
LONGNET:10億トークンまでのテキストを処理できるモデル
3つの要点
✔️ 長いシーケンスの効率的な処理という課題に対する重要な解決策を提示
✔️ Dilated Attentionを導入して,Transformernの計算量を削減した
✔️ LONGNETはDilated Attentionを導入したTransformerベースのモデル
LongNet: Scaling Transformers to 1,000,000,000 Tokens
written by Jiayu Ding, Shuming Ma, Li Dong, Xingxing Zhang, Shaohan Huang, Wenhui Wang, Nanning Zheng, Furu Wei
(Submitted on 5 Jul 2023 (v1), last revised 19 Jul 2023 (this version, v2))
Comments: Work in progress
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
概要
LONGNETは,Dilated Attentionという新しいアーキテクチャーを導入したTransformerのバリエーションを提案しています.Dilated AttentionはLONGNETの革新となっている技術です.
LONGNETによって,
- 旧来のTransformerではシーケンス長が長くなるにつれて必要な処理能力が急増する問題の解決
- 短いシーケンスと長いシーケンスの両方を上手く扱えるようになった
- より長いコンテキストによって言語モデルのパフォーマスが向上することがわかった
10億トークン処理できることによるメリット
10億トークンということは,GPT-4の約25万倍のトークンに相当します.これほどのトークンを処理できるモデルは今まで存在していませんでした.そのため,本全体を入れたり,web全体をモデルに入力することは困難でした.
