CapsuleNetを3次元に拡張した「VideoCapsuleNet」。映像認識で大幅な精度改善を可能に
I映像から有益な情報を抽出するということは様々な産業界が共通してAIに期待していることの一つです。しかし実は映像というのは画像と比較して情報量が多く、AIでもこれまであまりうまく扱えていませんでした。今回紹介する論文では、従来のAI(DNN)とはニューロンの設計方法自体が違っていて、映像から人がどこで何をしているかを推論するタスクにおいて大幅な精度向上を達成しました。
本日扱う論文はこちら、VideoCapsuleNet: A Simplified Network for Action Detection (NIPS2018)
目次
(1) 映像処理への期待とその難しさ
(2) VideoCapsuleNet
(3) 実験
(4) まとめ
(1) 映像処理への期待とその難しさ
映像認識への期待とその難しさ

AIの大衆化が進み、特に画像認識の技術は文字認識や医療画像診断、工場での不良品分別、食事画像認識などでとても広く用いられ始めています。
しかし、AIの視覚はもう完璧かというとそうではありません。あげた例では基本的に1枚の画像から情報を抽出して分類したり場所を特定したりするものが多いのですが、一枚の画像だけからではわからないような視覚情報というのはたくさんあります。
例えばライブカメラからの映像を考えてみると、写っている人は歩いてるのか走っているのか、あるいは酔って踊っているかなどというのは一目見てもわかりません。
