点群における3Dターゲット検出の新しいフレームワークVoteNet、2つのデータセットで最高精度を更新
3つの要点
✔️ 2D検出器に頼ることなく生データを直接3Dターゲット検出が可能
✔️ 点群ネットワークに古典的なハフ変換に似た投票メカニズムであるVoteNetを提案
✔️ 従来手法の多くを凌駕した
Deep Hough Voting for 3D Object Detection in Point Clouds
written by Charles R. Qi, Or Litany, Kaiming He, Leonidas J. Guibas
(Submitted on 21 Apr 2019 (v1), last revised 22 Aug 2019 (this version, v2))
Comments: Published by ICCV 2019
Subjects: Computer Vision and Pattern Recognition (cs.CV)
はじめに
3Dターゲット検出のための新しいフレームワーク、VoteNetが提案されました。VoteNetは2D検出器に頼ることなく生データを直接処理します。設計が単純で、モデルがコンパクトで効率が高く、実験では2つの実際の3Dスキャンデータセットで最先端の3D検出精度を達成しています。
点群における3D物体検出
3Dオブジェクト検出は、3Dシーン内のオブジェクトの位置を特定して認識することですが、この研究では、点群モデルからオブジェクトのクラスと3Dバウンディングボックスを推定することを目指しています。
3次元データの表現として、点群モデルの他にも 、ピクセルの3Dvoxel、ポリゴンモデル(多角形で形状を近似) など がありますが、その中でも、3D点群は形状と照明の変化に対してロバストです。一方、点群は不規則という欠点もあります。

不規則な点群の処理を回避するために、現在の点群ベースの3D検出方法は、様々な面で2Dベースの検出器に大きく依存しています。
例えば、Faster / Mask R-CNNなどでは2D検出フレームワークを3Dに拡張するか、点群を従来の2D画像に変換してから、2D検出器を適用してオブジェクトを特定します。ただし、これにより重要になる可能性がある幾何学的な詳細が犠牲になります。にも関わらず、点群内の物体を直接検出しようとした研究はほとんどありません。