筆者らはLONGNETによって,線型にシーケンス長をスケール方法を提案しており,将来的にwebデータセット全体を入れることができる可能性があることについても言及しています.また,LONGNETの登場によって非常に長いコンテキスト学習をできることで,多くの実例を用いたコンテキストラーニングのパラダイムシフトになる可能性についても言及しています.
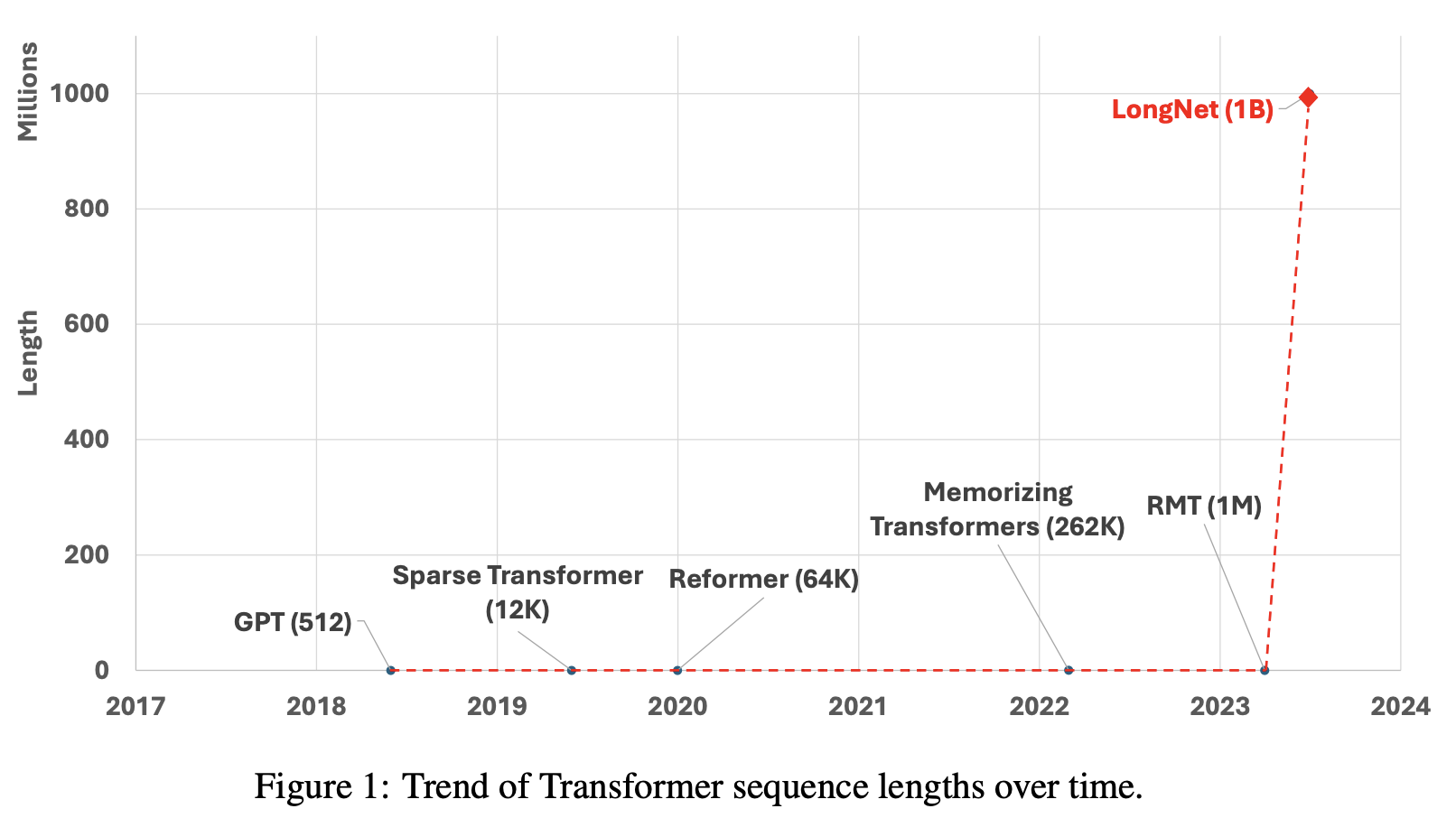
LONGNET誕生の背景
LONGNET・Dilated Attentionの登場によって,「シーケンス長の増大」と「Transformerの計算量の削減」という2つの課題のに対して,解決策が提示されました.
シーケンス長の増大によって得られるメリットは大きいことは一般に知られていましたが,Transformerでは,計算量がシーケンス長に対して2次関数となり必要な処理能力が急激に増大します.そのため.シーケンス長を増大させるためには,Transformerの計算量を削減する工夫をするのが一般的です.Transformerの計算量の削減のためにLONGNETでは,Dilated Attentionという新しいコンポーネントを導入しています.
シーケンス長の増大に伴って得られるメリット
シーケンス長はニューラルネットワークの基本的なコンポーネントであり,無制限に大きいことが望ましいと一般に考えられています.また,シーケンス長を長くすることで得られるメリットが3つあります.
- モデルが文脈を広く取り込むことができ,遠くの情報を用いて現在のトークンをより正確に予測することが可能となります.これは,話し言葉の途中から話を理解したり,長い文書の理解などに役立ちます.
- 訓練データ内のより複雑な因果関係や推論過程を含んで学習することができます.(論文中では,短い依存関係は一般的に悪影響を及ぼしやすいようです.)
- 長いコンテキストを理解できるようになり,コンテキストをフルに活用して言語モデルの出力を改善することができます.
