破局的忘却は何が原因か?
3つの要点
✔️ 破局的忘却のメカニズムについての研究
✔️ ニューラルネットワークの深い層が破局的忘却に影響することを発見
✔️ タスク間の類似度と破局的忘却の関係を発見
Anatomy of Catastrophic Forgetting: Hidden Representations and Task Semantics
written by Vinay V. Ramasesh, Ethan Dyer, Maithra Raghu
(Submitted on 14 Jul 2020)
Comments: Accepted to ICLR2021.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV); Machine Learning (stat.ML)

code:
dataset:

はじめに
学習済みのモデルをさらに学習させたとき、既存タスクに対する性能が大きく低下する破局的忘却(catastrophic forgetting)は、深層学習モデルにおける大きな課題となっています。
本記事で紹介する論文では、ニューラルネットワークの表現や、破局的忘却を抑止する様々な手法を調査し、破局的忘却が出力に近い層で引き起こされていることを発見しました。また、実行される複数のタスク間の類似性と、破局的忘却との関係性についても調査しています。
実験
破局的忘却に関する調査として、様々なタスク・モデルアーキテクチャを用いて実験を行います。
タスク
実験では、以下に示すタスクが利用されます。実験では複数のタスクを逐次学習させていくため、それぞれ複数(二つ)のタスクから構成されています。
- Split CIFAR-10:10クラスのデータセットを5クラスずつ分割し、2つのタスクに分割したものを利用します。
- Input distribution shift CIFAR-100:CIFAR-100の上位クラスを区別するタスクですが、入力データは同じ上位クラス内の異なる分布集合であり、分布シフトが生じています。
- CelebA属性予測:2つのタスクの入力データは男性か女性のどちらかで、笑顔か口が開いているかのどちらかを予測します。
- ImageNet上位クラス予測:前述したCIFAR100と同様のタスクです。
モデル
画像分類タスクに用いられる、以下に示す三つの一般的なアーキテクチャが利用されます。
これらのモデルに二つのタスクを順番に学習させた場合の破局的忘却の例は以下のようになります。

前述したタスクのうち、split CIFAR10/input distribution shift CIFAR-100が実験に用いられています。
タスク1の学習終了後にタスク2を学習させたとき、タスク1の性能が著しく低下していることがわかります。
破局的忘却と隠れ層の表現
はじめに、ニューラルネットワーク内の隠れ層における特徴表現と、破局的忘却との関係性について調査します。これは、以下のような質問に答えることを目標としています。
- ネットワーク内の全てのパラメータや層が同様に破局的忘却の原因となるのか?
- ネットワーク内の特定のパラメータや層が破局的忘却の主要因となるのか?
以下に説明する一連の実験の結果として、破局的忘却の原因は出力に最も近い層(上位層)にあることがわかりました。
・特定層の凍結
ネットワーク内の特定の層が忘却に及ぼす影響を調べるため、特定の層の重みを凍結する(freeze:パラメータを更新せず固定する)実験を行います。具体的には、タスク1で学習した後、最下層(入力に最も近い層)から特定の層までを凍結し、残りの層のみをタスク2で学習させます。
実験の結果は以下の通りです。

横軸の数字が大きいほど、より出力に近い層(上位層)までの重みが凍結されています。この図から分かる通り、下位層の重みが固定されても、タスク2に対する精度はあまり低下しません。
このことから、下位層の特徴表現はタスク1・2の間で更新せずに再利用することができ、上位層が破局的忘却の主な原因となっていると予想されます。
