【Qwen2.5-Coder】コード生成や補完、数学の推論タスクに特化したLLM
3つの要点
✔️ Qwen2.5-Coderは、コード生成や補完、数学の推論タスクに特化したLLM
✔️ 5.5兆トークン以上の大規模データで学習され、Fill-in-the-Middleなどの手法で部分的なコード欠損を補完可能
✔️ 複数のプログラミング言語や長いコンテキストにも対応し、数学的推論にも優れた性能
Qwen2.5-Coder Technical Report
written by Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, Junyang Lin
(Submitted on 18 Sep 2024)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
この論文は、Qwen2.5-Coderという新しいコード生成に特化した大規模言語モデルについて述べています。
Qwen2.5-Coderは、前身であるCodeQwen1.5から大きく進化しており、特にコード生成やコード修正といったプログラミング関連のタスクで優れた性能を発揮するよう設計されています。このシリーズには、1.5B(15億)と7B(70億)パラメータの2つのモデルが含まれています。
提案手法
Qwen2.5-Coderは、コード生成に特化した大規模言語モデルで、「Qwen2.5」のアーキテクチャをベースに、5.5兆トークン以上の大規模なデータセットで事前学習されています。
このモデルの中心的な特徴は、コードの生成、推論、編集といった幅広いプログラミング関連のタスクに対応できる点です。例えば、HumanEvalやMBPPといったベンチマークでは、他の大規模モデルに対して優れた性能を示し、特にPythonをはじめとする複数のプログラミング言語で高い汎用性を発揮しています。さらに、Fill-in-the-Middle(FIM)と呼ばれる手法を導入することで、コードの一部が欠けた状況でも補完して生成する能力を持っています。これにより、欠損したコード部分の予測や編集が可能になります。
Qwen2.5-Coderは、ファイル単位およびリポジトリ単位での事前学習を行い、長いコードやリポジトリ全体を対象とする際にも効率的に動作します。特にリポジトリ全体を扱うために、トークンの最大処理長を32,768トークンまで拡張しており、従来モデルよりも大規模なコンテキスト処理が可能です。また、数学的な問題にも対応するため、数式データも学習に取り入れられており、コード生成に加えて数学的な推論にも優れています。
実験
実験では、Qwen2.5-Coderの性能を検証するために設計されており、複数のベンチマークを通じて行われました。特に、コード生成やコード推論、編集タスクの精度を評価するために、いくつかの重要なデータセットを使用して評価されています。
まず、コード生成の性能は「HumanEval」や「MBPP」といったベンチマークで評価されています。HumanEvalは、Pythonのプログラミングタスクに基づいたもので、164の問題が用意されており、各問題は関数のシグネチャと説明が与えられます。MBPPはより多様な問題を提供し、974の問題を持ち、複数のテストケースでモデルの性能を確認します。これらのベンチマークでQwen2.5-Coderは、特に7Bモデルにおいて他のモデルよりも高い精度を達成しています。例えば、HumanEvalでのスコアは61.6%に達しており、これは同規模の他のモデルと比べても非常に優れた結果です。