スポーツであれば、映像を使って演技の美しさを評価したり正しいフォームかをチェックしたりすること、監視カメラを考えてみると視界内に怪しい行動をしている人はいないか見ることなど、映像全体を使わないと正しく抽出できない有益な情報というのはたくさんあります。
しかし映像というのは画像と比較して情報量が多く、被写体が動き回ったり回転したりするせいで、AIでもこれまであまりうまく扱えていませんでした。
今回紹介する論文では、従来のAI(DNN)とはニューロンの設計方法自体が違っていてより空間的な理解に強いとされる『CapsuleNet』を拡張し、映像から人がどこで何をしているかを推論するタスクにおいて従来手法と比較し大幅な精度向上を達成しました。
CapsuleNetを3次元でも扱えるように拡張した VideoCapsuleNet
CapsuleNetとは、1年ほど前にニューラルネットワークの生みの親の一人と言っても過言ではないGeoffrey Hintonらによって提案された、新しいニューロンモデルを持つニューラルネットワークです。
現在大流行しているニューラルネットワークには明らかな欠陥があるとし、それを補正するような形で新しいニューロンモデルが提案されました。
その欠陥というのは『小さい特徴同士の関係性や回転などを捉えるように設計されていない』というものであり、映像認識に欠かせない大事な部分に関わってきていました。少し具体的に、この船のイラストを例にあげてみます。
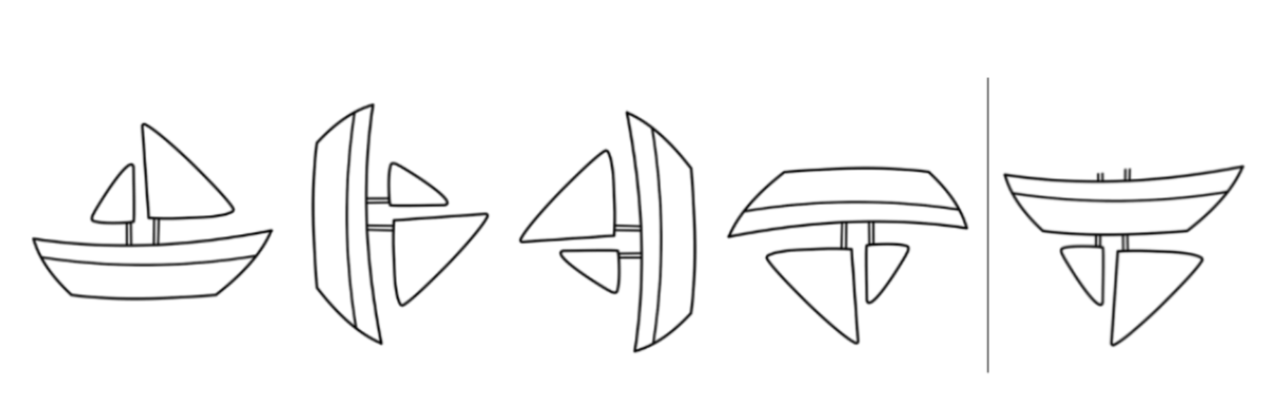