・層を凍結しなかった場合
前述した通り、下位層の特徴表現は、タスク1・2の間で再利用することができます(下位層の特徴表現をそのまま用いても、上位層の更新のみで良好な性能を発揮できます)。
では、層の重みを凍結せずに通常の学習を行った場合でも、下位層の特徴表現は大きく変化しないのでしょうか?これを調べるため、ニューラルネットワーク表現の類似性を測定する手法であるCKA(Centered Kernel Alignment)を利用します。CKAは、二つの層の表現がどれだけ類似しているかを0~1のスカラー値で示します。
具体的には、($n$個の)データポイントと($p$個の)ニューロンからなる層活性化行列$X \in R^{n×p},Y \in R^{n×p}$について、CKAは以下のように求められます。
$CKA(X,Y)=\frac{HSIC(XX^T, YY^T)}{\sqrt{HSIC(XX^T, XX^T)}\sqrt{HSIC(YY^T, YY^T)}}$
HSICはHilbert-Schmidt Independence Criterionを表します。
以下の図にて、タスク2の学習前後にてCKAにより求めた、層表現間の類似度を表しています。
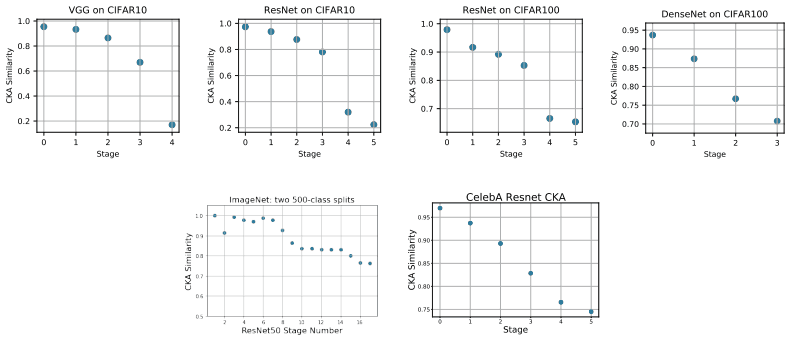
図の通り、タスク2の学習前後での下位層の類似性は高く、上位層の類似性は著しく低くなっていることがわかります。
・層のリセット
さらに、上位層が破局的忘却に大きな影響を及ぼしていることを明らかにするために追加の実験を行います。具体的には、タスク1・2を逐次学習させた後、最下層または最上層から連続で$N$個の層を、タスク2を学習させる前(タスク1の学習が終了した直後)の状態に巻き戻します。
このときの結果は以下の図で示されています。
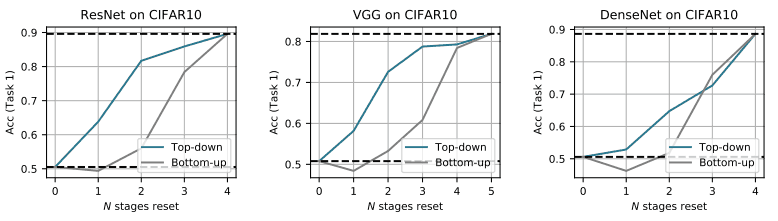
Top-downは最上層(出力に近い側)からN個の層を、Bottom-upは最下層からN個の層をリセットした場合の性能を示しています。総じて、最上層付近の層をリセットすることで、最下層付近の層をリセットする場合と比べて高い性能が得られています。
これは、上位層が破局的忘却に強く影響していることを示しています。
・特徴表現の再利用と部分空間の消去
タスクの逐次学習時の表現の変化について、部分空間類似度(subspace similarity)の分析を行うことでさらなる調査を行います。
部分空間類似度、$X \in R^{n×p}$のPCA(主成分分析)を行い、第一主成分から第$k$主成分までを列とする行列$V_k$と、$Y \in R^{n×p}$に対して同様にして求めた$U_k$を用いて、以下のように計算されます。
$SubspaceSim_k(X,Y)=\frac{1}{k}||V^T_kU_k||^2_F$
ここで、部分空間類似度を以下の三つの条件についてそれぞれ求めます。
- (1)X:タスク1を学習したモデル、Y:タスク2を学習したモデル
- (2)X:タスク1を学習したモデル、Y:タスク1→タスク2の順に逐次学習したモデル
- (3)X:タスク2を学習したモデル、Y:タスク1→タスク2の順に逐次学習したモデル
このときの部分空間類似度は以下の図の通りです。
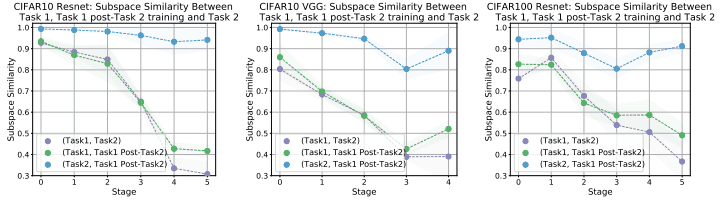
タスク2の学習前後の比較である(2:緑色で記載)から分かる通り、タスク2の学習前後で上位層の類似度が著しく低下しており、部分空間が大きく変化していることがわかります。
CKAを用いた分析と同様、下位層表現はタスク1・2間であまり変化しないものの、上位層表現は大きく変化していることがわかります。
・忘却緩和手法と特徴表現
ここまでの実験で、破局的忘却が主に上位層の影響により生じていることがわかりました。
では、破局的忘却を抑止する(継続学習)手法を用いた場合、上位層にはどのように変化が起きるでしょうか?