次に、コード補完の能力についても検証されています。ここでは、Fill-in-the-Middle(FIM)という技術が活用されています。FIMは、コードの一部が欠落した際に、その欠落部分をモデルが補完する能力を評価する手法です。この評価では、Qwen2.5-Coderは、複数のプログラミング言語(Python、Java、JavaScript)において、高い精度で欠落部分を予測し、他の大規模モデルと比較しても優れた結果を示しています。
また、コード推論の評価も行われています。ここでは、「CRUXEval」というベンチマークを用いて、モデルが与えられたコードの出力や入力を正確に予測できるかが検証されています。特に、コードの実行結果を予測する「Input-CoT」タスクと、出力からコードの入力を予測する「Output-CoT」タスクが行われ、Qwen2.5-Coderは他の同規模のモデルに比べて優れた結果を示しました。
最後に、数学的推論の能力も評価されています。ここでは、MATHやGSM8Kといった数学的な問題を含むデータセットが使用され、Qwen2.5-Coderがコード生成にとどまらず、数学的な問題の解決にも強力であることが確認されています。7Bモデルは、GSM8Kで83.9%という非常に高い精度を示しています。
これらの結果から、Qwen2.5-Coderはコード生成や補完、推論だけでなく、数学的な問題解決にも優れた能力を持っており、幅広いタスクに対して高い性能を発揮することが実証されています。
図表の解説
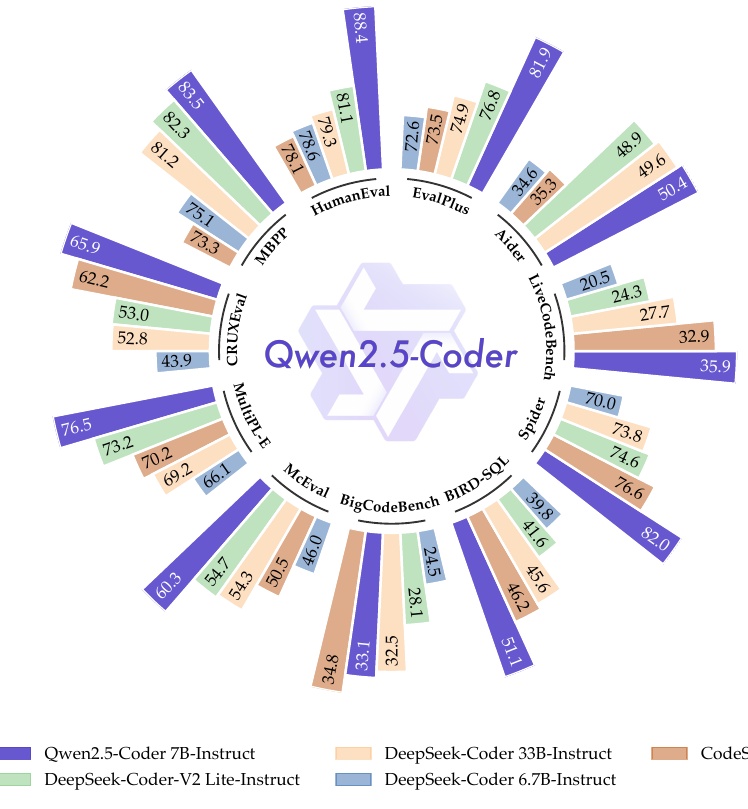
この図は、Qwen2.5-Coderというモデルのさまざまな評価ベンチマークにおける性能を示しています。図の中央にQwen2.5-Coderがあり、それを取り囲むようにして異なるテストの結果が円形に配置されています。各テストは、Qwen2.5-Coderと他のモデルの性能を比較しています。
具体的には、Qwen2.5-Coder 7B-Instructは青紫色で示され、ほかの評価にはDeepSeek-CoderやCodeStralなどの異なるモデルも含まれています。測定されたベンチマークには、HumanEval、MBPP、CRUXEval、MultiPL-E、及びLiveCodeBenchなどがあり、それぞれプログラミングタスクに関する多様な能力を測定しています。
数値は、それぞれのモデルが各ベンチマークで達成したスコアを示しており、Qwen2.5-Coder 7B-Instructが多くの評価で高い性能を示していることが確認できます。例えば、HumanEvalでは84.1という高いスコアを持っており、全体的に優れた能力を発揮していることがわかります。
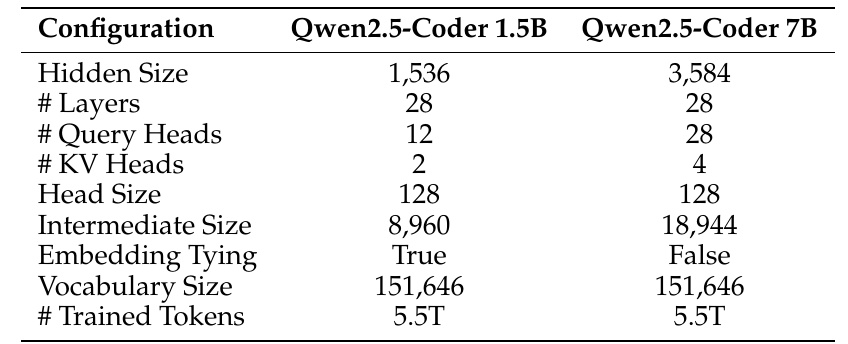
この表はQwen2.5-Coderというモデルの構成を示しています。同じQwen2.5-Coderシリーズに属する2種類のモデル、1.5Bと7Bの比較がされています。
- 隠れ層のサイズ(Hidden Size)ですが、1.5Bモデルは1,536、7Bモデルは3,584となっています。この数値が大きいほど、より複雑なパターンを学習できる可能性があります。
- レイヤーの数(# Layers)は両方のモデルで共に28です。一般的に、この数が多いとモデルの表現力が向上しますが、計算量も増加します。
- また、クエリヘッド(# Query Heads)は、1.5Bモデルが12に対し、7Bモデルは28です。キー・バリューヘッド(# KV Heads)は1.5Bモデルで2、7Bモデルで4となっており、トランスフォーマーモデルの注意メカニズムに関連しています。
