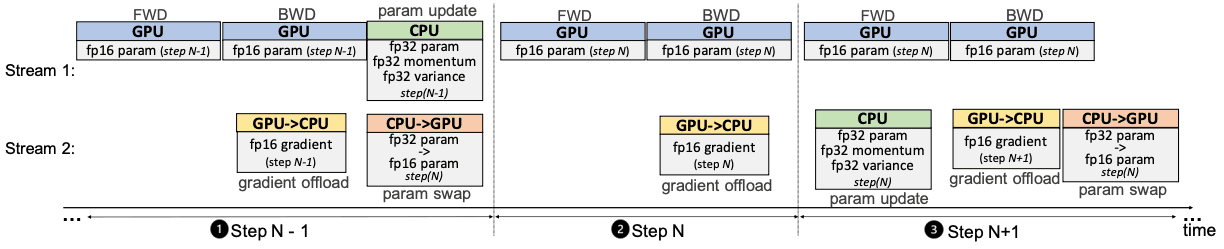 最適化されたAdamにもかかわらず、バッチサイズが小さい場合にはCPUの計算負荷がGPUの負荷に近づく可能性があります。このような場合には、1ステップの遅延パラメータ更新(DPU)を用いて、GPUとCPUを1ステップだけオーバーラップさせます。DPUでは、勾配が急激に変化するため、初期のN-1ステップはスキップされます。これにより、GPUとCPUを同時に動作させることが可能となるのです。数十回の繰り返しの後にDPUを使用してもモデルの精度に大きな影響を与えないことがわかっています。
最適化されたAdamにもかかわらず、バッチサイズが小さい場合にはCPUの計算負荷がGPUの負荷に近づく可能性があります。このような場合には、1ステップの遅延パラメータ更新(DPU)を用いて、GPUとCPUを1ステップだけオーバーラップさせます。DPUでは、勾配が急激に変化するため、初期のN-1ステップはスキップされます。これにより、GPUとCPUを同時に動作させることが可能となるのです。数十回の繰り返しの後にDPUを使用してもモデルの精度に大きな影響を与えないことがわかっています。
実験と評価

ZeRO-Offloadは、学習スループット、最大モデルサイズの点でPytorch、Megator、Zero-2、L2Lよりも有意に優れています。さらに、DPUは8個の小さいバッチサイズでGPUあたりのスループットを向上させることが示されています。
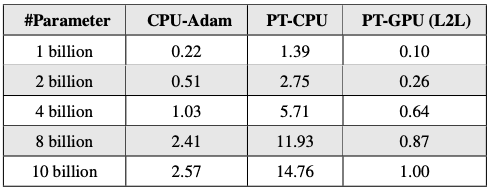
PyTorch(PT)とCPU-AdamのためのAdam Latency
CPU-Adamは、デフォルトのPyTorch AdamのCPU上での実装よりも大幅に性能が向上しています(最大6倍)。PyTorch-GPU Adamは高速ですが、その代わりにGPUメモリの一部を消費します(望ましくないトレードオフ)。
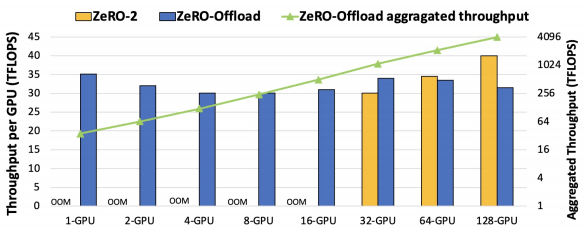
10BパラメータGPT-2のZeRO-OffloadとZeRO-2の間の学習スループット
ZeRO-OffloadはGPU数が増えてもGPUあたりのスループットを維持しています(最大128GPU)。また、GPU数が増えてもZeRO-2がZeRO-Offloadを上回ることも確認されています。
まとめ
実験結果が物語っているように、ZeRO-Offloadの素晴らしさについては、ほとんど語る必要はないと思います。この論文では、ディープニューラルネットワークを効率的に学習するために工夫されたアイデアが搭載されています。そうすることで、世界中の何千人もの熱狂的な研究者が数十億パラメータのモデルの学習にアクセスできるようになりました。オープンソース化されており、DeepSpeedライブラリに含まれているので、簡単にプロジェクトに組み込むことができます。このシステムについての詳細な情報を得るためには、元の論文に目を通すことをお勧めします。こちらがDeepSpeedのGitHubリポジトリです。





この記事に関するカテゴリー