実際に、リプレイバッファを用いる手法、EWC(Elastic Weight Consolidation)、SI(Synaptic Intelligence)などの手法を用いた場合の部分空間類似度について以下に示します。
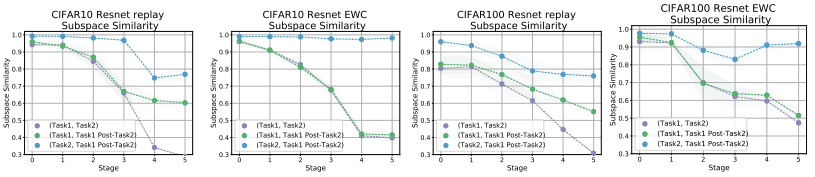
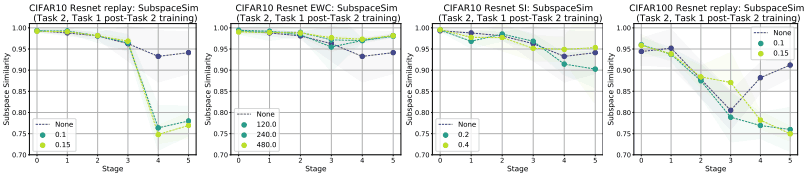
上段は様々な緩和手法を用いた場合について、下段は緩和手法の強度を変化した場合(Task2, Task1 Post-Task2)について示されています。
リプレイ法ではタスク2の学習時にタスク1のデータを利用するため、(Task2, Task1 Post-Task2)の上位層での類似度が低下している一方、EWC/SIでは類似度は高いまま維持されています。これは、EWC/SCが特徴表現の再利用を促すのに対し、リプレイ法は直交する部分空間を利用していることを示唆しているとみられます。
また、CKA値の比較は以下のようになります。
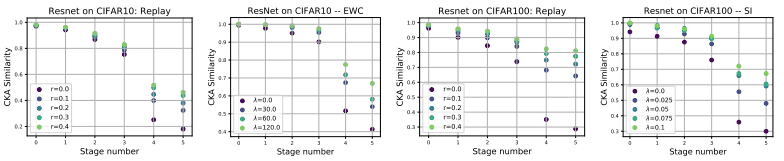
この図では、先述した三つの緩和手法を異なる強度($r$または$\lambda$)で適用した場合のCKA値が示されています。
図から分かる通り、緩和手法を強く適用するほど、特に上位層の類似度が向上している(上位層の変化が抑えられている)ことがわかります。
ただし、上位層の類似度の向上が、上位層での特徴表現の再利用によるものなのか、タスク1・2の表現をそれぞれ直交する部分空間に保存しているからなのかは未解決の疑問となります。
・タスク間類似度と破局的忘却の関係
これまでの実験では、破局的忘却とネットワーク内の特徴表現の関係について調査しました。以降は、連続したタスク間の関係が、破局的忘却に及ぼす影響について調査します。
これは、以下のような質問に答えることを目標としています。
- タスク間の類似度が高いほど、破局的忘却は減少するでしょうか?
この問いに答えるため、タスク間の類似度と破局的忘却の関係について実験した結果は以下のようになります。
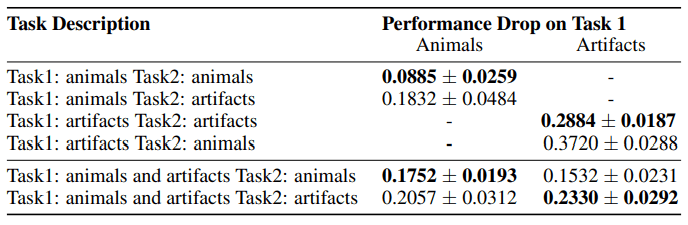
この表では、ImageNetを用いて、Task1・Task2を人工物と動物のクラスから構成した場合の性能低下を示しています。
例えばTask1: animals Task2: animalsでは、10種類の動物画像分類タスク(Task1)の学習後、それとは異なる10種類の動物画像分類タスク(Task2)を実行します。
もしタスク間の類似度が破局的忘却を和らげると仮定するならば、二つのタスクが類似している(animals-animalsまたはartifacts-artifacts)時ほど、性能の低下は少ないはずだと予想できます。しかし実際には、Task1:artifacts Task2:artifactsの場合で大きな性能低下が生じている等、先述した仮定とは反しています。同様に、物体または動物をもとに構成されたタスクで実験を行った場合の学習曲線を以下に示します。
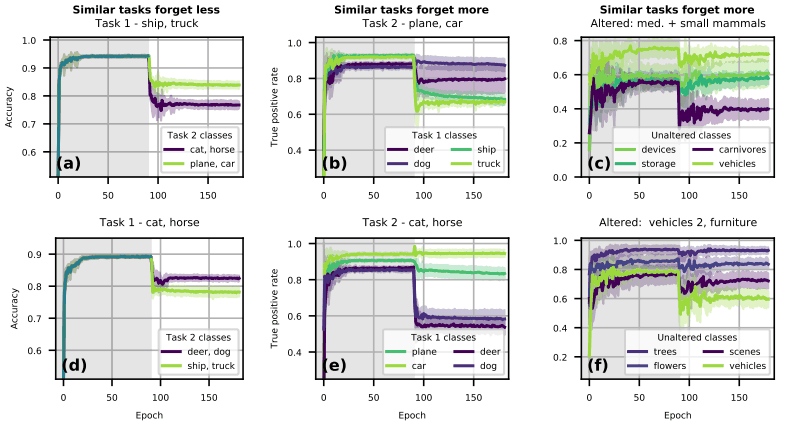