- ヘッドサイズ(Head Size)は128で両モデル共通です。
- 中間層のサイズ(Intermediate Size)も示されています。1.5Bモデルでは8,960、7Bモデルでは18,944になっています。この違いは、モデルが情報を処理する過程で現れます。
- Embedding Tyingは1.5Bモデルが「True」、7Bモデルが「False」となっています。これは、単語の埋め込み層と出力層で同じ行列を共有するか否かを示しています。
- 単語の語彙サイズ(Vocabulary Size)は、両モデル共に151,646語で統一されています。
- 学習に用いたトークン数(# Trained Tokens)は、どちらのモデルも5.5兆トークンであり、膨大なデータを用いてトレーニングされていることがわかります。

この図表は、Qwen2.5-Coderというモデルが扱う特別なトークンの情報を示しています。モデルはコードを理解しやすくするため、特定のトークンを使います。
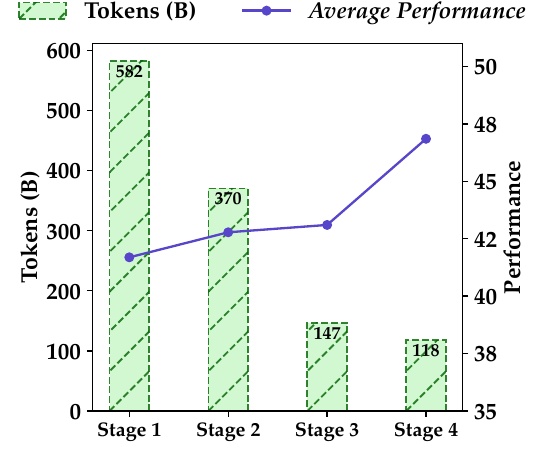
この図は、Qwen2.5-Coderにおけるデータフィルタリングのステージごとのトークン数とモデルの平均パフォーマンスの関係を示しています。
まず、トークン数の増減についてですが、ステージ1では582億トークンが使用されています。一方で、ステージ2では370億トークンに減少し、さらにステージ3とステージ4ではそれぞれ147億と118億トークンとなっており、データが精選されていることを示しています。
次に、パフォーマンスの変化に注目します。ステージ1からステージ4にかけて、モデルの平均パフォーマンスは41.6から46.8に向上しています。これは、データがフィルタリングされ、より質の高いデータが使用されることで、モデルの性能が向上したことを意味しています。

この図は、Qwen2.5というモデルがどのように開発され、どのようなステージを経て最終形になったかを示しています。
まず最初に、Qwen2.5モデルは大規模なデータセットを使って事前学習されます。このステップは「File-Level Pretrain」と呼ばれ、5.2兆(5.2T)ものトークンを使っています。ここでは個々のコードファイルから学習することで、基本的な知識を身につけます。
次に、「Repo-Level Pretrain」というステージが行われます。ここでは、さらに3000億(300B)のトークンを使って、リポジトリ全体からの情報を学習します。このプロセスによって、より大規模で複雑なコードの文脈を理解できる力を強化します。
それから、「Qwen2.5-Code-Base」という段階に進みます。ここでのモデルは、学んだ内容を基にして、さらに洗練されたコード生成能力を持つようになります。
最後に、「Code SFT」というステップでモデルは微調整され、最終的な形である「Qwen2.5-Code-Instruct」としてリリースされます。この段階のモデルは、特定のコードタスクに対する柔軟な対応力が求められ、実用化を視野に入れた形となっています。
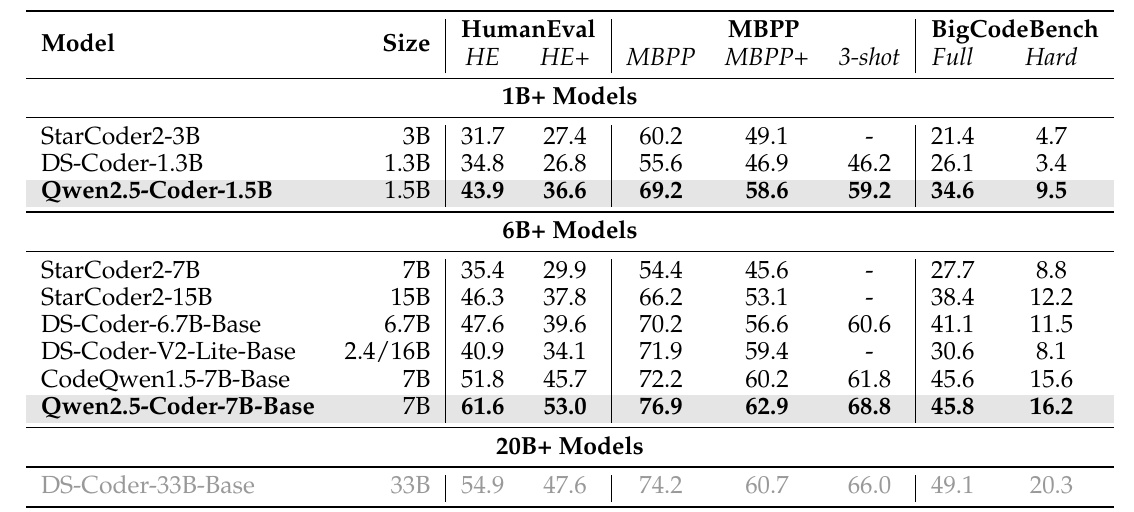
この図表は、異なるモデルがいくつかの評価基準でどのようにパフォーマンスを発揮したかを示しています。それぞれのモデルは、「HumanEval」と「MBPP」、そして「BigCodeBench」と呼ばれるベンチマークで評価されています。
まず、「Model」列には、評価されたモデルの種類がリストされています。例えば、「Qwen2.5-Coder-1.5B」や「StarCoder2-7B」などがあります。それらのモデルは、異なるパラメータサイズのバリエーションを持ちます。