左4つのような、船を様々な角度から撮った画像を見て船の在り方を学習した後に一番右の画像を見たとき、実は従来のニューラルネットでは「帆があって船体があってそれが並んでいるから…これも船!」と騙されてしまう可能性があります。原因はニューラルネットの設計自体にあり、『帆』や『船体』といったそれぞれの特徴を認識したあと、それらの細かい回転などの情報は保存することがなかなかできていませんでした。
そこでCapsuleNetでは、『船体は船体でも、底が下にあるような船体』のように、それぞれの部分的な特徴情報をより正確にニューラルネット内で伝搬できるよう、各ニューロンが0,1のような数ではなくベクトルを扱えるように拡張しています。
このCapsuleNetを映像、つまり縦, 横, 時間の3次元の情報が扱えるように拡張したのが今回の論文の提案手法のVideoCapsuleNetとなります。
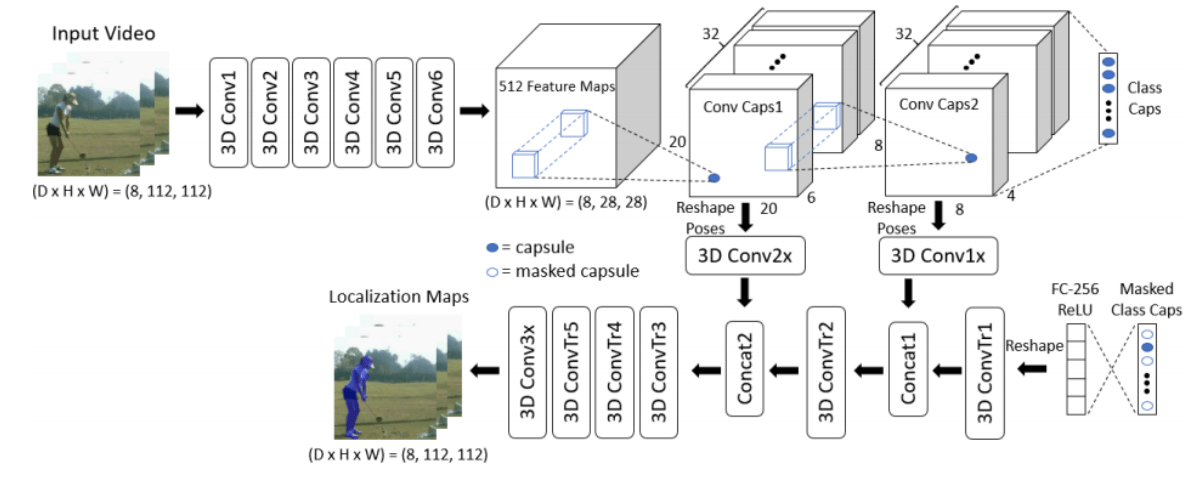
実験
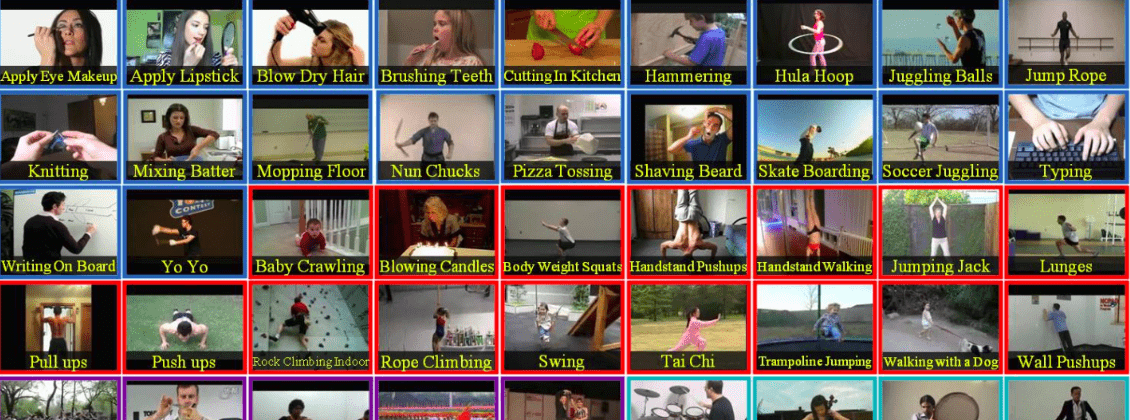
実験では、Sports-1M, UCF-Sports, J-HMDB, UCF-101という4つの映像のデータセットを使っています。これはUCF-101の冒頭36クラスの例ですが、メイク映像, スポーツ, 楽器の演奏など実に様々なジャンルを含んでいます。これらのデータセットを使い、『何をしている映像か』, 『行動主体はどこにあるか』を予想できるよう学習させていきます。
以下がAIが予測した行動主体領域を可視化した結果です。(赤が正解の領域で青が予測領域)かなり正確に予測することができており、特に下側の映像に対して人が斜めに飛んでいる様子に対して正確に追従できている点が見ものです。

