Google、エンドツーエンドで音声翻訳を直接行うシステムTranslatotronを発表
Google AIから元の音声から他言語の音声を直接生成する音声翻訳技術「Translatotron(トランスラトトロン)」が発表されました。従来モデルとは異なるエンドツーエンドモデルを採用したシステムとなっており、音声翻訳の未来を切り開く画期的なものと思われます。
【参照】Introducing Translatotron: An End-to-End Speech-to-Speech Translation Model
異なる言語間での音声 – 音声翻訳システムは、過去数十年にわたって研究されてきました。従来のシステムでは、通常、3つの別々のコンポーネントにタスクが分割されています。まず話者が話した内容が自動音声認識により文章として起こされ、そこから転写された文章をターゲット言語に翻訳し、最後に翻訳された文章からターゲット言語で音声を生成するといった形です。
このような一連のシステムにタスクを分割することは非常に成功しており、Google Translateを含む多くの商用の音声変換製品にも利用されています。
新しくgoogleから発表された論文では、変換のタスクを個別に分割することなく、代わりにある音声から別の音声への直接のマッピングを学習します。中間テキスト表現に依存することなく最初から最後まで直接音声翻訳を行う、Sequence to Sequenceに基づく新しいシステムです。
Translatotronと呼ばれるこのシステムは、カスケード式の従来のシステムと比べて、プロセスがシンプルであるがゆえに従来の方法よりも迅速な翻訳が行えます。さらに、複合エラーを自然に回避する、翻訳後の元の話者の声を保持しやすくする、翻訳する必要のない単語の処理(例:名前や固有名詞)などもより高い精度で行えるようになります。
Translatotron
音声翻訳におけるエンドツーエンドモデルの出現は、2016年から始まりました。この研究では、音声からのテキスト翻訳にSequence to Sequenceのモデルを使用することの実現可能性を実証しました。2017年には、このようなエンドツーエンドモデルが従来のカスケードモデルより優れていることが実証されました。最近ではエンドツーエンドの翻訳モデルをさらに改善するためのアプローチが多く提案されています。
Translatotronでは、一歩進んで、どちらの言語の中間テキスト表現にも頼ることなく、言語の音声を別の言語の音声に直接翻訳できることを実証しています。
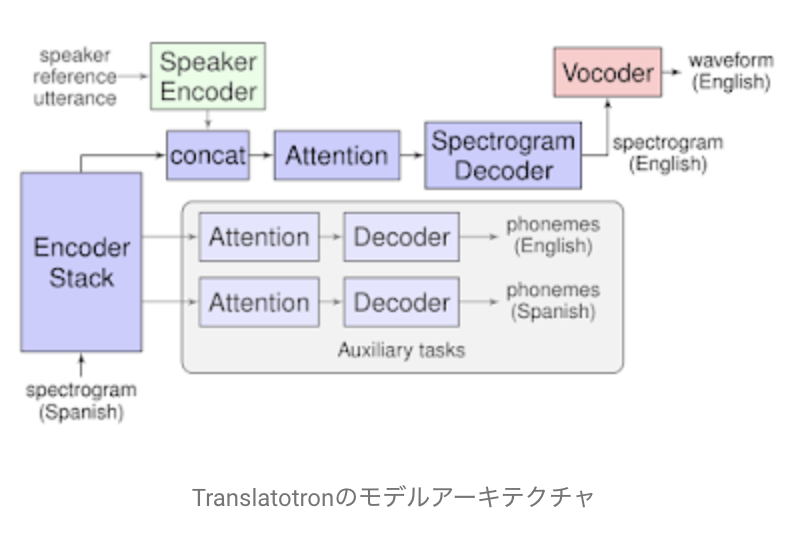
Translatotronは、ソースのスペクトログラムを入力とし、ターゲット言語で翻訳されたコンテンツのスペクトログラムを生成するSequence to Sequenceに基づいています。またこのモデルは、2つの独立したオプションのコンポーネントを採用しているのが特徴です。これらは出力を波形に変換するためのボコーダと、翻訳済み音声でも同じ音声を維持するためのスピーカーエンコーダからできており、両方の追加コンポーネントは別々にトレーニングされます。
パフォーマンス
音声認識システムによって転写されたテキストを使用して計算されたBLEUスコアを測定することによって、Translatotronの翻訳品質を検証しています。従来のカスケードシステムより少し劣りますが、エンドツーエンドの直接音声 – 音声変換の実現可能性を実証しています。
詳しくは、論文「Direct speech-to-speech translation with a sequence-to-sequence model 」においてより詳細に記述されています。
こちらのオーディオクリップでは、Translatotronを用いた翻訳とベースライン法が比較されています。



この記事に関するカテゴリー