次に、「Size」列には、モデルのパラメータ数が記載されており、これがモデルの「賢さ」や処理能力に関連しています。たとえば、「3B」は30億のパラメータを持つことを意味します。
それから、「HumanEval」と「MBPP」というのは、プログラミングタスクの生成能力を評価するためのベンチマークです。「HE」や「HE+」は、その具体的な評価尺度の名前で、「MBPP+ 3-shot」も同様に評価尺度を表しています。
そして、「BigCodeBench」は、特に「Full」と「Hard」の2つの難易度で、さらに異なった基準で評価しています。
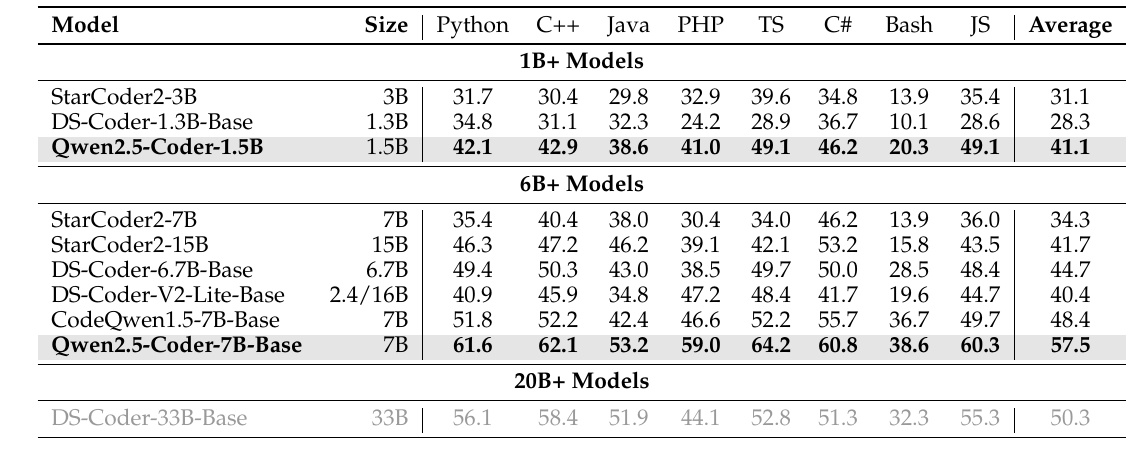
この図は、Qwen2.5-Coderというコード生成モデルの性能を、他のモデルと比較したものです。それぞれのモデルは、異なるプログラミング言語での性能を示しています。
まず、モデルの「サイズ」は、モデルのパラメータ数を示しており、例えば「1.5B」は15億のパラメータを持つことを意味します。表の左側にはモデル名が並んでおり、その右側に各言語(Python, C++, Java, など)でのスコアが示されています。このスコアは、それぞれの言語におけるモデルの性能を反映しています。
Qwen2.5-Coder-1.5Bは他の1Bサイズのモデルを上回る性能を示しており、平均スコアで41.1を獲得しています。特にPythonやC#などの言語で優れた結果を出しています。さらに、Qwen2.5-Coder-7B-Baseは、7Bサイズの中でトップのスコア57.5を記録し、様々な言語において高い性能を誇っています。
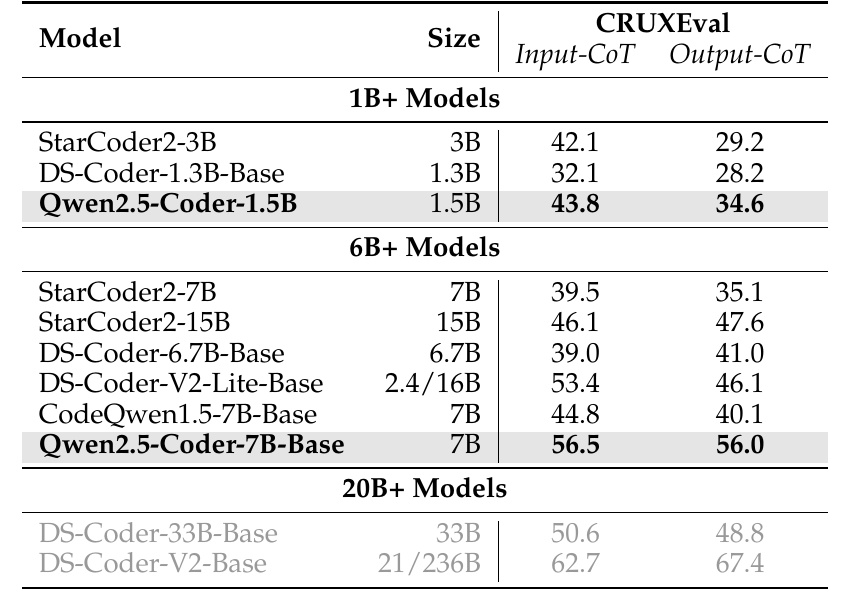
この図は、さまざまなモデルのCRUXEvalにおけるパフォーマンスを示しています。CRUXEvalとは、モデルがコードを入力として受け取った場合(Input-CoT)および出力として扱った場合(Output-CoT)でどのように推論を行うかを評価する基準です。まず、モデルのサイズを示す列があり、1B(10億)から20B(200億)以上のパラメータを持つモデルが列挙されています。
1B+ モデルとしては、StarCoder2-3B、DS-Coder-1.3B-Base、Qwen2.5-Coder-1.5Bがあります。Qwen2.5-Coder-1.5Bは、特に優れた性能を示しており、それぞれ43.8と34.6のスコアを達成しています。
6B+ モデルでは、Qwen2.5-Coder-7B-Baseが高い性能を示しており、56.5と56.0のスコアを記録しています。他のモデルと比較しても高い数値であることが分かります。
20B+ モデルでは、さらに大規模なモデルがリストされていますが、この表ではコンテキストにおいて直接比較は行われていません。
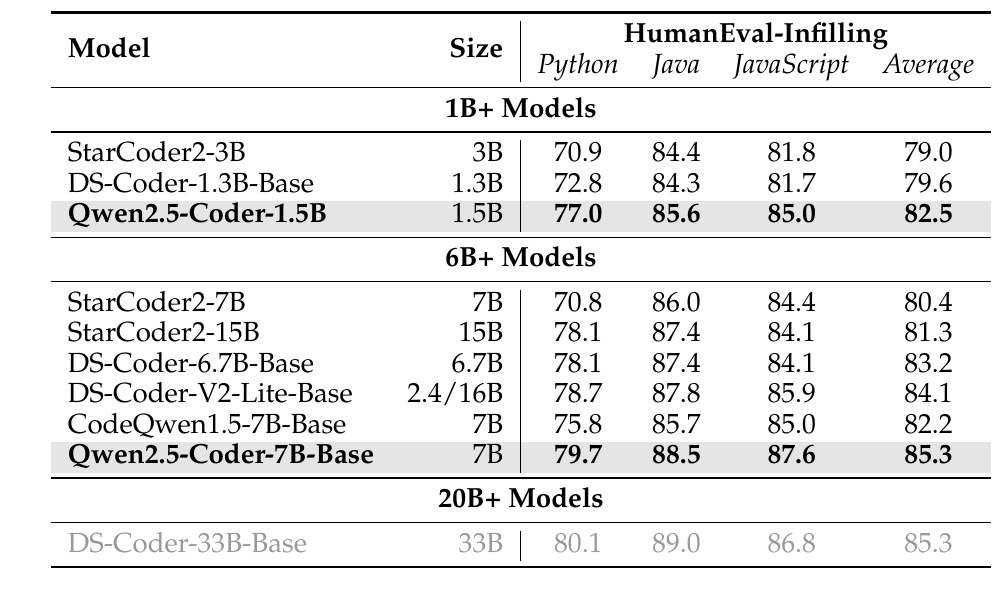
この表は、さまざまなモデルがコード補完タスクでどの程度の性能を持つかを示しています。具体的には、Python、Java、JavaScriptの3つのプログラミング言語におけるHumanEval-Infillingタスクでの評価結果が記載されています。この評価はモデルがどれだけ正確にコードの間を埋められるかを示しています。