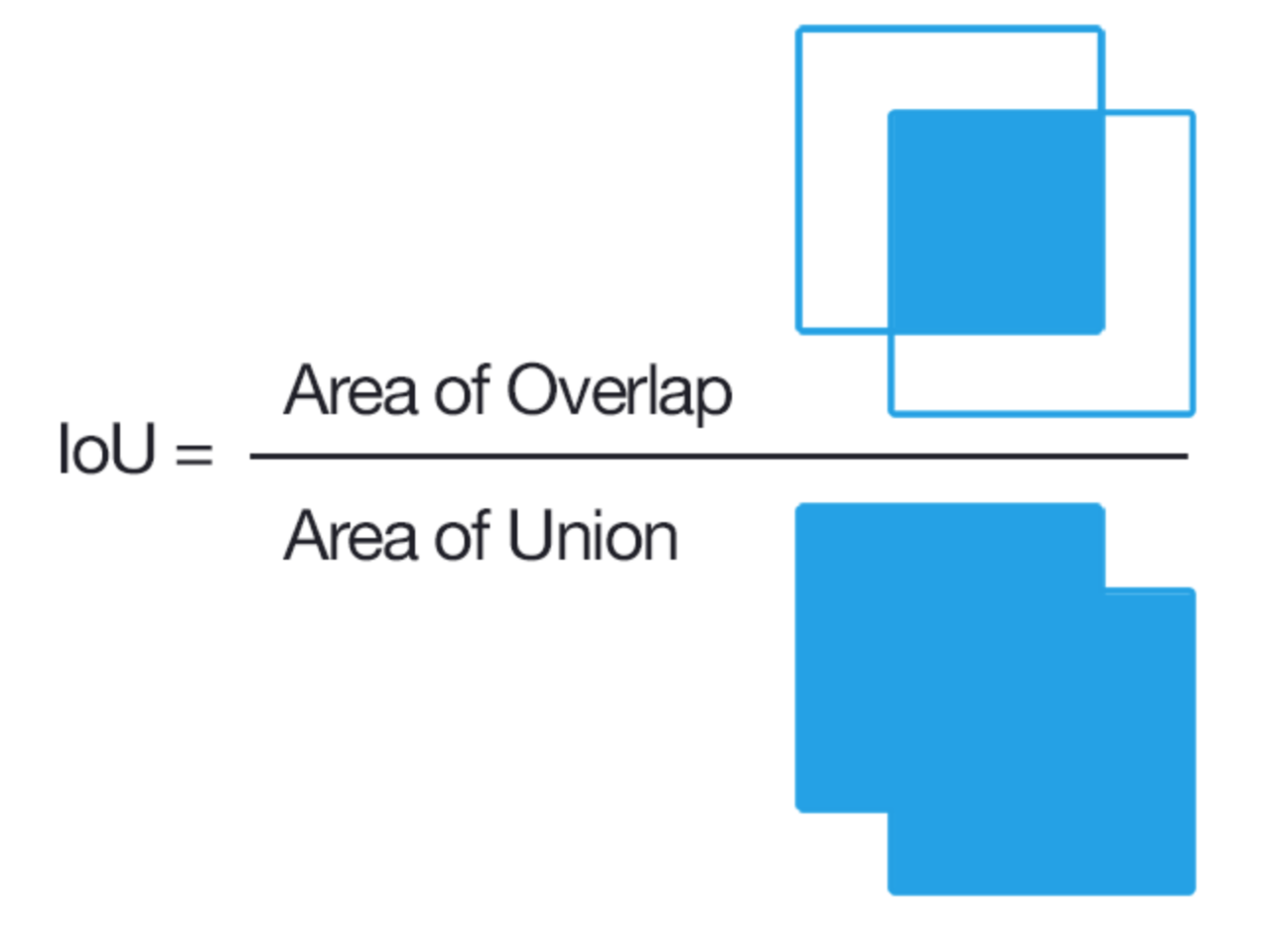
精度はIoUという指標で図られています。(IoU = (赤かつ青の領域)/(赤または青の領域))
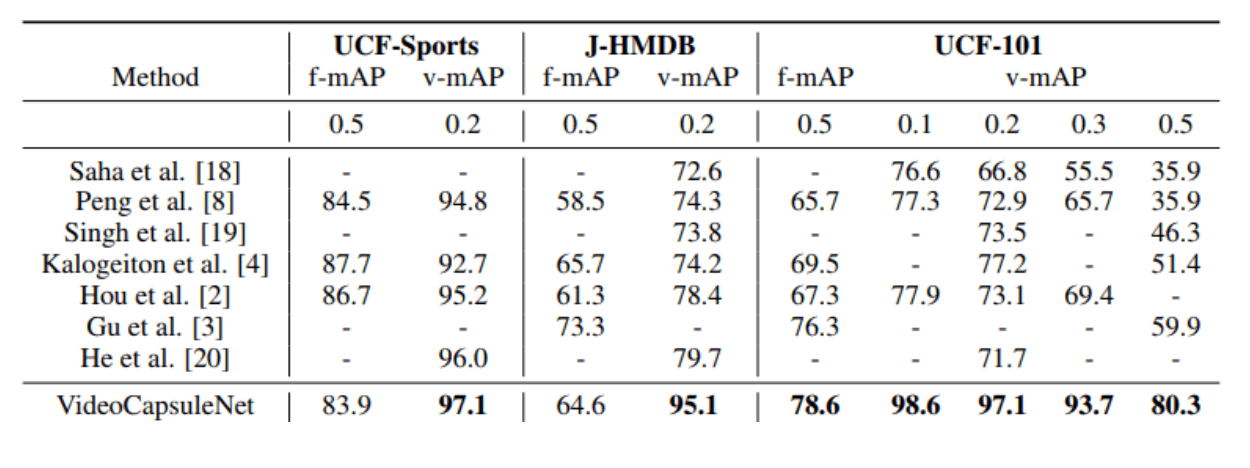
提案手法が圧倒しており、特に一番右のテストでは『IoUが0.5以上のときのみ正しく領域を推定できたと判定する』という難しい条件でも80.3%正解と、既存手法と20ポイント以上の差を付けておりCapsuleNetの凄さが現れています。
ただ、論文では映像のクラス分類の精度について既存手法との比較がなかったため、もしかすると分類については高い精度が出せなかったのかもしれません。
CapsuleNetの新たな可能性
CapsuleNetを拡張したVideoCapsuleNetというモデルを使い、映像認識で大幅な精度改善が見られたという事例を紹介しました。
と、ここまでCapsuleNetの良さを紹介しましたが、実はCapsuleNetは1年ほど前に提案されてから今まであまり使われてきませんでした。
というのも計算時間が桁違いにかかってしまううえ、CapsuleNetを使った結果精度が悪化することもあったためです。
今回の提案手法はCapsuleNetの可能性を再認識させるものとなりました。これから先、様々な分野のAIがCapsuleNet式のものに置き換わったり、またはより良いニューロンモデルはできないかAIの基礎から見直したりといった研究が進んでいく事が期待できます。



この記事に関するカテゴリー