Transformerの計算量の削減
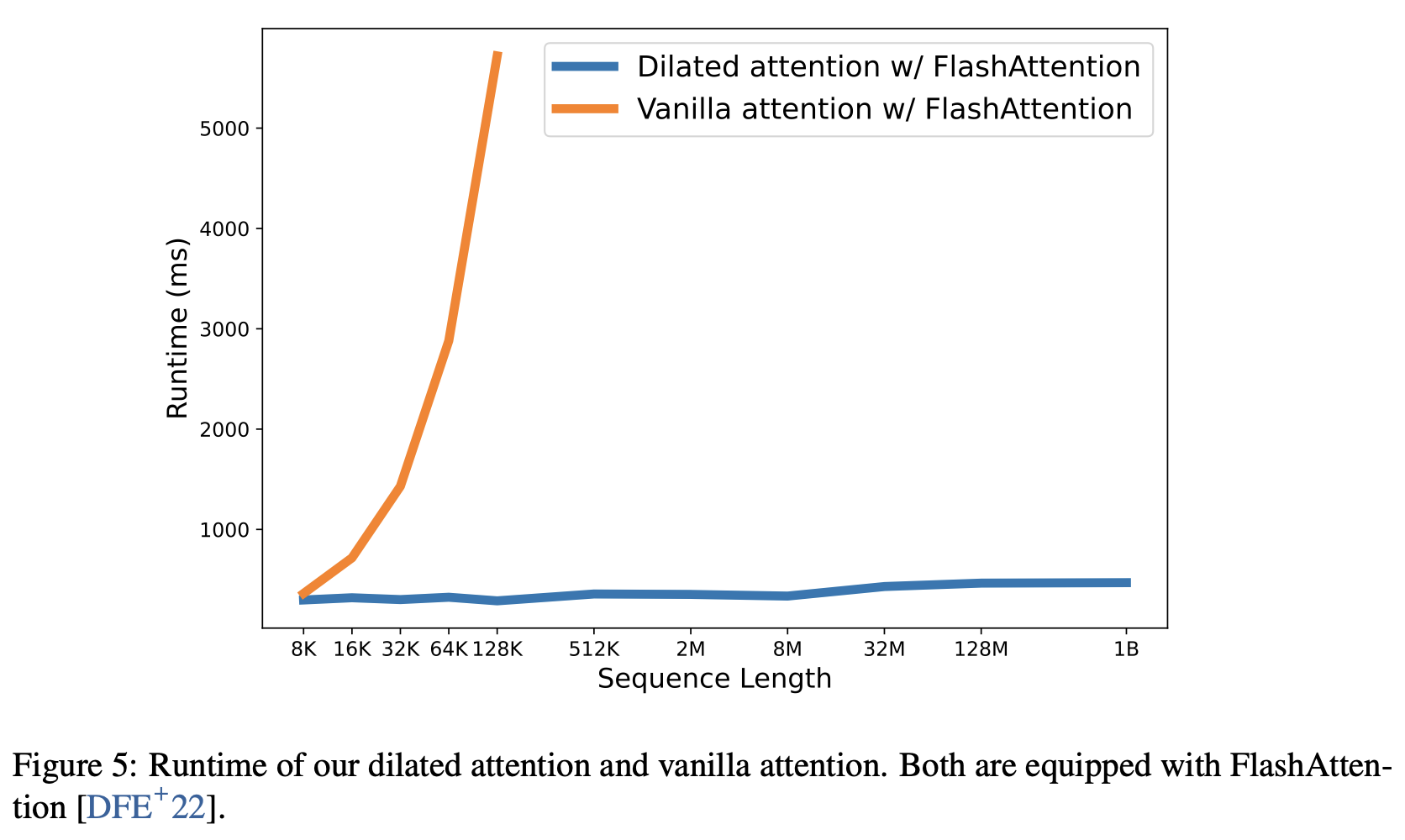
Transfomerの計算量はシーケンス長に対して2次関数的増加していきます.これに対し,本論文で提案されている,Dilated Attentionは線型に計算量が増加します.
その効果は,本論文のFigure 5で示されています.Figure 5は、vanilla attentionとdilated attentionとのパフォーマンスを比較したグラフです.シーケンスの長さ(8Kから1Bまで)を徐々にスケーリングしています.下記のグラフでは,各モデルに対して10回の異なる順伝播による平均実行時間を記録し,それらを比較しています.また,どちらもFlashAttention Kernelで実装されており,メモリの節約とスピードの向上が図られています.
dilated attentionはシーケンスの長さをスケーリングする際のレイテンシがほぼ一定であることがわかります.これにより,シーケンス長を10億トークンまでスケーリングすることが可能になります.
一方で,vanilla attentionは計算量がシーケンス長に対して2次的に増加するため,長さが増えるにつれてレイテンシが急激に増加します.さらに,vanilla attentionはシーケンス長の制限を克服するための分散アルゴリズムを持っていません.
この結果からも,LONGNETの線形複雑性と分散アルゴリズムの優位性がわかります.
既存研究と比べてどの程度計算量が改善されたのか?