1B+と6B+、20B+といった異なるモデルサイズのカテゴリーが分けられており、それぞれのカテゴリ内でモデル名とサイズ、言語ごとのスコア、そして平均スコアが示されています。1B+モデルにはStarCoder2-3B、DS-Coder-1.3B-Base、Qwen2.5-Coder-1.5Bが含まれ、6B+モデルにはStarCoder2-7BやCodeQwen1.5-7B-Baseなどが含まれています。
Qwen2.5-Coder-7B-Baseは、6B+モデルの中で最も高いスコアを記録しています。特にJavaでは88.5の高スコアを達成しており、他の言語でも優れた成績を収めています。
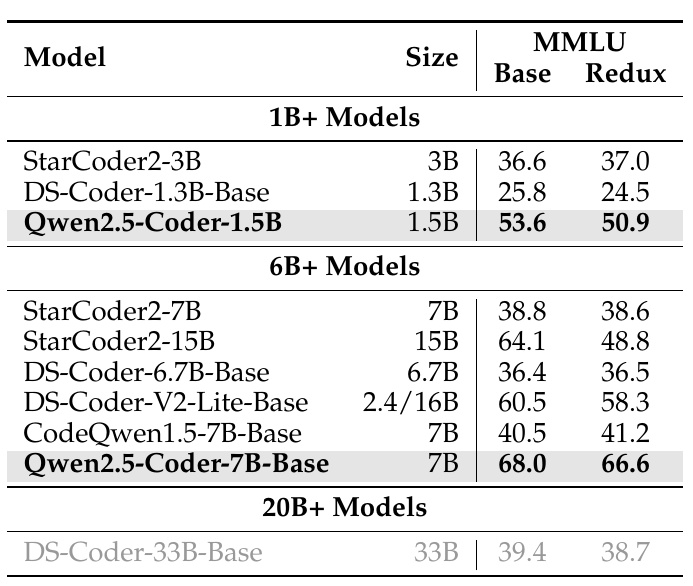
この表は、異なるコード生成モデルの性能を、MMLU BaseとMMLU Reduxという2つの基準で比較したものです。サイズの異なるモデルについて、その評価結果が示されています。
まず、1B+モデルの部では、Qwen2.5-Coder-1.5Bが他のモデルと比べて高いスコアを示しています。このモデルは、MMLU Baseで53.6、Reduxで50.9のスコアを獲得しています。このパフォーマンスは、他の1B+モデルより優れています。
次に、6B+モデルの部では、Qwen2.5-Coder-7B-Baseが際立った性能を示しており、MMLU Baseで68.0、Reduxで66.6という非常に優秀なスコアを記録しています。このことは、他の6B+モデルと比べても優れた結果です。
一方、20B+モデルとして取り上げられているDS-Coder-33B-Baseは、33Bという大きなサイズにもかかわらず、39.4 (Base) と38.7 (Redux) と比較的控えめな結果となっています。
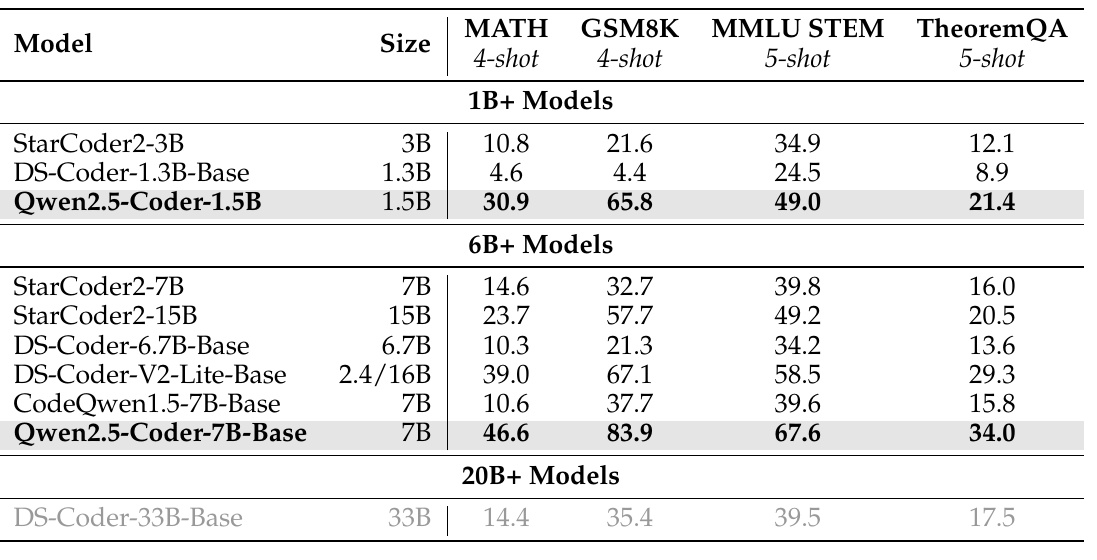
この表は、異なるモデルが4つの数学関連ベンチマークに対してどのようなパフォーマンスを示すかを比較しています。具体的なベンチマークは「MATH」「GSM8K」「MMLU STEM」「TheoremQA」で、各モデルがそれぞれのベンチマークでどれくらいの精度(スコア)を達成しているかが示されています。
まず、表の上部では1B台のモデルを見てみましょう。「Qwen2.5-Coder-1.5B」が他の「StarCoder2-3B」や「DS-Coder-1.3B-Base」をしのぐパフォーマンスを見せています。特に「GSM8K」のベンチマークでは65.8という高いスコアを達成しています。
次に、6B台のモデルを見ると、「Qwen2.5-Coder-7B-Base」は他の同程度のサイズのモデルと比較しても優れたパフォーマンスを示しています。特に「GSM8K」では83.9、「MMLU STEM」では67.6を達成し、他のモデルを上回っています。
最後に、20B台のモデルである「DS-Coder-33B-Base」と比較しても、「Qwen2.5-Coder-7B-Base」が多くのベンチマークで競争力のあるパフォーマンスを示していることがわかります。
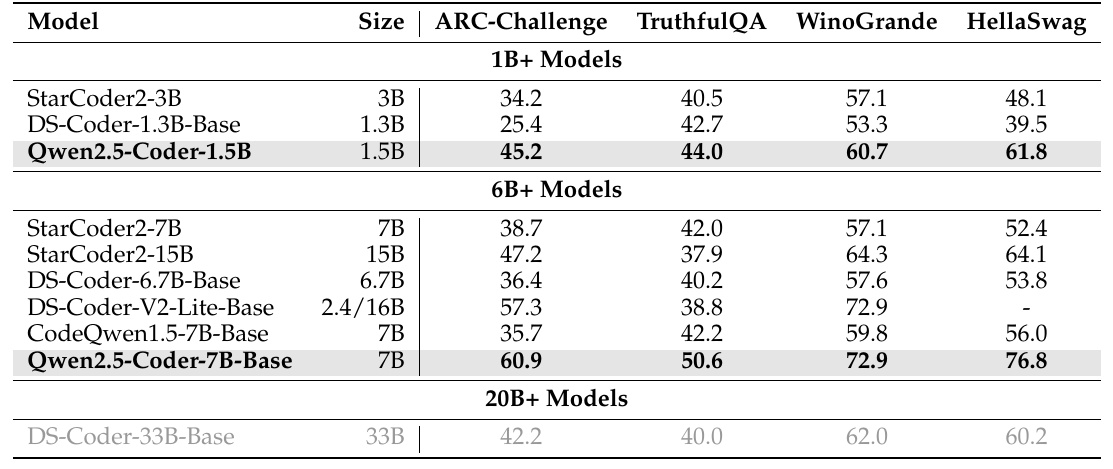
この図は、機械学習モデルの比較を示しています。具体的には、Qwen2.5-Coderシリーズや他のモデルが、さまざまなベンチマークに対してどれだけの性能を発揮するかを評価しています。ベンチマークには、「ARC-Challenge」「TruthfulQA」「WinoGrande」「HellaSwag」が含まれています。
Qwen2.5-Coder-1.5Bは、1.5Bのモデルサイズにもかかわらず、特に「ARC-Challenge」と「TruthfulQA」で高いスコアを記録しています。「ARC-Challenge」では45.2、「TruthfulQA」では44.0です。