この研究では、点群データに対する3D検出パイプラインを可能な限り汎用的に構築するのを目的としています。論文では生データを直接処理し、2D検出器に依存しないエンドツーエンドの点群3D検査フレームワークが提案されています。VoteNetと呼ばれるこの検出ネットワークは、PointNet ++とオブジェクト検出のためのハフ変換というプロセスに触発されています。
PointNet ++
ベースとなる基本的なところは点群学習用のディープネットワークであるPointNet ++ と同じです。
PointNetは、2016年に提出された点群分類/セグメント深層学習フレームワークです。点群は、分類または分割の際に不規則な空間的関係を持つという特徴があるため、既存の画像分類・分割フレームワークを点群に直接適用することはできません。したがって、点群の分野では点群ボクセル化(グリッド)に基づく多くのディープラーニングフレームワークが作成されており、高い実績を出しています。
しかし、上記のフレームワークにおける点群データ処理の難しい点として、点群をボクセル化する際に、点群データの空間特性が変化してしまい、不要なデータ損失と処理が発生することが挙げられます。この問題に対して、PointNetは点群の空間特性を最大限残すための独自の点群入力方式を使用しています。
このPointNetを階層化し、細かい空間も表現できるようにしたのがPointNet ++です。
PointNet ++はオブジェクト分類とセマンティックセグメンテーションで成功を収めていますがアーキテクチャで点群の中の3Dオブジェクトを検出する方法を研究している研究はあまりありません。
しかしながら、点群の固有のスパース性はこのアプローチを不利にします。イメージ画像では、物の中心付近にピクセルが存在することがよくありますが、点群の場合はそうではありません。深度センサは物体の表面を捉えるだけなので、3D物体の中心はどの点からも遠く離れた空の空間にある可能性があります。結果として、点群ベースのネットワークは、オブジェクトの近くでシーンコンテキストを集約することが困難です。
本提案