先ほど計算量が劇的に改善していることを実感していただいたと思います.それでは,少し理論面から計算量がどの程度改善されたのか見ていきます.
計算量の改善は,Dilated Attentionというアーキテクチャーを採用したことで達成されました.Transformerの計算量の削減のため代表的な試みとしては.Sparse Attentionがあります.筆者らの比較によると,今回新たに提案されているDilated Attentionは下記の表のように,通常のAttentionやSparse AttentionよりもAttention機構による計算量が削減されています.

では,なぜこのように上手く計算量が削減できたのかを次では紹介します.
Dilated Attention:なぜ計算量を改善することができたのか?
Dilated Attentionでなぜ計算量が削減できたのかを数式から見ていきます.
Dilated Attentionは入力$(Q, K, V)$をセグメント${(Q, K, V)}^{\frac{N}{w}}$個に,セグメント長$w$で分割されます.
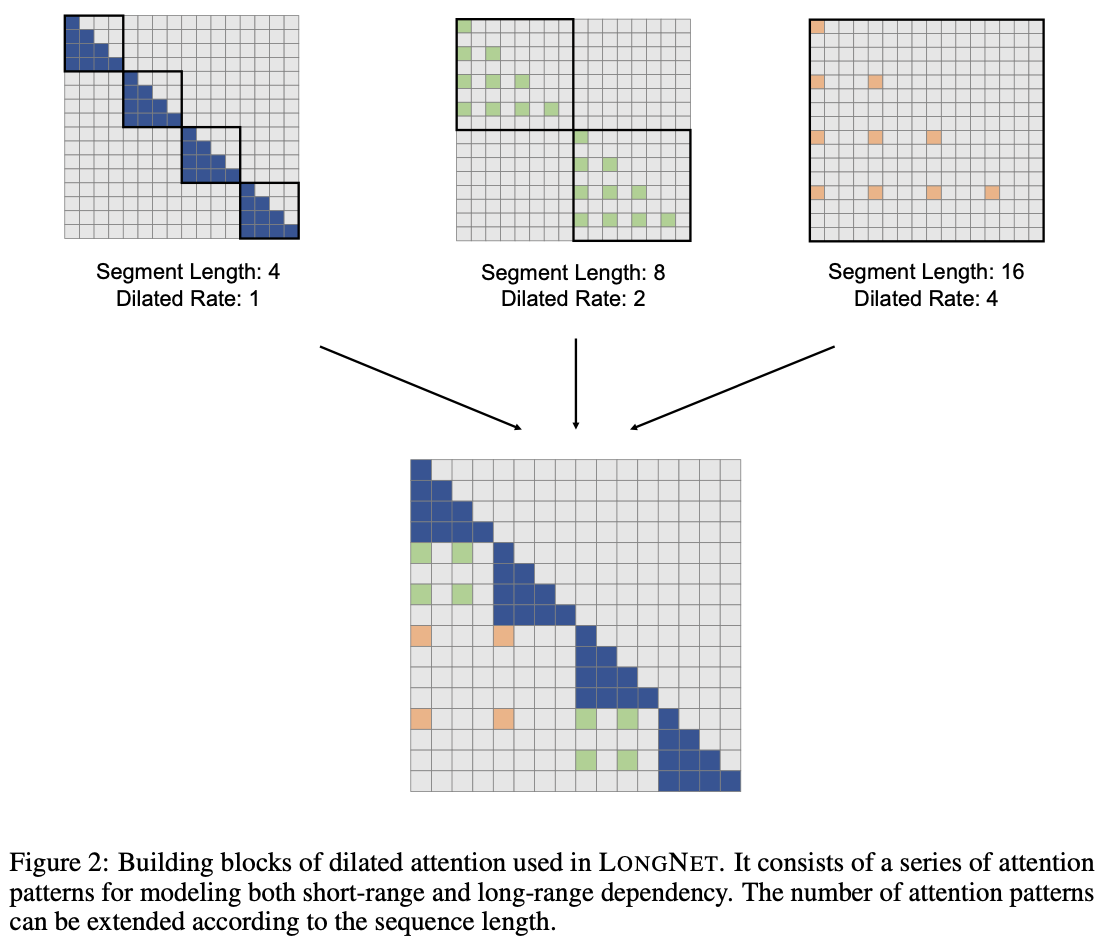
各セグメントは,Figure 2のように,間隔$r$で行を選択し,シーケンス次元に沿ってスパース化されます.実際の計算式は下記で示されます.