さらに、7Bのサイズを持つQwen2.5-Coder-7B-Baseも目立っています。「ARC-Challenge」で60.9、「TruthfulQA」で50.6、「WinoGrande」で72.9、「HellaSwag」で76.8という非常に高いスコアを示しています。他のサイズが大きい20B以上のモデル、例えばDS-Coder-33B-Baseに対しても、競争力のある性能を示しています。
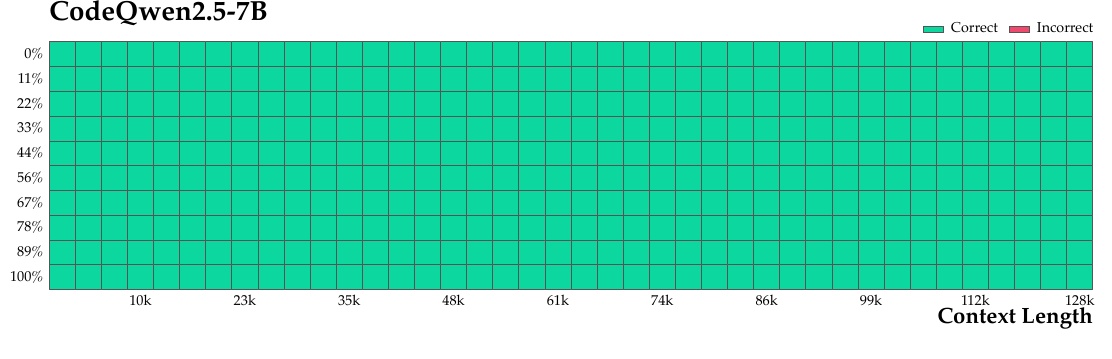
この図は「CodeQwen2.5-7B」というモデルの性能を示しています。見ていただくと、縦軸には「正解の割合」として示され、横軸は「文脈の長さ」を示すメートルになっています。
ここでは、何らかのタスクにおけるモデルの正確性を、文脈の長さが10kから128kまでの範囲で評価しています。グラフは、緑色が「Correct(正解)」を示し、赤色が「Incorrect(誤答)」を示しています。
全体的に見て、図ではすべての部分が緑色で塗られていて、赤色はまったく見えません。このことは、この特定のタスクにおいて、CodeQwen2.5-7Bがさまざまな文脈の長さに対応し、非常に高い正確性を持っていることを示しています。
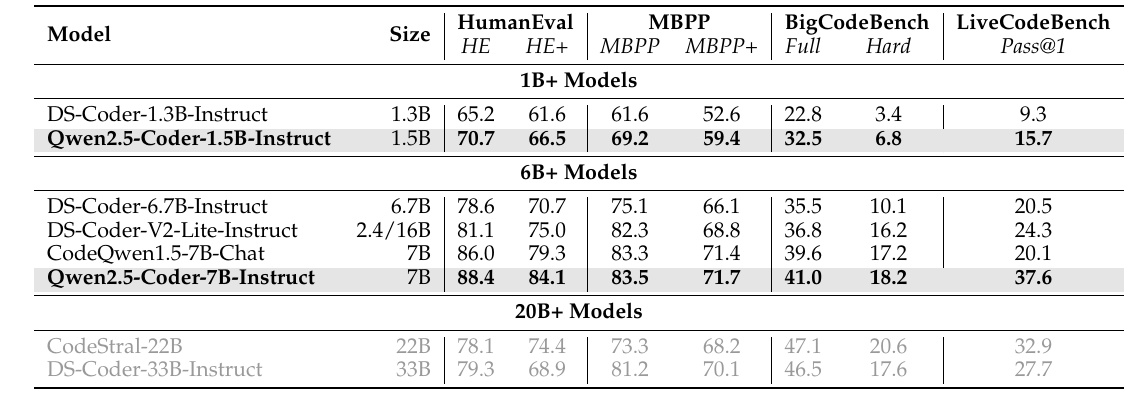
この図表は、異なるモデルがさまざまなコード生成に関連するベンチマーク試験でどのような性能を発揮するかを比較しています。具体的には、Qwen2.5-Coderシリーズの性能が強調されています。表の列では、モデル名とサイズ(モデルに含まれるパラメーターの数)が示されています。
HumanEvalとMBPPは、コード生成能力をテストする指標です。Qwen2.5-Coder-7B-Instructモデルは、これらのテストで他のモデルよりも高スコアを記録しています。具体的には、HumanEvalおよびMBPPで80%を超える高い数値を示し、特にHumanEval+とMBPP+では、他の同規模モデルより優れています。
BigCodeBenchは、より複雑なコード生成タスクへの対応能力を評価します。ここでも、Qwen2.5-Coder-7B-Instructモデルは、他の6Bクラスのモデルを上回る性能を発揮しています。
LiveCodeBenchは、最新のコーディング問題への対応力を測定します。このベンチマークでも、Qwen2.5-Coder-7B-Instructは際立ったパフォーマンスを示し、37.6%のPass@1を記録しています。これは、モデルが与えられたタスクを最初の試行でどれほど成功するかを意味します。
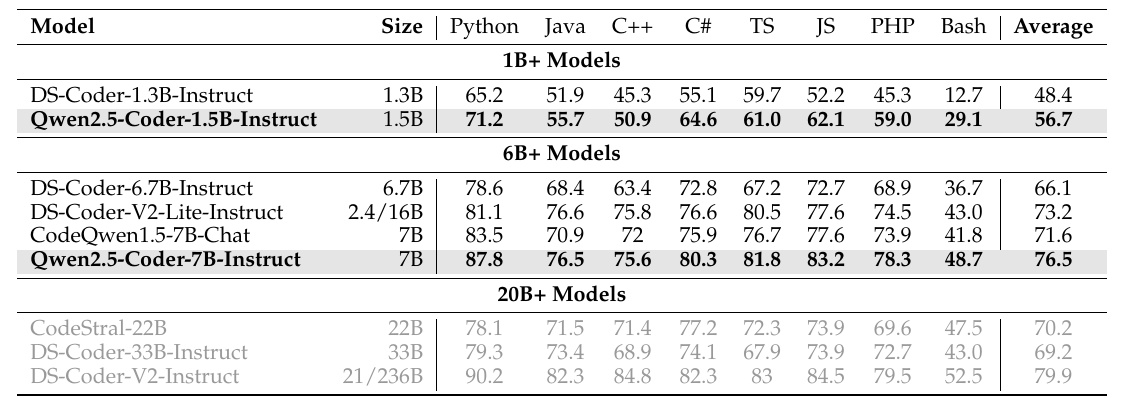
この表は、さまざまなプログラミング言語に対するモデルのパフォーマンスを示しています。モデルは異なるサイズで、その性能が評価されています。たとえば、1.5BサイズのQwen2.5-Coder-1.5B-Instructは、Python、Java、C++など、特定の言語でかなり高いスコアを記録しています。
モデルは、1B+、6B+、20B+のグループに分類されています。それぞれのグループには異なるサイズのモデルが含まれており、それらがいかに異なる言語でパフォーマンスを発揮するかが比較されています。
Qwen2.5-Coder-7B-Instructというモデルが複数の言語で優れた結果を示しており、特にPythonやJava、C++などの主要なプログラミング言語で高い精度を記録しています。このモデルは平均でも他の多くのモデルを上回る76.5のスコアを得ており、非常に強力であることがわかります。