この論文では、点群ネットワーク(PointNet ++)に古典的なハフ変換に似た投票メカニズムを与えることが提案されています。 投票というアイデアを採用することによって、ネットワークは潜在的に低品質の投票を除外し、オブジェクト・センターの近くにある新しいポイントを生成し、それをグループ化して集約することにより提案を生成することができます。
いかなる点をとっても、その点を通る直線は無限個存在し、それぞれが様々な方向を向くというのが、ハフ変換の基本原理です。ハフ変換の目的は、それらの直線の中で、画像の「特徴点」を最も多く通るものを多数決で決定することです。その画像に最もよく合った直線を探すことを目的とします。
本提案VoteNetは、同時最適化が難しい従来のハフ変換と比較して、エンドツーエンドで最適化されています。
具体的には、入力ポイントクラウドをバックボーンポイントクラウドネットワークに通過させた後、一連のシードポイントをサンプリングし、それらの特性に基づいて投票を生成します。投票の目的は、ターゲットセンターに点群を到達させることです(下図)。したがって、投票クラスタはターゲットセンターの近くに表示され、学習モジュールを介して集約されます。その結果、純粋に幾何学的で、点群に直接適用できる強力な3Dオブジェクト検出器が得られます。

以下の図2は、提案されているVoteNetのアーキテクチャが示されています。前半は既存の点群ポイントを処理して投票を生成するもの、後半は仮想ポイントを処理して投票を集約し、オブジェクトを分類するためのものです。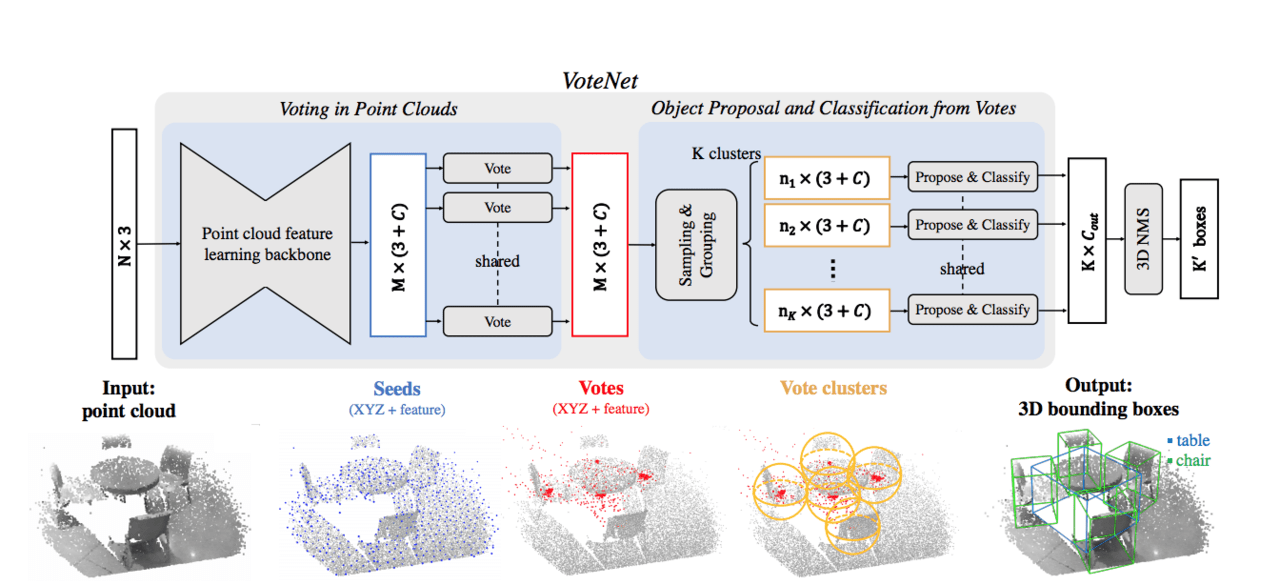
図2
XYZ座標を持つN点の入力点群が与えられると、バックボーンネットワーク は点の深い特徴をサブサンプリングして学習し、M点のサブセットを出力し、さらにC点の特徴によって拡張します。この点のサブセットはシード点と見なされます。各シードは個別に投票モジュールを介して投票を生成します(図3)。
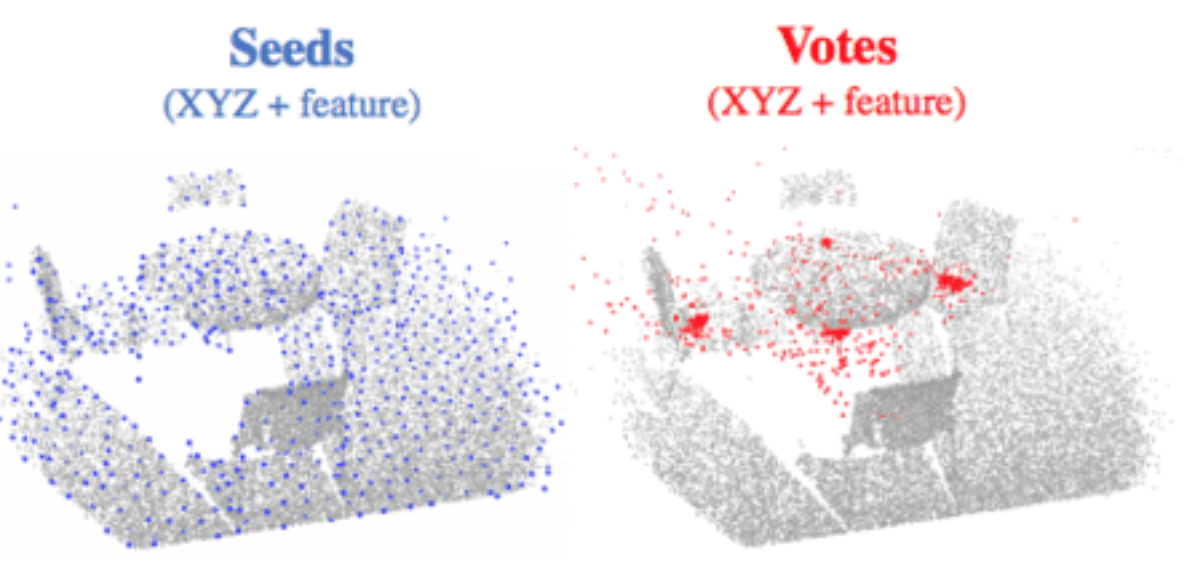
図3
その後、投票はクラスタにまとめられ、最終提案を生成するために提案モジュールによって処理されます。分類された提案が、最終的な3Dバウンディングボックスの出力になります(図4)。
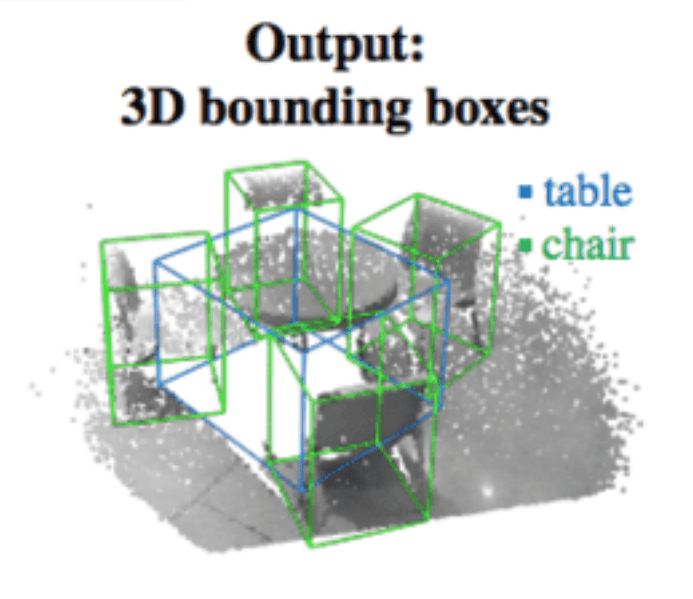
図4
結果