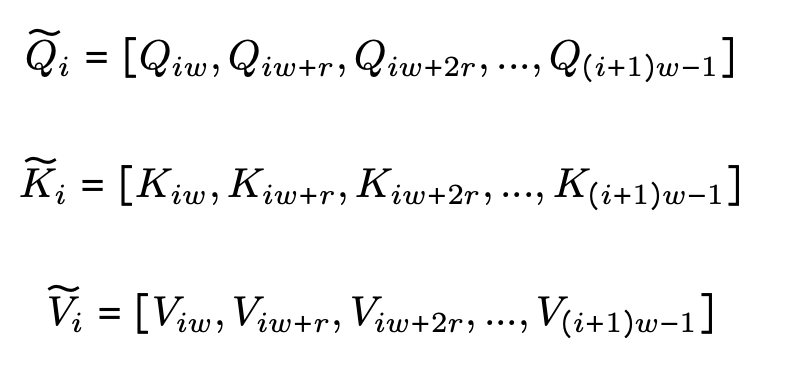 このスパース化されたセグメント${(Q, K, V)}^{\frac{N}{w}}$は,並列にAttentionに供給されます.供給された後に,入力シーケンス長がローカルのシーケンス長より長い場合は,散らばり,計算されて,最後に連結されて出力$O$となります.
このスパース化されたセグメント${(Q, K, V)}^{\frac{N}{w}}$は,並列にAttentionに供給されます.供給された後に,入力シーケンス長がローカルのシーケンス長より長い場合は,散らばり,計算されて,最後に連結されて出力$O$となります.
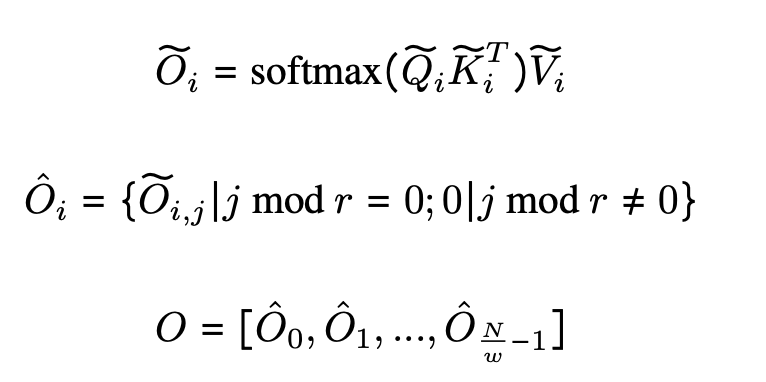
また, 実装においては,入力$(Q, K, V)$に対する収集操作と出力$widetilde{O_i}$に対する操作の間でDilated AttentionはDense Attentionに変換することが出来るので,Flash AttentionなどのVanilla Attentionに対する最適化を直接的に利用することができます.
実際には,セグメントサイズ$w$はAttentionのグローバル性を効率性と引き換えにします.一方で,サイズ$r$はDilated Attention行列に近似することで計算コストを削減します.