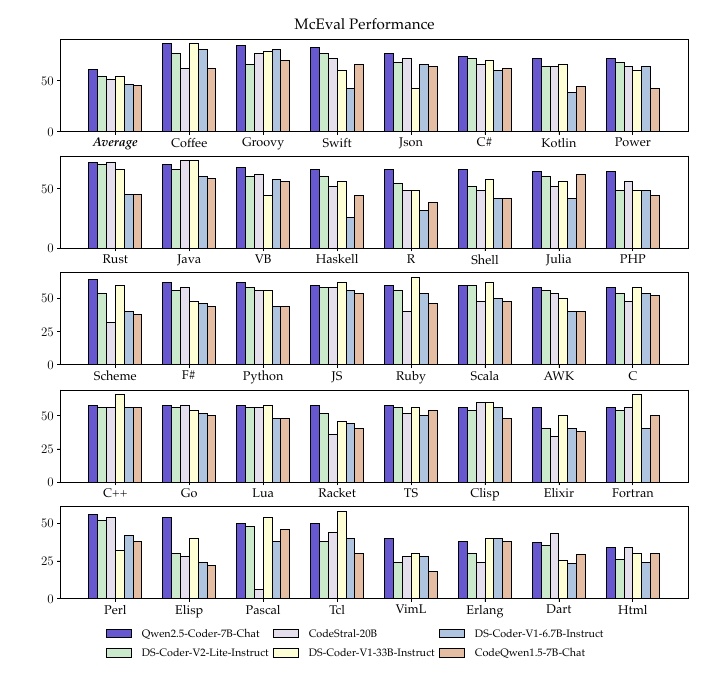
このグラフは、McEvalという評価基準に基づいたプログラミング言語の性能を比較しています。具体的には、様々なコードモデルのパフォーマンスを異なるプログラミング言語ごとに計測しており、それを棒グラフで視覚的に表現しています。
各言語に対して異なるモデルのパフォーマンスが示されており、具体的にはQwen2.5-Coder-7B-Chat、CodeStral-20B、DS-Coder-V2-Lite-Instructなどのモデルが比較されています。グラフの縦軸はパフォーマンススコアを表しており、数字が大きいほど性能が良いことを示しています。
表示されているプログラミング言語には、PythonやJavaScript、C#、Javaといった主要な言語から、PerlやFortranといった少々ニッチな言語まで含まれています。各モデルの色分けは凡例に示されており、それぞれのモデルがどの言語でどの程度の性能を発揮したかが一目でわかるようになっています。
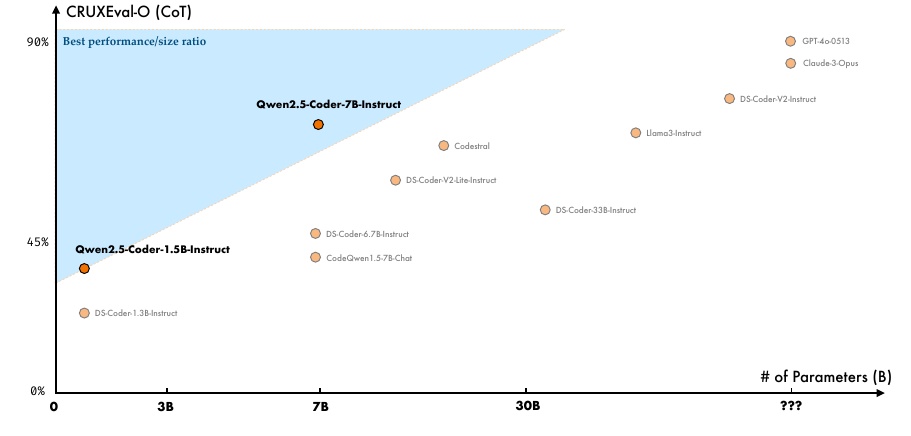
この図は、CRUXEval-O (CoT) スコアとモデルのパラメータ数の関係を示しています。縦軸にはCRUXEval-O (CoT)のスコア、つまりコード推論能力の評価が示されており、スコアが高いほど優れた性能を示しています。横軸はモデルのパラメータ数を表しており、右に行くほど大きなモデルを示しています。
図の左側には、パフォーマンスとサイズの比で優れたモデルとしてQwen2.5-Coderシリーズが示されています。特にQwen2.5-Coder-7B-Instructは、他のモデルと比較して小さいパラメータ数ながらも、高いスコアを達成していることがわかります。これは、多くのパラメータを持つ他の大規模モデルよりも効率が良いことを示しています。
背景が青色で塗られている部分は、最も効率的なパフォーマンスとサイズの比を達成する領域です。この中にQwen2.5-Coderシリーズが位置しているため、効率の良いモデル設計といえます。

この図表は、Qwen2.5-Coder-7B-InstructというモデルとDS-Coder-V2-Lite-Instructという別のモデルのパフォーマンスを比較したものです。それぞれのモデルが、異なるベンチマークでどれだけの成績を出したかを示しています。
表は二つに分かれており、上の部分ではMATHやGSM8Kなど数学や数理的なタスクでの評価スコアを示しています。Qwen2.5-Coder-7B-Instructの方が、ほぼすべてのタスクでより高いスコアを記録しています。
下の部分は、AMC23やMMLUといった一般的な知識の理解を測るベンチマークに関するスコアです。こちらでもQwen2.5-Coder-7B-Instructの方が一部の項目を除いて高い成績を収めています。
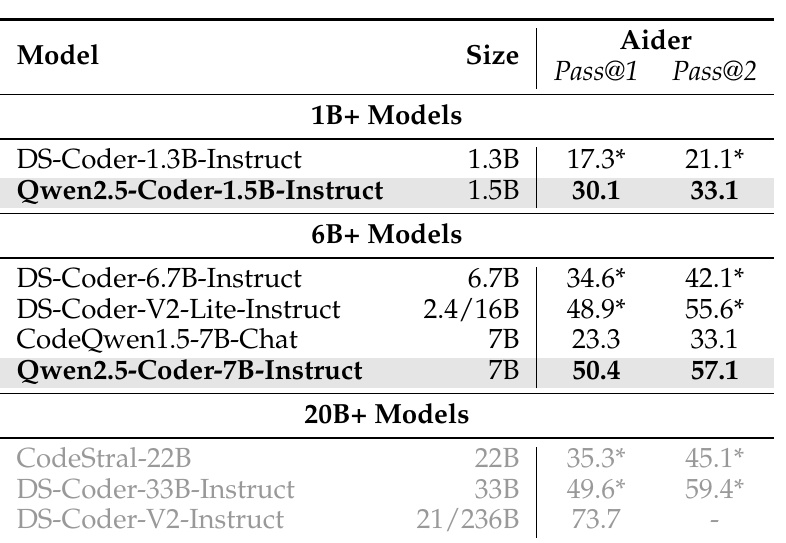
図の表は、異なるモデルのコード編集能力を測定するための結果を示しています。特に、Aiderというベンチマークを使用しています。各モデルの「Pass@1」と「Pass@2」のスコアは、最初の試行と二回目の試行でコード編集が成功した割合を示しています。
1. モデルとサイズについて
各モデルは「1B+」、「6B+」、および「20B+」というカテゴリに分類されています。これは、モデルのパラメータ数(1Bは1億以上)に基づいて規模を示しています。