例えば図の(a)では、Task 1にはshipとtruckクラスが含まれています。このとき、二種類のTask2(cat,horseまたはplane,car)をもとに実験すると、Task1と同じ物体(plane,car)で学習したの場合の方が性能は高くなっています。
つまり、類似したタスクを学習させた場合に、破局的忘却が弱まっています。これは(d)でも同様の結果となっています。
一方(b)では、Task1で物体・動物それぞれ2クラスずつ(ship,truck,deer,dog)学習させ、その後に物体(plane,car)を学習させると、同じく物体であるship,truckに対する精度が悪化しています。
つまり、類似したタスクを学習させたことで、むしろ破局的忘却が深刻となっています。これは(e)でも同様の結果となります。
CIFAR-100で実験が行われた(c,f)でも同様で、入力分布が変更されたクラス(Altered)と類似したクラス(分布のシフトはなし:Unaltered)に対する性能が低下しています。このように、タスクが類似している場合、性能が向上する時も低下する時も存在することがわかりました。
では、タスク間の関係と破局的忘却との関係はどのようなものとなっているのでしょうか?過程の詳細は省きますが、論文ではタスク間の類似度を測定する指標を定義し検証した結果、類似度が中程度である場合に破局的忘却が最も強くなることを示しました。
これは以下の図の通りです。
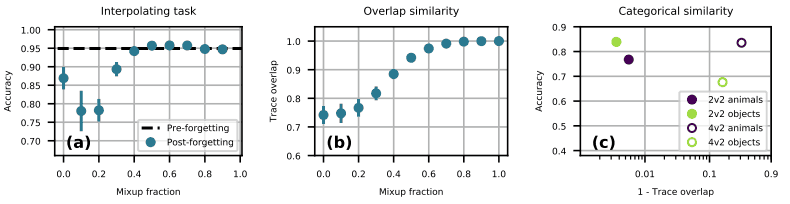
図(a)では、まず二値分類タスクを学習させた後、他のタスクとデータセットを一定の割合(Mixup fraction)で混合したデータセットで学習させた時の精度を示しています。
図の通り、混合率が0.1~0.2の場合において、特に性能の低下がみられたことが示されています。
図(b)は、二つのデータの混合率に対するタスクの類似度(Trace overlap)を示しており、混合率に応じてタスク類似度が単調に変化していることが示されています。
図(c)では、先述した(a~fからなる)タスクにおける、Task1・2間の類似度を示しています。ここで、●は図の(a)に、○は図の(b)に対応しています。
実際の結果としては、黄緑・紫の●では黄緑が、黄緑・紫の○では黄緑色が、もう一方の色と比べて低い性能となっています。
この理由は以下のように説明できます。
- 黄緑・紫の●で比較すると、タスク間類似度が低い紫色の方が精度は低下します
- 黄緑・紫の○で比較すると、黄緑の○の類似度が中程度となるため、黄緑色の方が精度は低下します。
このように、タスクの類似度が中程度である時に最も破局的忘却が低下するという知見に基づくと、先ほどの(a~fからなる)タスクの結果を説明することができます。
まとめ
本記事で紹介した論文では、破局的忘却の発生メカニズムや、ニューラルネットワークの表現、継続学習手法、タスクとの関連性について調査がなされ、大きく以下の二つの知見が得られました。
- 破局的忘却は上位層(出力に近い層)が大きく寄与しています。
- タスク間類似度が(論文内で定義された指標に基づいて)中程度の場合に、最も破局的忘却が強くなります。
これらの結果は、破局的忘却の直接的な解決策ではないものの、破局的忘却を抑止する手法の研究にとって非常な有意義な知恵を提供するものであると言えるでしょう。





この記事に関するカテゴリー