LONGNETにおける分散訓練
Dilated Attentionの計算オーダーは,$O(Nd)$へとVanilla Attentionの$O(N^2d)$から大幅に削減されました.しかし,計算資源とメモリの制約により単一のGPU上でシーケンス長を100万オーダーにスケールすることは不可能です.そこで,モデルの並列化処理や,シーケンス処理,パイプライン処理などの大規模モデル訓練用の分散訓練アルゴリズムが提案されています.しかし,LONGNETは特にシーケンの次元が大きく従来の方法では不十分です.そこで,LONGNETは新たに一般性を損なうことなく,複数のデバイスに拡張できる分散アルゴリズムを提案しています.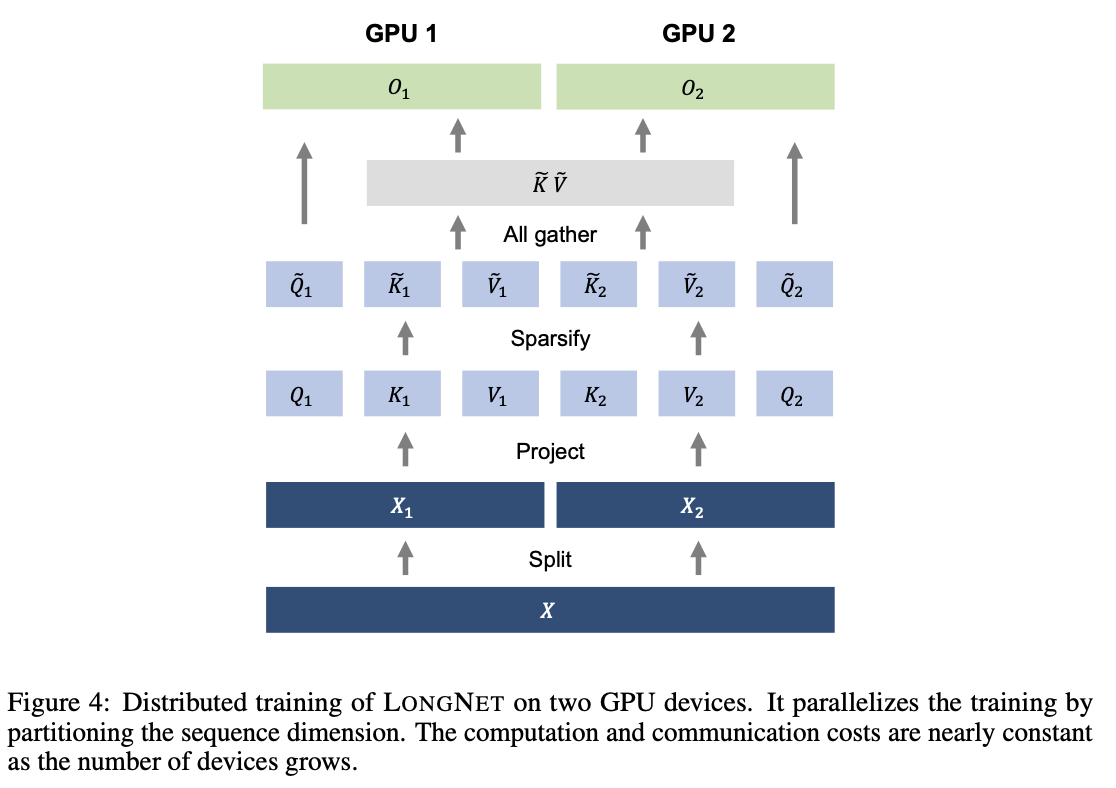
STEP1: 入力シーケンスの分割
入力されたシーケンスはシーケンス次元に沿って分割されます.分割された各シーケンスは別々に1つのデバイス上におかれます.
$X = [X_1 , X_2]$
2つのデバイス上のクエリ,キー,バリューも以下のようになります.
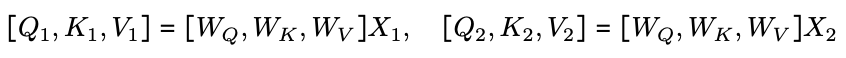
STEP2: Attentionの計算
$w_i \leq l$の時,すなわち,ローカルデバイスのシーケンス長($l$)より入力セグメント長($W_i$)が短い場合は,Dilated Attention紹介した計算方法を使って解散します.
$w_i \geq l$の時,デバイス上にキーとバリューが散らばっている状態なので,Attentionの計算の前にキーとバリューを集めるための全集合演算を実行します.