「Qwen2.5-Coder-1.5B-Instruct」と「Qwen2.5-Coder-7B-Instruct」は、それぞれ1.5Bと7Bの規模であり、他のモデルと比較しています。
2. パフォーマンスの比較
「Qwen2.5-Coder-1.5B-Instruct」は、「Pass@1」で30.1、「Pass@2」で33.1というスコアを持っており、同じグループの「DS-Coder-1.3B-Instruct」と比較してパフォーマンスが向上しています。
「Qwen2.5-Coder-7B-Instruct」は「Pass@1」で50.4、「Pass@2」で57.1と非常に高いスコアを示しており、同じカテゴリのモデルを上回る性能を持っています。
3. 特筆すべき点
大規模なモデル群、例えば20B以上の「CodeStral-22B」や「DS-Coder-33B-Instruct」と比較すると、「Qwen2.5-Coder-7B-Instruct」のスコアは優れており、少ないパラメータで効率的に高いパフォーマンスを発揮していることがわかります。
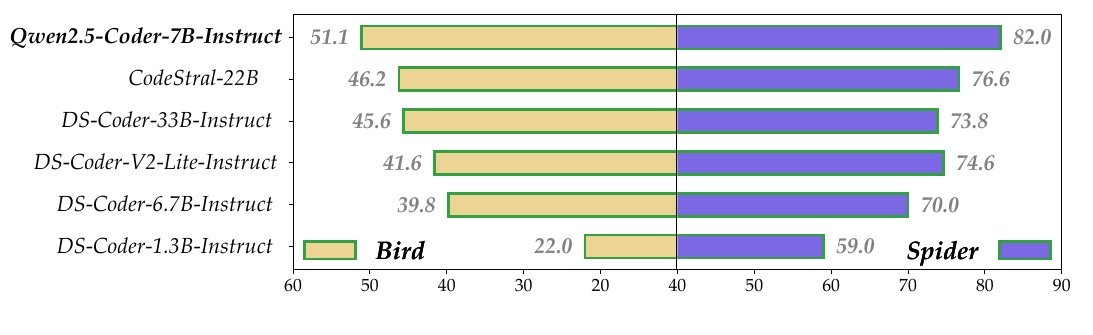
この図は、いくつかの言語モデルの「Bird」と「Spider」という二つのベンチマークにおける性能を比較しています。具体的には、Qwen2.5-Coder-7B-Instructが他のモデルと比較してどのような性能を持つかを示しています。
左側にリストされているのがそれぞれのモデルの名称です。グラフは横向きの棒グラフになっており、各モデルが「Bird」と「Spider」のベンチマークでどの程度のスコアを獲得したかを示しています。
「Bird」ベンチマークには黄色い棒グラフが使われ、そのスコアは左から右に伸びています。その数値は「51.1」から「22.0」まで存在し、Qwen2.5-Coder-7B-Instructが最も高い性能を示しています。
「Spider」ベンチマークでは紫色の棒が使われ、最も高いスコア「82.0」はQwen2.5-Coder-7B-Instructが達成しており、他のモデルより性能が抜きん出ています。
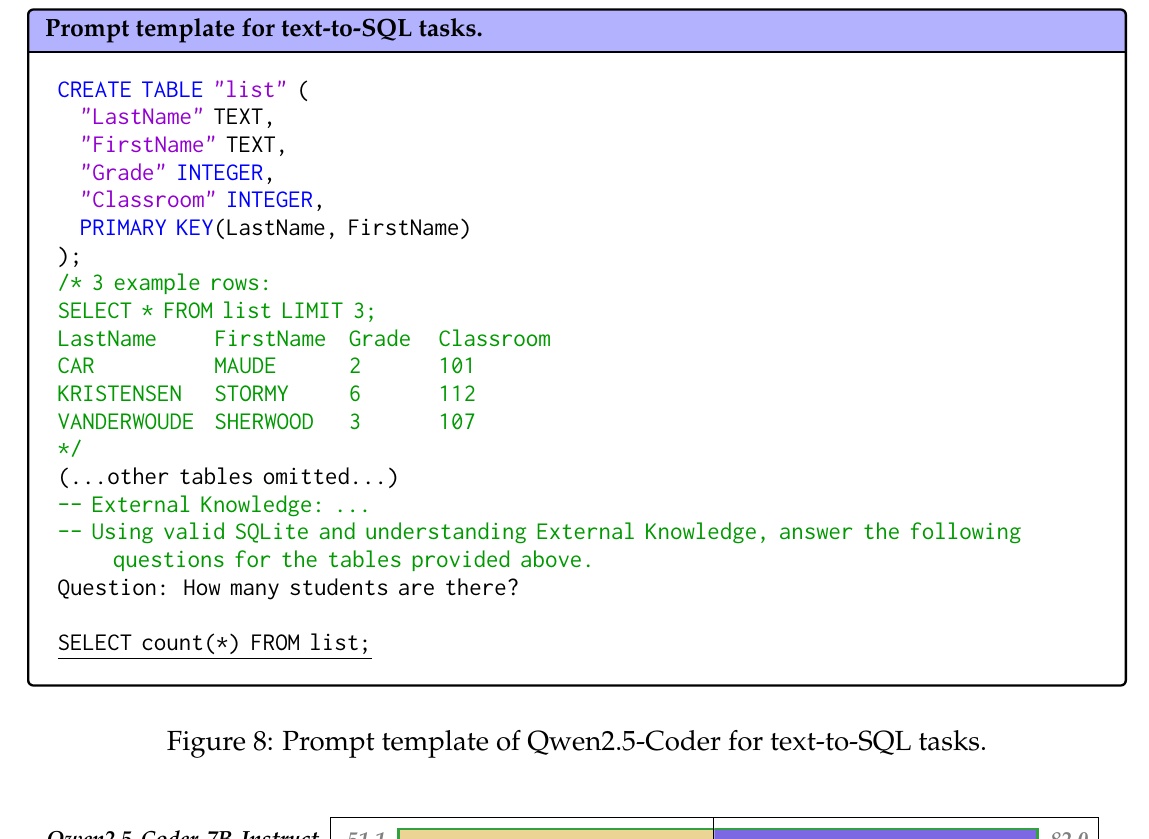
この図は、Qwen2.5-CoderがText-to-SQLタスクで使用するためのプロンプトテンプレートを示しています。SQL文を生成する際の枠組みを提供しており、特定のデータベースに対して自然言語からSQLクエリを作成する方法を理解するのに役立ちます。
まず、CREATE TABLE文により「list」というテーブルが定義されています。このテーブルは、LastName(名字)、FirstName(名前)、Grade(成績)、Classroom(教室)といった属性を持ちます。これらの属性それぞれにデータ型が設定され、PRIMARY KEYにはLastNameとFirstNameが指定されています。このキーにより、各学生が一意に識別される設計です。
次に、テーブルの例として、3つの学生のデータが提示されています。例えば、姓が「CAR」で名が「MAUDE」の生徒の例があります。これにより、ユーザーはテーブルの構造と内容を明確に理解できます。
プロンプトテンプレートは、その後に外部知識を操作に活用しつつSQLクエリを組み立てるよう誘導しています。質問として「How many students are there?」が示され、その回答としてSELECT count(*) FROM list;というクエリがSQL文で与えられています。これによって、テーブル内の生徒数が計算されます。



この記事に関するカテゴリー