まず、今回の手法VoteNetと2つの大型3D屋内ターゲット検出ベンチマークの最も先進的な方法とを比較しました。
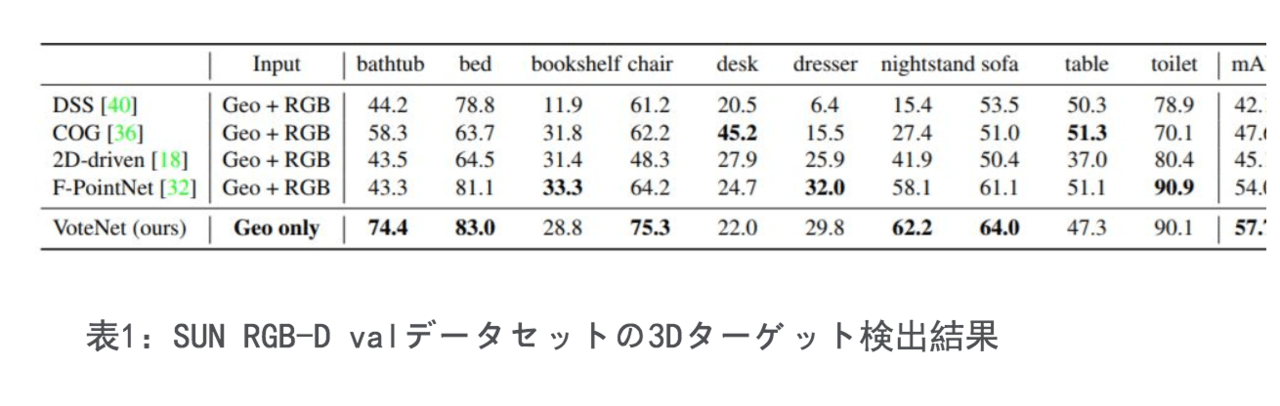
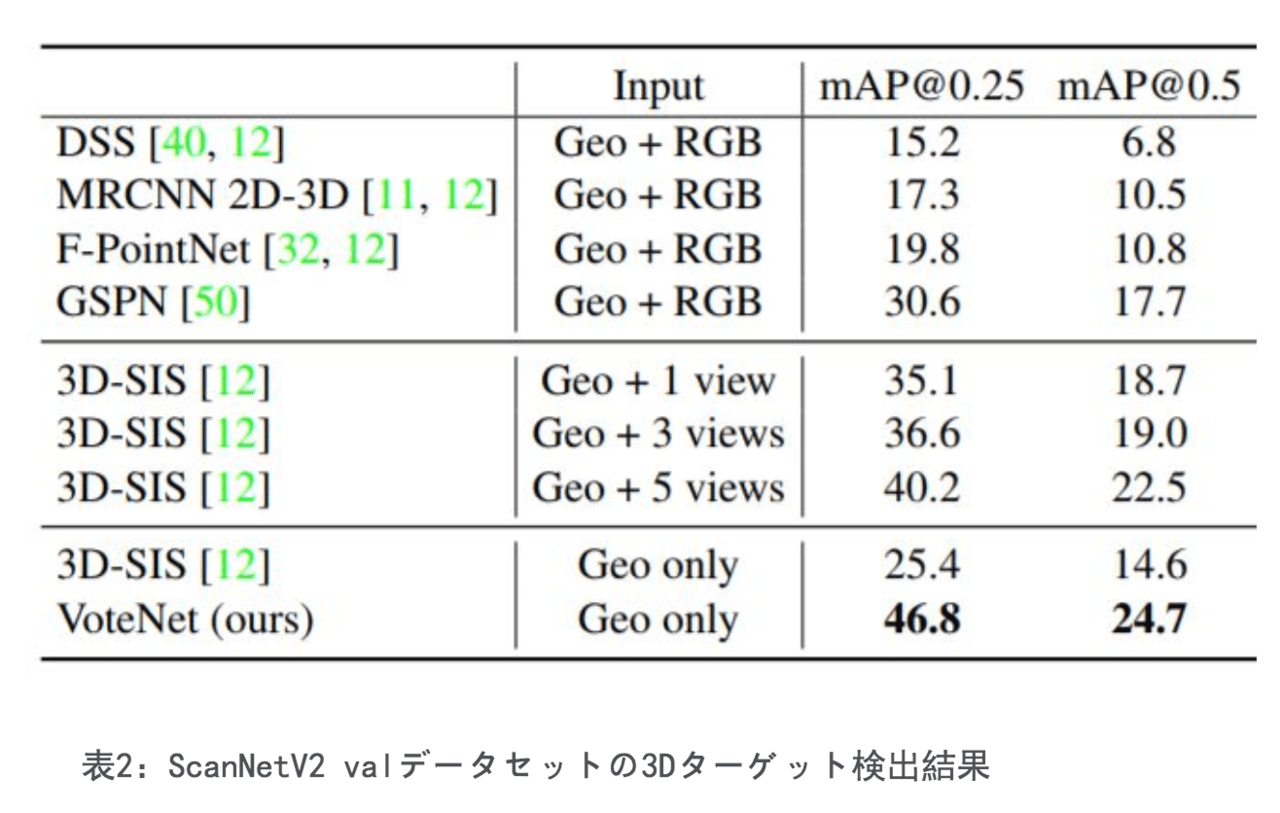
SUN RGB-DおよびScanNetデータセットでの、VoteNetのパフォーマンスは、それぞれ3.7および6.5 mAPの増加で、以前のすべての方法よりも優れています。
次に、投票の重要性、さまざまな投票集計方法の効果の観点からのこのアプローチの利点を理解するための分析実験を行いました。ここではBoxNetと呼ばれる単純なベースラインネットワークと比較しています。これは投票なしでサンプリングされたシーンポイントから直接検出するものです。

図からわかるように、BoxNet(左)と比較して、本提案VoteNet(右)は広範囲の「良い」シードポイントを網羅しており、投票の堅牢性を示しています。
まばらな3D点群では、既存のシーンの点がターゲットの中心点から離れている傾向があるため、直接提案された方式では信頼性が低くなったり不正確になる可能性があります。投票することでこれらの信頼性の低い点を互いに近づけることができ、集約によってそれらを増やすことができます。
ハフ変換とディープラーニングの相乗効果は、6Dポーズ推定、テンプレートベースの検出などのより多くのアプリケーションに一般化できると考えられており、この分野に沿った今後のさらなる研究が期待されます。
 AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
AI(人工知能)への注目度は、年々高まっています。そのため一部企業では、日本ディープラーニング協会の主催する「G検定」「E資格」の社内合格者を公開して、自社のAIに関する知見をアピールする動きも出てきています。
そう言った人材がいることもAI開発のある意味1つの実績になります。
AI-SCHOLARを読んでいる読者は、今こそE資格を取得し、早めに自分のスキルアップを狙っていきましょう!
企業においてはある調査で、AI開発に成功している企業は社員全体のAIに対する知識レベルが高いそうです。
AI開発やAIを用いる社会になる今こそ企業は社員のAIレベルをあげましょう!



この記事に関するカテゴリー