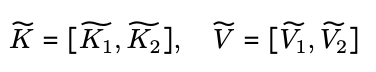
この時に,Vanilla Attentionとは異なり,キーもバリューのサイズはいずれもシーケンス長$N$に依存しないため,通信コストは一定に保たれます.
STEP3: Cross Attentionの計算
ローカルなクエリとグローバルなキーとバリューを使って,Cross Attentionを計算します.
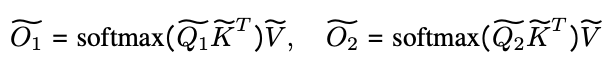
STEP4: 最終的な出力
最終的なAttentionの出力は異なるデバイスかんの出力を連結したものとなり,それは下式で示されます.
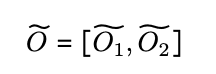
言語モデリングの実験
本論文では,実際に言語モデルへの実装を行なっていて,採用されているアーキテクチャーはMAGNETO[WMH+22]であり,XPOS[SDP+22]の相対位置エンコーディングを用いています.ただ,標準的なAttentionをDilated Attentionに置き換えているようです.
LONGNETをVanilla TransformerとSparse Transformerの両方と比較します.これらのモデルのシーケンス長を2Kから32Kにスケールするにあたって,バッチサイズを調整し,バッチサイズあたりのトークン数を一定に保つように工夫を行っているようです.また,筆者らの計算環境の制約から32Kトークンまでしか実験を行っていないようです.下記は各言語モデルのperplexityの結果です.
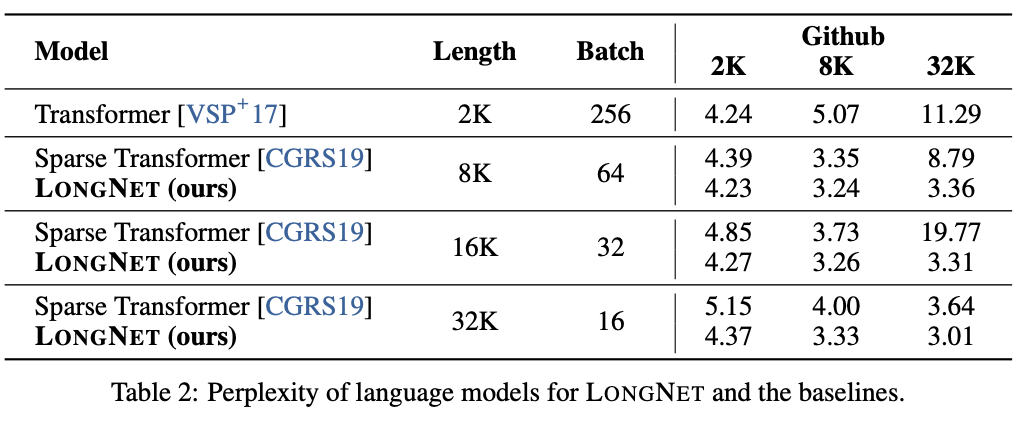
主な結果として,訓練中のシーケンス長を長くすることで,良い言語モデルを得られることが証明されています.LONGNGETは全ての場合に対して他のモデルよりもいい結果を残しており,有効性であることが示されています.
また,下記のFigure 6はVanilla TransformersとLONGNETの両方について,シーケンス長のスケーリング曲線をプロットしたものです.これからもわかるように,LONGNETはスケーリング則に則ることが確認されています.この結果から,Vanilla TransformersとLONGNETでは,LONGNETの方が,効率的にコンテキスト長をスケールアップすることができ,少ない計算量でより高い性能を示すことが出来ると主張しています.
まとめ
筆者らは今後,LONGNETの適用範囲を広げ,多モーダル大規模言語モデリング,BEiTの事前訓練,ゲノムデータモデリングなどのタスクに対応できるように拡張する予定です.これにより,さらに多様なタスクへの対応と優れたパフォーマンスが期待されます.
また,長いプロンプトを受け入れるようになることから,プロンプトでの広範囲または大量の実例などにより,追加学習を必要とせずに,より高度な出力をできるようになる可能性を示唆しています.






この記事に関するカテゴリー





